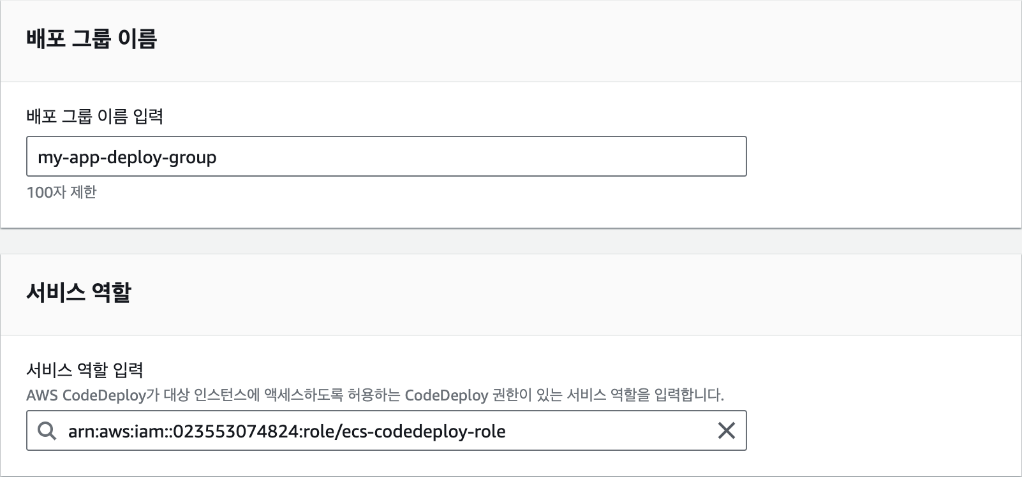
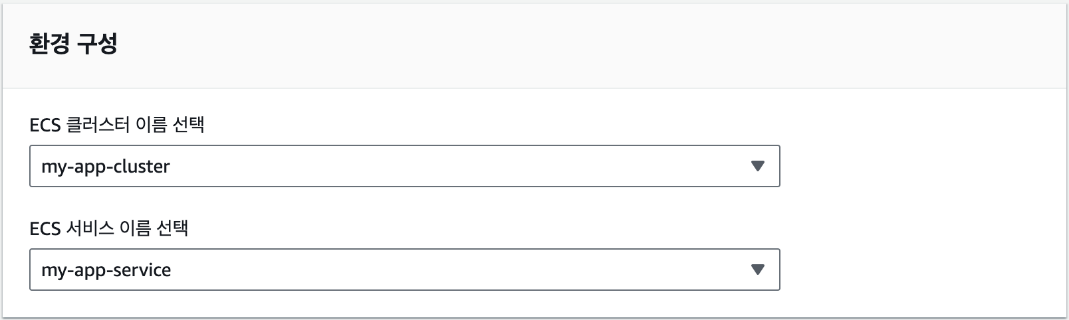
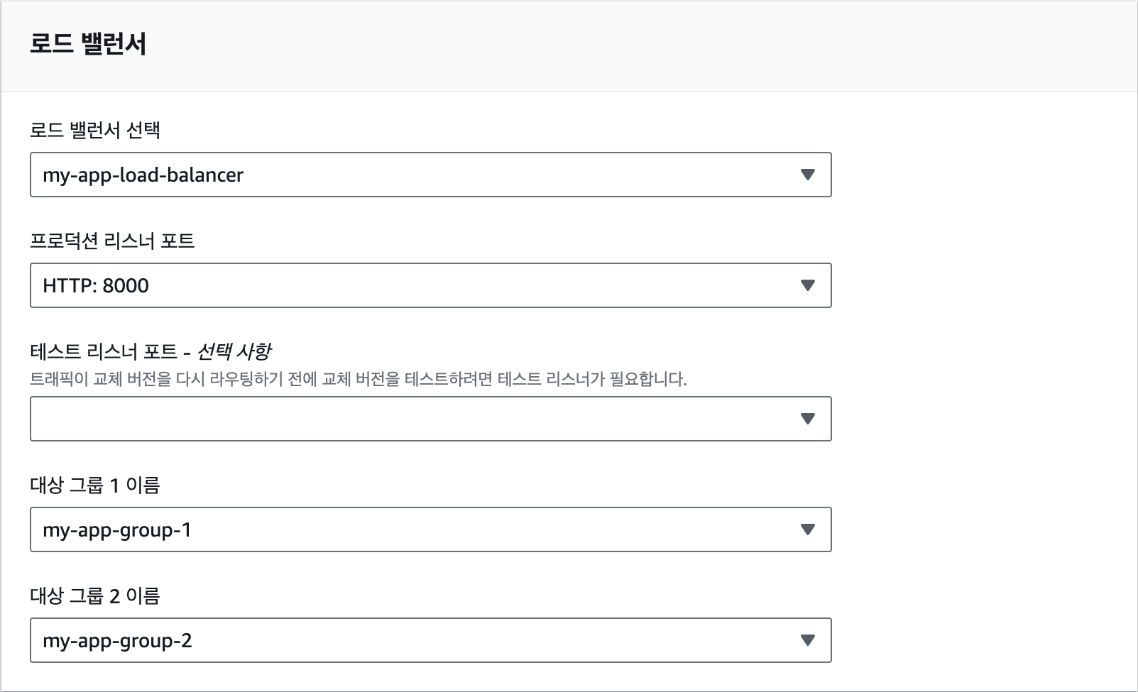
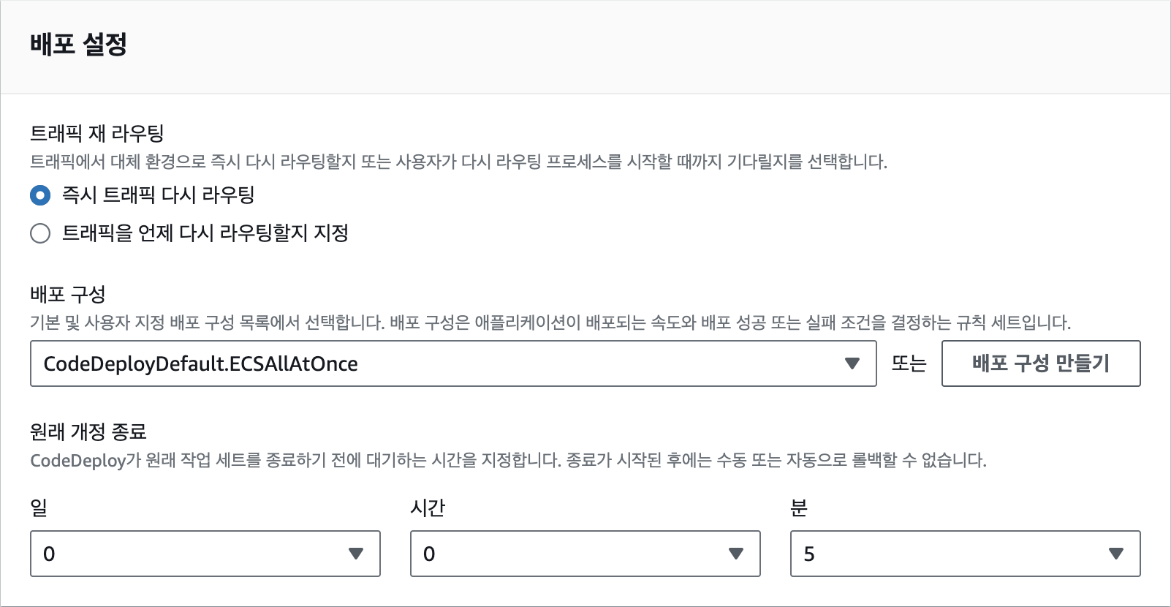
1장 클라우드의 기초
1장에서는 클라우드 컴퓨팅의 기본 개념을 학습합니다. 클라우드 서비스가 왜 필요한지, 그리고 AWS가 어떤 역할을 하는지에 대해 살펴볼 것입니다. 이어서 AWS 프리 티어를 활용해 클라우드 서비스를 경험하고, 비용을 효율적으로 관리하는 방법을 제시합니다.
또한, 클라우드 환경에서 널리 사용되는 도커와 리눅스 운영체제에 대한 기본적인 내용도 함께 다루어 클라우드 환경에서 개발하는 데 필요한 기초적인 역량을 배울 수 있습니다.
서문
AWS, 클라우드 시대의 필수 도구
클라우드 컴퓨팅 시대가 도래하면서 AWS는 개발자들에게 없어서는 안 될 필수적인 도구가 되었습니다. 하지만 방대한 서비스 종류와 복잡한 설정은 초심자, 특히 주니어 개발자들에게 높은 진입 장벽으로 작용합니다. 저 또한 처음 AWS를 접했을 때 엄청난 양의 정보와 다양한 서비스에 압도되었던 기억이 있습니다. 특히, 애플리케이션을 배포하고 관리하는 과정은 더욱 복잡하게 느껴졌습니다.
주니어 개발자를 위한 친절한 안내서
이 책은 AWS를 처음 접하는 주니어 개발자들을 위해 쓰여졌습니다. AWS의 기본적인 개념부터 시작해 실제 애플리케이션을 배포하고 관리하는 과정까지, 단계별로 친절하게 설명합니다. 복잡한 이론보다는 실제 개발 환경에서 자주 사용되는 서비스와 기능에 초점을 맞추어, 독자들이 쉽고 빠르게 AWS를 활용할 수 있도록 돕습니다.
핵심 서비스 중심의 학습
AWS는 수많은 서비스를 제공하지만, 모든 서비스를 처음부터 익히기는 어렵습니다. 이 책에서는 애플리케이션 배포에 필수적인 핵심 서비스들을 중심으로 학습합니다. EC2, S3, RDS 등과 같은 주요 서비스를 활용해 간단한 웹 애플리케이션부터 복잡한 시스템까지 구축하는 방법을 상세하게 다룹니다.
실습을 통한 학습 효과 극대화
이론적인 설명과 함께 다양한 실습 예제를 제공해 독자들이 직접 AWS 환경에서 코드를 작성하고 결과를 확인할 수 있도록 합니다. 실습을 통해 이론을 몸으로 익히고, AWS 서비스를 활용하는 노하우를 쌓을 수 있습니다.
끊임없이 변화하는 AWS와 함께 성장하기
AWS는 지속적으로 새로운 서비스와 기능을 출시하며 빠르게 변화하고 있습니다. 이 책은 최신 버전의 AWS를 기반으로 작성되었지만, AWS의 핵심적인 개념과 원리를 이해한다면 새로운 기능에도 빠르게 적응할 수 있을 것입니다. 이 책을 통해 AWS를 익히고, 끊임없이 변화하는 클라우드 환경에서 자신감 있게 개발을 이어나가시기 바랍니다.
[1] 클라우드 서비스의 필요성
몇 년 전까지만 하더라도 웹 서비스를 만들기 위해서는 서버를 구매하고, 서버를 물리적으로 구축해야 했습니다. '물리적으로 구축한다'는 말은 사무실이나 가정에서 서버용 컴퓨터를 구매해 설치하고, 컴퓨터에 운영 체제와 함께 필요한 프로그램 등을 세팅하는 것을 의미합니다. 그리고 서버를 구축하고 나면, 이제는 서버를 관리하기 위한 인력이 필요합니다. 서버 관리가 필요한 이유는 정말 다양합니다. 가장 심각한 경우는 서버 컴퓨터 자체가 고장나거나 서버가 위치한 장소에서 화재가 발생하는 상황 등이 있습니다. 이외에도 서버의 성능을 높이기 위해 하드웨어를 업그레이드하거나 서버의 운영 체제 또는 프로그램의 버전을 업그레이드해야 하는 경우도 있습니다. 특히, 소프트웨어 개발 과정에서 서버에 설치된 프로그램을 자주 업데이트하게 되는데, 이럴 때마다 운영 체제와의 충돌 또는 다른 라이브러리나 프로그램과의 충돌 때문에 업그레이드 과정에서 많은 시간이 소요되는 경우가 많습니다.
물리적인 서버의 가장 결정적인 문제는 바로 서비스를 운영하는 데 필요한 컴퓨팅 자원을 예측하고, 그에 맞는 서버를 구성하기가 어렵다는 점입니다. 예를 들어, 서비스 초기에는 보통 성능의 서버 컴퓨터 1대로도 서비스를 원활하게 운영할 수 있었지만 서비스가 발전하고 고객이 늘어나면서 서버를 증설해야 하는 경우가 발생합니다. 하지만 필요한 서버의 성능을 정확히 예측하기 힘들고 때로는 구축한 서버의 성능보다 적은 규모의 연산량만 필요하게 되어서 자원을 낭비하게 되기도 합니다. 결론적으로 물리적인 서버를 사용해 웹 서비스를 만들기 위해서는 많은 비용과 시간, 그리고 노력이 필요합니다.
이런 문제를 해결하기 위해 등장한 것이 클라우드 서비스입니다. 클라우드 서비스는 물리적인 서버를 구매하고 설치하는 과정을 생략하고, 인터넷을 통해 가상의 컴퓨터, 즉 가상 서버를 대여하는 방식입니다. 몇 번의 클릭만으로 전 세계 어디에든 서버를 바로 구축할 수 있고, 언제든 서버를 늘리고 줄일 수 있어 웹 서비스 개발자들에게 큰 인기를 얻고 있습니다. 이처럼 가상의 서버를 제공하는 업체를 클라우드 서비스 제공 업체라고 합니다. 클라우드를 이용하면 서버를 구매하고 설치하는 과정을 생략할 수 있고, 가상 서버들이 동작하는 실제 물리적 서버의 관리는 클라우드 서비스 제공 업체에서 전담하기 때문에 비용과 시간을 절약할 수 있습니다. 이러한 장점 때문에 많은 기업에서 클라우드 서비스를 사용하고 있습니다.
[2] AWS의 활용과 중요성
클라우드 서비스 제공 업체는 여러 곳이 있습니다. 국내에서는 KT, 네이버, 카카오 등의 업체에서 데이터센터를 구축하고, 다양한 서비스를 제공하고 있습니다. 해외 업체로는 구글, 마이크로소프트, 아마존 등이 있습니다. 전 세계 클라우드 시장 점유율은 2021년 기준 아마존 32%, 마이크로소프트 22%, 구글 11%로 아마존이 가장 인기가 높고, 국내 클라우드 시장 점유율 역시 아마존 62%, 마이크로소프트 12%, 네이버 7% 등으로 아마존이 압도적으로 많이 사용되고 있습니다. 따라서 국내 회사에 취업했을 때 현업에서 가장 많이 사용되는 클라우드 서비스 역시 아마존이라고 할 수 있습니다. 마찬가지 이유로 개발자로 취업하기 위해서는 AWS를 다룰 줄 아는 것이 중요한 합격 조건 중 하나가 되었습니다.
아마존이 제공하는 클라우드 서비스는 AWS(Amazon Web Service)입니다. AWS는 2006년에 처음 시작되었고, 현재는 200개가 넘는 서비스를 제공하고 있습니다. AWS의 서비스는 컴퓨팅, 스토리지, 데이터베이스, 네트워킹, 분석, 머신러닝, 인공지능, IoT, 보안 등 다양한 분야에 걸쳐 있습니다. 이러한 서비스를 사용하면 기업은 서버 관리에 시간과 노력을 사용할 필요 없이 비즈니스에 집중할 수 있습니다. 또한, AWS는 전 세계에 24개의 리전과 77개의 가용 영역을 보유하고 있어서 기업이 서비스를 전 세계에 제공하기 위해 각 지역에 서버를 구축할 필요가 없습니다. AWS의 서비스를 사용하면 전 세계 어디에서나 빠르고 안정적으로 서비스를 제공할 수 있습니다. 이러한 장점 때문에 많은 글로벌 기업들이 AWS를 사용하고 있습니다. AWS를 사용하는 유명한 기업으로는 넷플릭스, 페이스북, 삼성, 쿠팡 등이 있습니다.
AWS를 통해 클라우드 서비스가 어떻게 사용되는지를 학습하고 나면 마이크로소프트의 Azure나 구글의 Google Compute Engine 등 다른 클라우드 서비스를 배우는 것은 어렵지 않습니다. AWS는 클라우드 서비스의 시초이자, 가장 많이 사용되는 클라우드 서비스이기 때문에 AWS를 배우는 것은 클라우드 서비스를 배우는 가장 좋은 방법입니다.
[3] AWS 프리 티어
AWS에서는 프리 티어(Free Tier)라는 무료 서비스를 제공합니다. 이는 AWS를 처음 접하는 사람들이 AWS를 사용해 보고, AWS의 서비스를 경험해 볼 수 있도록 제공하는 서비스입니다. 프리 티어는 AWS의 서비스 중 일부를 12개월 동안 무료로 사용할 수 있으며, 제공하는 서비스 중 이 책에서 다루는 서비스들은 다음과 같습니다.
- EC2 : 1년간 매월 750시간의 Linux 및 Windows t2.micro 인스턴스가 포함됩니다.
- Lambda : 월 1백만 건의 무료 요청과 월 40만 GB-초의 컴퓨팅 시간이 포함됩니다.
- RDS : 1년간 매월 750시간의 db.t2.micro 인스턴스, 20GB의 스토리지, 20GB의 백업 용량을 제공합니다.
- S3 : 5GB의 저장 공간, 20,000건의 GET 요청, 2,000건의 PUT, COPY, POST, LIST 요청, 그리고 첫해 동안 매월 15GB의 데이터 전송을 제공합니다.
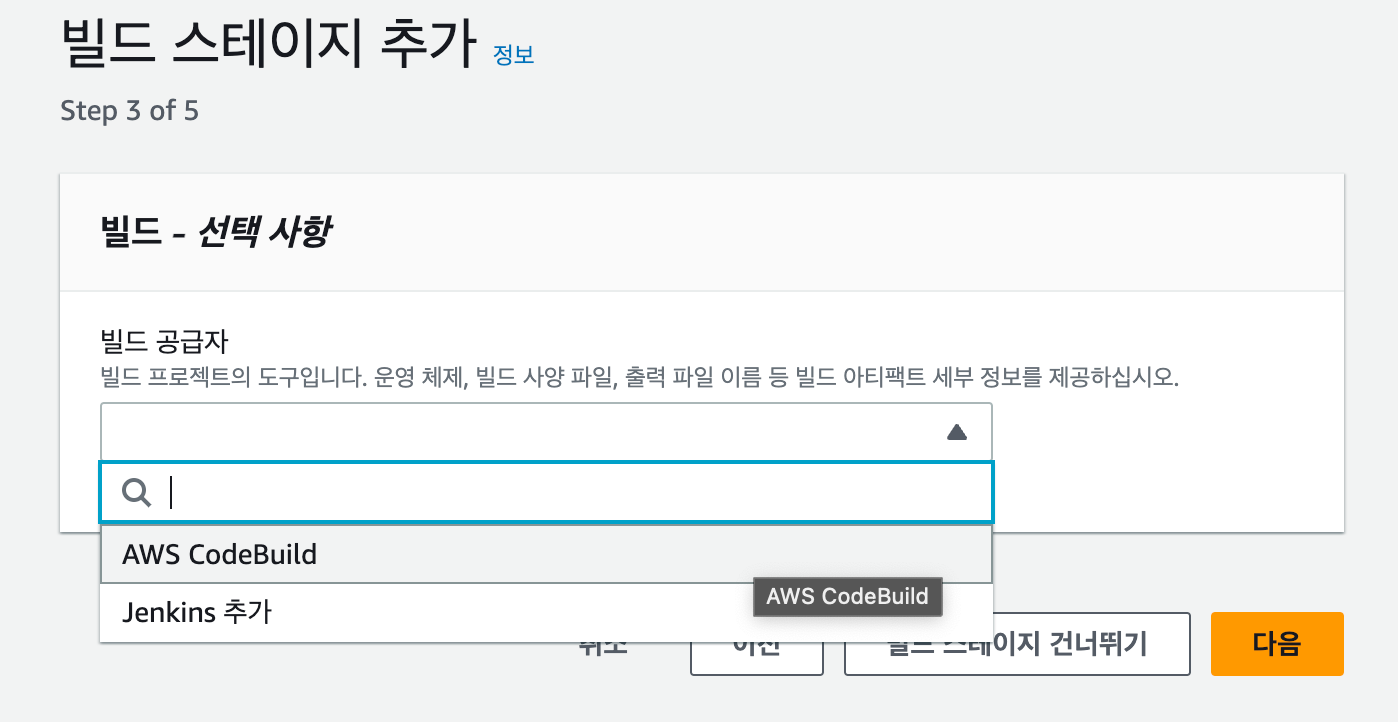
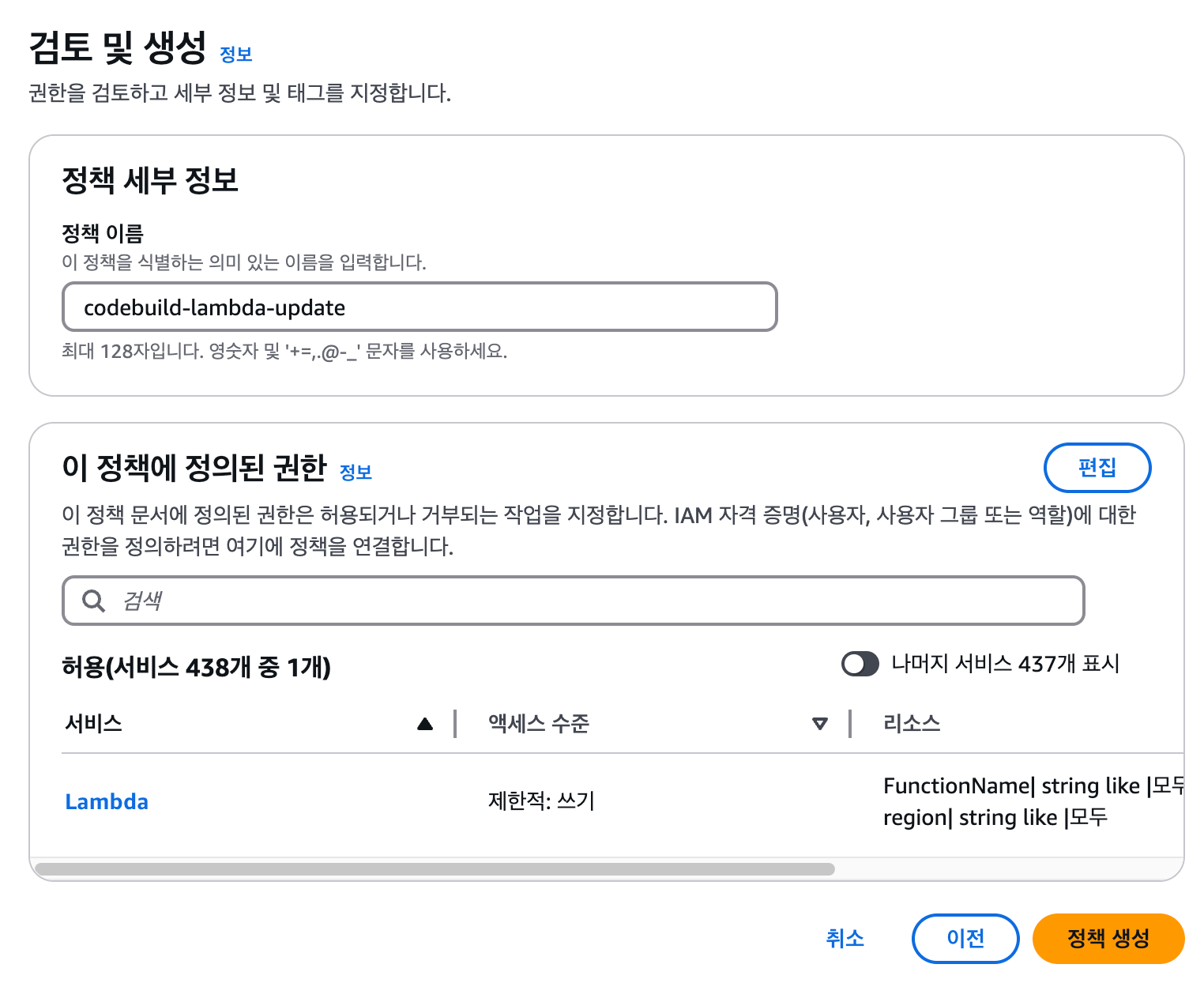
- CodeBuild : 프리 티어가 아닌 일반 사용자에게도 매월 100분의 build.general1.small 컴퓨팅 유형 무료 사용 시간이 제공됩니다.
- CodeDeploy : Amazon EC2, AWS Lambda 또는 Amazon ECS에 코드를 배포하는 경우 추가 요금이 부과되지 않습니다.
- CodePipeline : 프리 티어가 아닌 일반 사용자에게도 V1 유형 파이프라인의 경우 월 1개의 무료 활성 파이프라인을, V2 유형 파이프라인의 경우 월 100분의 무료 작업 실행 시간을 제공합니다.
프리 티어에서 제공하는 전체 서비스 목록은 다음의 링크에서 확인할 수 있습니다.
https://aws.amazon.com/ko/free
[4] 비용 모니터링
AWS에서는 비용을 효과적으로 관리하기 위한 다양한 도구와 기능을 제공합니다. 이 중에서도 Cost Explorer는 사용자가 AWS 비용과 사용량 데이터를 시각적으로 볼 수 있게 제공해 주는 강력한 도구입니다. 이를 활용하면 과금 항목별로 비용을 분석하고, 예상 비용을 산정하는 등의 작업을 수행할 수 있습니다.
실시간 비용 확인
AWS 콘솔의 상단 메뉴에서 "결제 및 비용 관리"를 클릭하면 현재까지의 비용을 확인할 수 있습니다. 화면에서는 현재까지의 비용을 확인할 수 있을 뿐만 아니라, 예상 비용을 확인할 수도 있습니다. 예상 비용은 현재까지의 사용량을 기반으로 현재 달의 예상 비용을 계산한 값입니다. 만일 서비스 사용량이 없는 경우 당연히 예상 비용도 0원으로 표시됩니다.
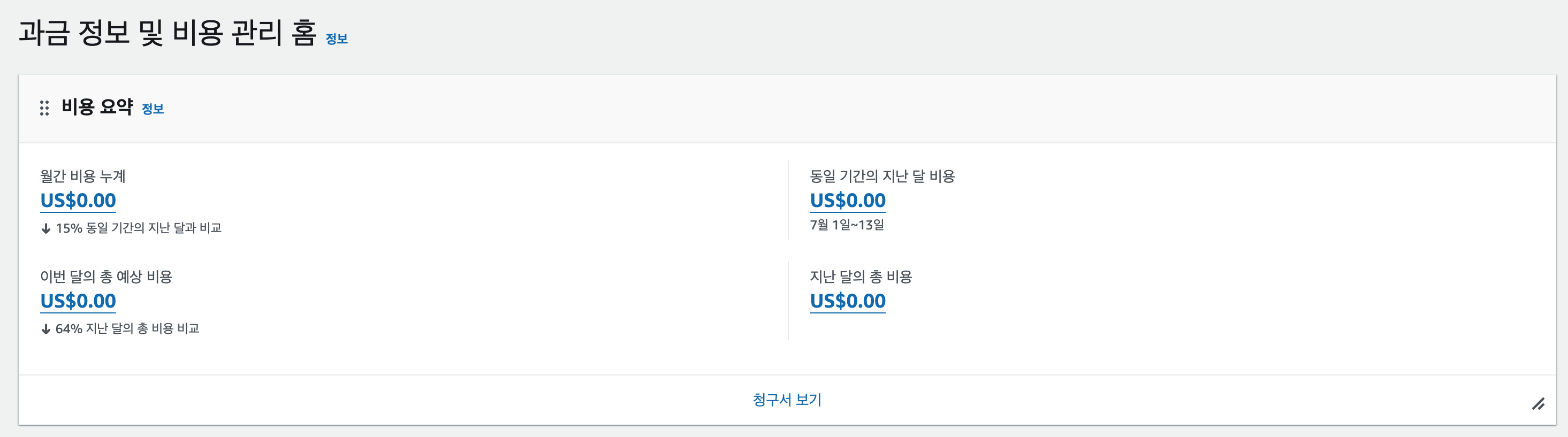
만일 어떤 서비스로부터 요금이 부과되었는지를 자세히 살펴보고 싶다면 메뉴 좌측의 Cost Explorer를 클릭하면 됩니다. Cost Explorer는 AWS 비용과 사용량 데이터를 시각적으로 볼 수 있는 강력한 도구입니다. Cost Explorer를 사용하면 과금 항목별로 비용을 분석하고, 예상 비용을 산정하는 등의 작업을 수행할 수 있습니다.
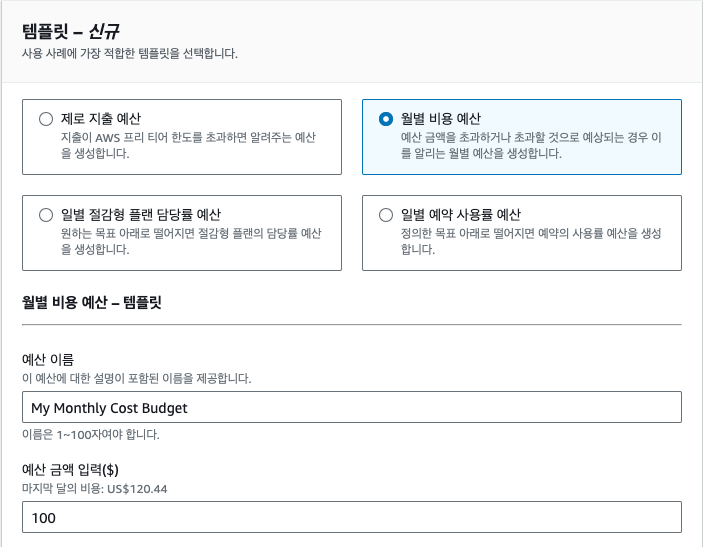
월 사용 예산 제한하기
AWS를 사용할 때 주의할 점은 의도치 않게 설정된 서비스로 인해 과다한 요금이 청구되는 것입니다. 이를 막기 위해서는 월 사용 예산을 설정해 두는 것이 좋습니다. 월 사용 예산을 설정하면 예산을 초과하는 경우 알림을 받을 수 있습니다. 또한, 예산을 초과하는 경우에는 AWS에서 자동으로 서비스를 중단시켜 비용을 절감할 수 있습니다. 추가적으로 알림을 받을 이메일을 입력해 경고 메일을 받을 수 있습니다.

좌측 메뉴에서 '예산'을 클릭하면 예산 목록 대시보드로 이동합니다. 여기서 '예산 생성'을 클릭합니다. 예를 들어 한 달에 100달러 이상 지출하고 싶지 않다면 다음과 같이 설정할 수 있습니다.
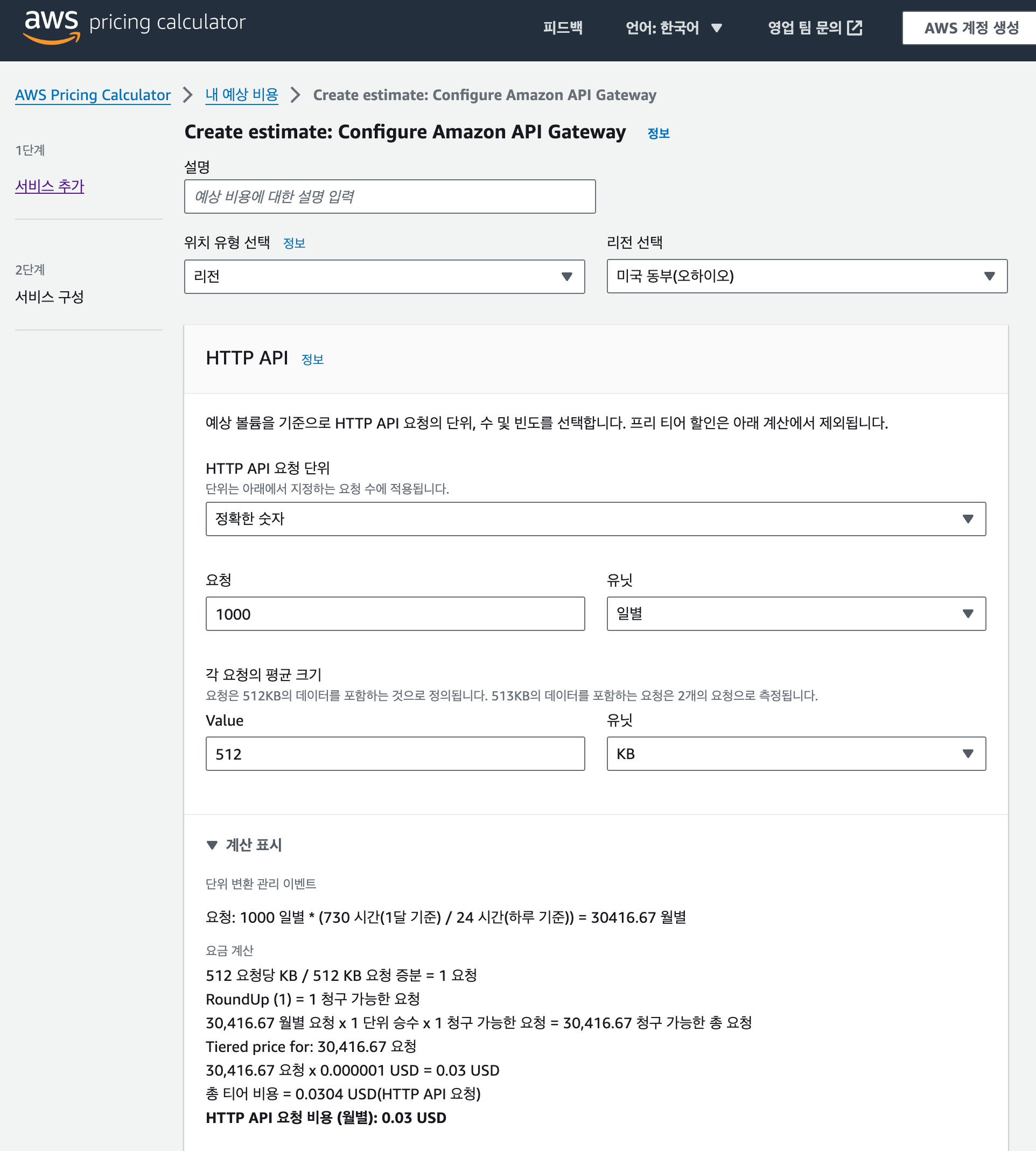
비용 계산기
만일 내가 만들고자 하는 서비스가 대략적으로 어느 정도의 비용을 부과할지를 알고 싶다면 AWS에서 제공하는 비용 계산기를 사용하면 편리합니다. 각 서비스의 구성을 선택하면 해당 서비스를 사용하는데 필요한 비용을 계산해 줍니다. 비용 계산기는 다음 링크에서 확인할 수 있습니다.
https://calculator.aws/#/
[5] 클라우드와 도커
가상화 기술
클라우드 서비스를 배우기 전에 현대 서버 개발에서 필수로 사용되는 기술인 가상화 기술에 대해 알아야 합니다. 가상화 기술이란 하나의 컴퓨터에서 여러 개의 컴퓨터를 동시에 사용할 수 있도록 하는 기술입니다. 해당 기술을 사용하면 하나의 컴퓨터를 여러 개의 컴퓨터처럼 사용할 수 있기 때문에 하나의 컴퓨터에서 여러 개의 운영 체제를 설치하고, 여러 개의 프로그램을 실행할 수 있습니다.
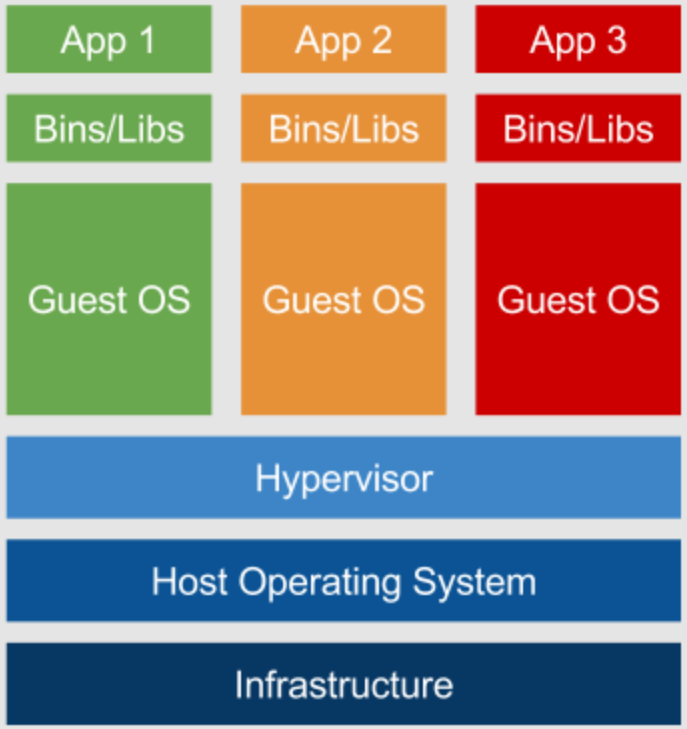
고전적인 가상화 기술은 컴퓨터에서 하이퍼바이저(Hypervisor)라는 소프트웨어를 실행하는 방식을 사용합니다. 이때 하이퍼바이저를 실행하는 컴퓨터를 호스트, 실행되는 가상 컴퓨터를 게스트라고 부릅니다. 하이퍼바이저는 호스트 컴퓨터에서 여러 개의 운영 체제를 실행할 수 있도록 해주는 소프트웨어입니다. 하이퍼바이저는 호스트의 CPU, 메모리, 디스크와 같은 하드웨어를 여러 개의 가상 머신, 또는 VM(Virtual Machine)이라는 가상의 컴퓨터로 분할하고, 각 가상 머신에 운영 체제를 설치합니다. 이렇게 하이퍼바이저를 사용하면 하나의 컴퓨터에서 여러 개의 운영 체제를 실행할 수 있고, 각각의 운영 체제에서 여러 개의 프로그램을 실행할 수 있습니다.
하지만 하이퍼바이저를 사용하면 여러 개의 운영 체제를 실행하기 위해 호스트 하드웨어를 여러 개의 가상 머신으로 분할한 다음 각 게스트 운영 체제에서 사용할 수 있도록 하드웨어를 가상화하는 단계를 거칩니다. 이러한 과정에서 게스트에서 사용하는 하드웨어는 실제 하드웨어보다 성능이 저하됩니다. 한 가지 문제는 호스트의 하드웨어가 분할되기 때문에 각 가상 머신에 할당된 하드웨어를 다른 가상 머신에서는 사용할 수 없습니다. 위의 그림에서 호스트가 CPU 코어를 9개 가지고 있다고 가정할 때 각 게스트가 CPU를 3개씩 할당 받았다고 생각해 보겠습니다. 이때, App1이 실제로 코어를 1개만 사용한다면 2개의 코어는 사용하지 않는 상태로 남게 됩니다. 하지만 이렇게 남는 코어를 다른 게스트에서 사용할 수 없기 때문에 이 CPU 자원은 그대로 낭비됩니다. 서버의 하드웨어 성능은 곧 서버 비용과도 직결되는 문제이기 때문에 가상화 과정에서 발생하는 성능 저하는 상당한 비용 부담으로 이어지게 됩니다.
도커(Docker)의 등장
이러한 문제를 해결하기 위해 등장한 것이 컨테이너(Container)입니다. 컨테이너는 하이퍼바이저와 달리 운영 체제를 가상화하지 않고, 운영 체제의 커널을 공유하는 방식으로 사용합니다. 컨테이너는 운영 체제에서 하나의 프로세스로 동작하기 때문에 컨테이너에서 사용하는 하드웨어는 실제 하드웨어와 동일한 성능을 가집니다. 만일, 한 컨테이너에서 CPU를 많이 사용하지 않는다면 남은 CPU를 다른 컨테이너에서 사용할 수도 있습니다.
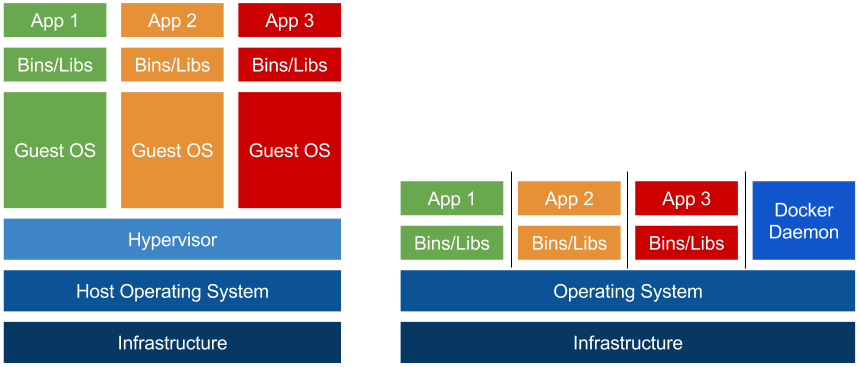
컨테이너 기술 자체는 오래 전에 나왔지만, 도커(Docker)는 컨테이너 기술을 일반 사용자가 쉽게 사용할 수 있도록 만든 덕분에 컨테이너 기술이 대중화될 수 있었습니다. 도커는 컨테이너를 사용하기 위한 플랫폼으로 컨테이너를 쉽게 만들고 실행할 수 있도록 도와줍니다. 도커를 사용하면 컨테이너 사용을 위한 복잡한 설정 과정을 생략할 수 있습니다. 또한, 리눅스 운영 체제에서 실행되고, 컨테이너가 호스트의 커널을 공유하기 때문에 도커에서 실행되는 컨테이너는 리눅스 운영 체제를 사용합니다.
도커 설치와 도커 CLI
사용하는 컴퓨터에 도커를 설치하려면 Docker Desktop을 설치하면 도커 사용에 필요한 모든 도구가 한꺼번에 설치되기 때문에 매우 편리합니다.
https://www.docker.com/products/docker-desktop/
위 주소로 접속하면 자신의 운영체제에 맞는 프로그램이 이미 선택되어 있을 것입니다. 만일 올바르지 않은 운영체제라면 드롭다운 버튼을 통해 자신의 운영체제에 맞는 프로그램을 선택하세요. 버튼을 누르면 설치 파일이 다운로드됩니다.
다만 리눅스의 경우는 각 리눅스 배포판마다 지원 여부와 설치 방법이 약간씩 다르기 때문에 다운로드 버튼을 눌렀을 때 이동되는 페이지에서 자신의 리눅스 배포판에 맞는 설치 방법을 별도로 확인하시기 바랍니다.
다음은 도커를 사용하기 위해 알아야 할 기본적인 CLI(Command Line
Interface) 명령어들을 소개하겠습니다. 도커 CLI는 터미널에서 도커를
제어하는 데 사용되는 명령어입니다. 가장 기본적인 명령어로는 docker run이 있습니다. 이 명령어는 도커 이미지를 실행하여 컨테이너를
생성합니다. 예를 들어, docker run hello-world는 hello-world
이미지를 실행하여 간단한 메시지를 출력합니다.
다음으로 알아야 할 명령어는 docker ps입니다. 이 명령어는 현재 실행
중인 모든 컨테이너의 목록을 보여줍니다. docker ps -a 명령어를
사용하면 중지된 컨테이너를 포함한 모든 컨테이너의 목록을 볼 수 있습니다.
docker images 명령어는 로컬에 저장된 모든 도커 이미지의 목록을
보여줍니다. 이를 통해 사용 가능한 이미지들을 확인할 수 있습니다. 새로운
이미지를 다운로드하려면 docker pull 명령어를 사용합니다. 예를 들어,
docker pull ubuntu는 Ubuntu의 최신 이미지를 다운로드합니다.
이러한 기본적인 명령어들을 익히면 도커를 사용하여 컨테이너를 생성하고 관리하는 데 큰 도움이 될 것입니다. 도커를 더 깊이 이해하고 활용하기 위해서는 이 외에도 많은 명령어와 개념들을 학습해야 하지만, 이러한 기초적인 명령어들만으로도 도커의 기본적인 사용이 가능합니다.
도커 이미지
도커 이미지는 우리가 컴퓨터에서 사용하는 어플리케이션을 실행하기 위해 필요한 모든 파일과 설정 정보를 하나의 패키지처럼 묶어놓은 것을 말합니다. 마치 컴퓨터 프로그램을 설치할 때, 설치 파일 하나로 모든 것을 설치하듯이, 도커 이미지 하나로 어플리케이션 실행에 필요한 모든 환경을 구축할 수 있습니다.
이미지를 더 자세히 설명하자면, 이미지는 어플리케이션 코드, 라이브러리, 시스템 도구, 환경 변수 등 어플리케이션 실행에 필요한 모든 것을 포함하고 있습니다. 이렇게 이미지를 만들어 놓으면, 언제 어디서든 동일한 환경에서 어플리케이션을 실행할 수 있다는 장점이 있습니다. 마치 레고 블록을 조립하듯이, 미리 만들어진 이미지를 이용하여 다양한 어플리케이션을 쉽고 빠르게 실행할 수 있습니다.
도커 이미지는 변경할 수 없는 읽기 전용 파일이기 때문에, 한번 만들어진 이미지는 안전하게 보관하고 재사용할 수 있습니다. 또한, 도커 이미지는 다른 사람들과 공유할 수도 있어서, 누구나 쉽게 동일한 환경을 구축하고 어플리케이션을 실행할 수 있습니다.
도커파일
Dockerfile은 마치 레고 조립 설명서처럼, 도커 이미지를 만드는 과정을 순서대로 정의하는 텍스트 파일입니다. 이 파일 안에 어떤 명령어들을 적느냐에 따라 최종적으로 만들어지는 이미지의 구성이 달라집니다.
Dockerfile의 기본적인 문법은 매우 간단합니다. 각 명령어는 한 줄에 하나씩 작성하며, 명령어 앞에는 해당 명령어의 기능을 나타내는 키워드가 옵니다. 간단한 Dockerfile 예시는 다음과 같습니다.
-
FROM: 새로운 이미지를 만들 때 기반이 되는 이미지를 지정합니다.
-
RUN: 이미지 빌드 시 실행할 명령어를 지정합니다.
-
COPY: 호스트 컴퓨터의 파일을 이미지 내부로 복사합니다.
-
WORKDIR: 이미지 내에서 작업할 디렉토리를 설정합니다.
-
EXPOSE: 컨테이너 내에서 실행되는 서비스의 포트를 노출시킵니다
-
CMD: 컨테이너가 시작될 때 기본적으로 실행할 명령어를 지정합니다.
# 기본 이미지로 Ubuntu를 사용
FROM ubuntu:latest
# 시스템 업데이트 및 Python 설치
RUN apt-get update && apt-get install -y python3
# 작업 디렉토리 설정
WORKDIR /app
# 현재 디렉토리의 모든 파일을 /app 디렉토리로 복사
COPY . /app
# 컨테이너 시작 시 실행할 명령어
CMD ["python", "app.py"]
클라우드에서 작업하려면 도커 이미지를 빌드하기 위해 도커파일을 직접 작성해야 하는 경우가 많습니다. 따라서 기본적인 도커 이미지 문법을 이해하고 파일을 작성하는 방법을 익혀 놓는 것이 좋습니다.
도커 컨테이너
도커 컨테이너는 미리 만들어 놓은 도커 이미지를 실행하는 독립적인 공간이라고 생각하면 됩니다. 마치 컴퓨터에서 프로그램을 설치하고 실행하는 것과 비슷하지만, 도커 컨테이너는 훨씬 가볍고 빠르게 실행됩니다.
도커 이미지가 어플리케이션 실행에 필요한 모든 파일과 설정을 담고 있다면, 도커 컨테이너는 이 이미지를 기반으로 실제로 어플리케이션을 실행하는 공간입니다. 컨테이너는 각각 고립된 환경을 가지고 있어서, 하나의 컨테이너에서 문제가 발생하더라도 다른 컨테이너에 영향을 미치지 않습니다. 이는 여러 개의 어플리케이션을 동일한 서버에서 안전하게 실행할 수 있도록 해줍니다.
또한, 도커 컨테이너는 만들고 삭제하는 데 필요한 과정이 빠르게 수행됩니다. 컨테이너는 컴퓨터 프로그램과 동일하기 때문에 프로그램을 실행하고 종료하는 것처럼 간단하게 컨테이너를 관리할 수 있습니다. 이러한 컨테이너의 특징 덕분에, 개발 환경 구축, 테스트, 배포 등 다양한 분야에서 활용되고 있습니다.
도커 레지스트리
도커 레지스트리는 도커 이미지를 저장하고 관리하는 서버를 의미합니다. 마치 컴퓨터의 파일을 저장하는 저장소처럼, 도커 레지스트리는 다양한 도커 이미지들을 모아두는 역할을 합니다. 이렇게 저장된 이미지들은 필요할 때 언제든지 꺼내 사용할 수 있습니다.
도커 허브는 가장 많이 사용되는 공개 도커 레지스트리 중 하나입니다. 마치 이미지를 공유하는 거대한 도서관과 같이, 도커 허브에는 전 세계 개발자들이 만들어 공유한 수많은 도커 이미지들이 저장되어 있습니다. 즉, 도커 허브를 통해 누구나 자신이 만든 이미지를 공유하고, 다른 사람들이 만든 이미지를 가져다 사용할 수 있습니다.
도커 허브 외에도 개인이나 기업에서 운영하는 사설 도커 레지스트리가 존재합니다. 사설 레지스트리는 보안이 중요하거나 특정 환경에 맞춰 커스터마이징된 이미지를 관리하는 경우에 유용하게 사용됩니다.
[TIP] 윈도우 운영 체제에서의 사용예외적으로 윈도우 운영 체제에서는 윈도우 커널을 사용해 윈도우 컨테이너를 실행합니다. 윈도우에서 리눅스 컨테이너를 실행하게 되면 가상 머신에서 실행되는 리눅스 커널을 사용하게 됩니다. 하지만 윈도우와 리눅스 컨테이너를 동시에 실행하려면 WSL(Windows Subsystems for Linux)라는 기능을 추가로 설치해야 합니다. 물론, 컨테이너가 호스트 운영 체제의 커널을 공유하기 때문에 리눅스 운영 체제에서 커널이 다른 윈도우 컨테이너를 실행할 수는 없습니다. 클라우드에서 도커를 사용하는 환경은 대부분 리눅스 운영 체제입니다.
[6] 리눅스의 특징과 명령어
리눅스(Linux)의 특징
리눅스는 1991년 리누스 토발즈가 만든 운영 체제로 현재 전 세계에서 가장 많이 사용되는 운영 체제입니다. 리눅스는 무료로 사용할 수 있고, 소스 코드가 공개되어 있기 때문에 누구나 사용하고 개선할 수 있습니다. 이러한 특징 때문에 서버, 데스크톱, 모바일, IoT 등 다양한 분야에서 사용되고 있습니다. 특히, 클라우드 환경에서는 정말 예외적인 경우를 제외하고는 대부분 리눅스 운영 체제를 사용하고 있습니다. 이렇게 리눅스가 많이 사용되는 이유는 여러 가지가 있지만, 가장 큰 이유 중 하나는 바로 도커 때문입니다.
여기에서는 리눅스 운영 체제의 기본적인 사용 방법을 알아보겠습니다. 리눅스 운영 체제는 우분투(Ubuntu), SUSE, CentOS 등 다양한 종류가 있는데 이 중에서도 우분투는 가장 많이 사용되는 운영 체제 중 하나입니다. 이 책에서 리눅스 환경을 사용할 때 모든 것은 우분투를 기준으로 설명합니다.
리눅스의 기본 명령어
리눅스 운영 체제는 터미널을 사용해 명령어를 입력하는 방식입니다. 터미널은 리눅스에서 사용하는 명령어를 입력하고 실행할 수 있는 프로그램으로 이를 사용하려면 터미널을 실행하는 프로그램이 필요합니다. 리눅스에서는 터미널을 실행하는 프로그램을 쉘(Shell)이라고 부릅니다. 쉘은 다양한 종류가 있지만, 가장 많이 사용되는 쉘은 bash 쉘입니다. bash 쉘은 리눅스에서 기본으로 제공되는 쉘로 리눅스를 처음 접하는 사용자라면 bash 쉘을 사용하는 것이 좋습니다.
터미널에서는 다양한 명령어를 사용할 수 있습니다. 여기에서는 리눅스에서 가장 많이 사용되는 명령어를 알아보겠습니다. 리눅스 명령어는 다음과 같은 형식으로 사용합니다.
$ 명령어 [옵션] [인자]여기에서
$는 터미널에서 명령어를 입력할 수 있는 상태이고, 명령어는 터미널에서 실행할 수 있는 프로그램입니다. 예를 들어ls명령어는 입력된 경로에 있는 파일과 디렉토리의 목록을 출력하는 것으로 다음과 같이 사용합니다.$ ls /home/ubuntu
ls명령어는 옵션과 인자를 사용할 수 있습니다. 옵션은 명령어의 실행 방식을 변경하는 역할을 합니다. 예를 들어ls명령어는-l옵션을 사용하면 파일과 디렉토리의 상세 정보를 출력합니다.-l옵션은 다음과 같이 사용합니다.$ ls -l /home/ubuntu이외에도 필수적으로 알아 두어야 할 명령어를 정리해 보면 다음과 같습니다.
pwd: 현재 디렉토리의 경로를 출력합니다.$ pwdcd: 디렉토리를 이동합니다.$ cdmkdir: 디렉토리를 생성합니다.$ mkdirrm: 파일을 삭제합니다.$ rmcp: 파일을 복사합니다.$ cpmv: 파일을 이동합니다.$ mvcat: 파일 내용을 출력합니다.$ catgrep: 파일에서 특정 문자열을 검색합니다.$ grepfind: 파일을 검색합니다.$ findchmod: 파일의 권한을 변경합니다.$ chmodchown: 파일의 소유자를 변경합니다.$ chowncurl: 파일을 다운로드하거나 웹 서버에 요청을 보냅니다.$ curl각 명령어의 옵션과 자세한 사용 방법은 터미널에서
man명령어를 사용하면 됩니다.man명령어를 사용해ls명령어의 설명을 확인할 수 있습니다.$ man ls실행 결과
LS(1) General Commands Manual LS(1) NAME ls – list directory contents SYNOPSIS ls [-@ABCFGHILOPRSTUWabcdefghiklmnopqrstuvwxy1%,] [--color=when] [-D format] [file ...] DESCRIPTION For each operand that names a file of a type other than directory, ls displays its name as well as any requested, associated information. For each operand that names a file of type directory, ls displays the names of files contained within that directory, as well as any requested, associated information. If no operands are given, the contents of the current directory are displayed. If more than one operand is given, non-directory operands are displayed first; directory and non-directory operands are sorted separately and in lexicographical order. :화면을 위 아래로 이동하면서 내용을 읽을 수 있고,
q를 누르면 종료할 수 있습니다.[TIP] `less` 프로그램
man페이지를 볼 때 사용되는 프로그램은less라는 프로그램입니다.less는 터미널에서 텍스트 파일을 읽을 때 사용하고,man페이지를 읽을 때도 사용됩니다.less는man페이지를 읽을 때 사용하는 것 외에도 터미널에서 텍스트 파일을 읽을 때 사용할 수 있습니다. 예를 들어less readme.txt와 같이 파일의 내용을 읽을 수 있습니다.이외에도 간단한 파일을 편집할 수 있는 도구인
vi나nano같은 도구의 사용법도 익혀두는 것이 좋습니다. 리눅스는 터미널에서 명령어를 입력해 사용하므로 터미널에서 파일을 편집해야 하는 일이 종종 발생합니다. 따라서vi나nano의 사용법을 미리 익혀두면 편리합니다.필수적이지는 않지만, 리눅스와 관련해서 알아두면 좋은 주제 몇 가지를 소개하고, 1장을 마무리하겠습니다. 어려운 내용이 많기 때문에 클라우드와 리눅스에 어느 정도 익숙해진 후에 다음의 주제를 살펴보는 것을 추천합니다.
- 파일 시스템
- 프로세스와 cgroups
- 사용자와 사용자 그룹
요약
- 클라우드 서비스는 인터넷을 통해 서버를 대여하는 방식이며, AWS가 가장 널리 사용됩니다.
- 도커를 사용하면 격리된 리눅스 환경에서 컨테이너를 쉽게 만들고 실행할 수 있습니다.
퀴즈
문제 1
클라우드 서비스가 등장하기 전, 웹 서비스를 구축할 때 발생하는 주요 문제점으로 올바르지 않은 것은 무엇인가요?
A. 서버를 직접 구매하고 설치해야 한다.
B. 서버의 물리적 고장이나 화재 등 위험에 직접 대응해야 한다.
C. 서버 자원의 확장이나 축소가 자유롭고 자동화되어 있다.
D. 서버 관리와 운영에 많은 시간과 비용이 소요된다.
정답: C
해설: 클라우드 이전에는 서버 자원의 확장이나 축소가 자유롭지 않고, 예측이 어렵고 비효율적이었습니다.
문제 2
다음 중 AWS(Amazon Web Services)에 대한 설명으로 옳지 않은 것은 무엇인가요?
A. AWS는 2006년에 시작된 아마존의 클라우드 서비스이다.
B. AWS는 전 세계에서 가장 높은 시장 점유율을 가진 클라우드 서비스이다.
C. AWS는 컴퓨팅, 스토리지, 데이터베이스, 네트워킹 등 다양한 서비스를 제공한다.
D. AWS는 국내에서는 거의 사용되지 않는다.
정답: D
해설: AWS는 국내에서도 가장 높은 점유율을 가진 클라우드 서비스입니다.
문제 3
AWS 프리 티어(Free Tier)에 대한 설명으로 올바른 것은 무엇인가요?
A. 모든 AWS 서비스가 무제한으로 무료 제공된다.
B. 일부 서비스에 한해 일정 기간 무료로 사용해볼 수 있다.
C. 프리 티어를 사용하면 비용 모니터링이 불가능하다.
D. 프리 티어는 기업 고객만 사용할 수 있다.
정답: B
해설: 프리 티어는 일부 서비스에 한해 12개월 동안 무료로 체험할 수 있도록 제공됩니다.
문제 4
도커(Docker)와 기존 가상화 기술(하이퍼바이저)의 차이로 올바른 것은 무엇인가요?
A. 도커는 운영체제 전체를 가상화한다.
B. 하이퍼바이저 방식은 컨테이너보다 자원 활용이 효율적이다.
C. 도커는 운영체제의 커널을 공유하여 컨테이너를 실행한다.
D. 도커는 가상머신보다 느리게 실행된다.
정답: C
해설: 도커는 운영체제의 커널을 공유하여 컨테이너를 실행하기 때문에 자원 활용이 효율적이고 빠릅니다.
문제 5
리눅스에서 현재 디렉토리의 경로를 출력하는 명령어는 무엇인가요?
A. cd
B. pwd
C. ls
D. mkdir
정답: B
해설: pwd 명령어는 현재 디렉토리의 경로를 출력합니다.
2장 사용자 권한 설정(IAM)의 기초
2장에서는 클라우드 환경에서 보안을 위한 필수 요소인 IAM(Identity and Access Management)에 대해 자세히 알아봅니다. AWS IAM의 주요 구성 요소인 사용자, 그룹, 정책, 역할의 개념을 이해하고, 실제 현업에서 IAM을 어떻게 활용하는지 다양한 예시를 통해 살펴봅니다. 또한, IAM 사용 시 주의해야 할 점과 루트 사용자 관리, 액세스 키 발급, AWS CLI 설치 등 실제 환경에서 IAM을 설정하고 관리하는 방법을 상세히 설명합니다.
[1] IAM(Identity and Access Management)의 개념
AWS의 사용자 계정에는 두 가지 종류가 있습니다. 결제 관리를 포함한 계정의 모든 권한을 가지고 있는 루트 사용자와 AWS를 사용해 서비스를 관리 및 개발하는 IAM 사용자입니다. 이런 이유에서 AWS 콘솔에 로그인할 때도 두 가지 사용자 중 하나를 선택하도록 되어 있습니다.
루트 사용자는 관리 목적 이외에 다른 용도로는 사용하지 않아야 보안 위협을 줄일 수 있습니다. 특히, 루트 사용자 계정이 탈취되면 고객센터를 통해 복구해야 하는데 그 과정이 매우 복잡하고 까다롭습니다. 따라서 루트 사용자에는 MFA(Multi-factor authentication)를 설정해 두고 평상시에는 사용하지 않도록 합니다.
지금과 같이 AWS의 다양한 기능을 사용해 서비스를 관리하고 개발하는 경우에는 IAM 사용자 계정을 사용하면 됩니다. IAM 사용자 계정은 AWS 콘솔에서 IAM 메뉴를 통해 생성하는 사용자이고, IAM 사용자는 한 사람 또는 하나의 AWS 애플리케이션을 의미합니다. 각각의 IAM 사용자 계정은 AWS 서비스에 접근할 때 사용되는 키로 ID에 해당하는 액세스 키(Access Key)와 비밀번호에 해당하는 비밀 액세스 키(Secret Access Key)가 주어집니다. IAM은 AWS 리소스에 대한 접근 권한을 안전하게 제어하는데 사용되는 서비스로 이것을 사용하면 사용자가 접근할 수 있는 AWS 리소스를 중앙에서 쉽게 관리할 수 있습니다.
[2] AWS IAM의 주요 구성 요소
사용자(User)
사용자는 실제로 AWS를 사용하는 사람이나 애플리케이션을 의미합니다. 사용자는 AWS 리소스에 대한 액세스 권한을 가질 수 있습니다. 예를 들어, 개발자는 EC2 인스턴스를 생성하거나 S3 버킷에 파일을 업로드하는 권한을 가질 수 있습니다.
그룹(Group)
그룹은 여러 사용자의 집합을 의미합니다. 그룹에 속한 사용자는 그룹에 부여된 권한을 사용할 수 있습니다. 예를 들어, '개발자' 그룹에 속한 모든 사용자는 EC2 인스턴스 생성이나 S3 버킷에 파일 업로드와 같은 권한을 가질 수 있습니다.
정책(Policy)
정책은 JSON 형식으로 정의된 문서로 사용자와 그룹, 역할이 무엇을 할 수 있는지를 정의합니다. 예를 들어, 특정 IAM 사용자가 EC2 인스턴스를 생성하거나 S3 버킷에 파일을 업로드할 수 있는지를 결정합니다.
역할(Role)
역할은 AWS 리소스가 무엇을 할 수 있는지를 정의하는 것으로 AWS 리소스에 부여됩니다. 즉, 다른 사용자가 역할을 부여받아 사용할 수 있습니다. 예를 들어, EC2 인스턴스가 S3 버킷에 액세스 하는 경우 해당 인스턴스에 역할을 부여해 S3 버킷에 액세스할 수 있는 권한을 제공할 수 있습니다. 또한, 역할은 다른 자격에 대해서 신뢰 관계를 구축할 수 있고, 역할을 바꾸어 가면서 서비스를 사용할 수도 있습니다.
[3] 현업에서의 IAM 사용 예시
AWS 서비스 중 하나인 S3을 사용자 또는 애플리케이션이 사용할 수 있는지의 여부에 대해 특정 과정을 통해 확인해 보겠습니다. S3이란 문서나 사진 같은 파일을 저장하고. 각 파일에 부여된 URL로 파일을 다운로드 받을 수 있는 서비스입니다.
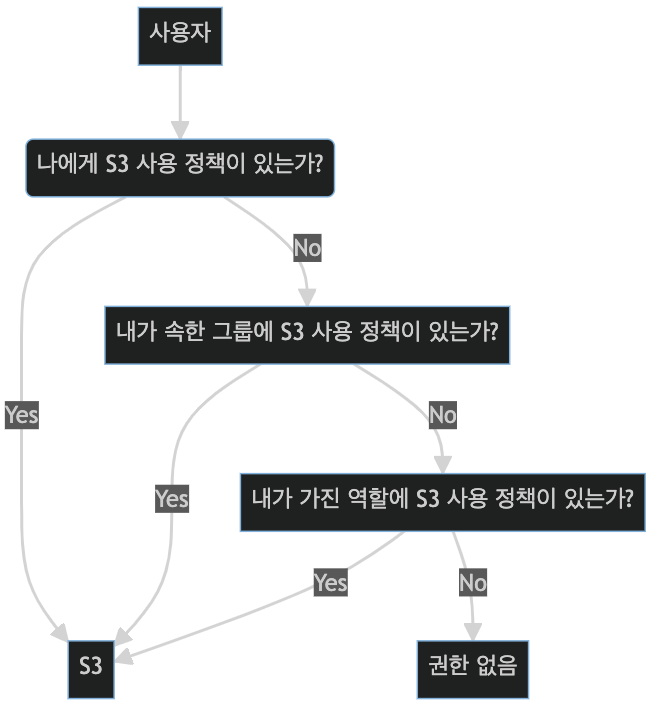
사용자에게 정책이 있는지 확인
사용자에게 정책이 있는지를 확인하는 순서는 다음과 같습니다. 가장 먼저 사용자 자체에 부여된 정책이 있는지를 확인합니다. 정책이 있다면 곧바로 S3을 사용하고, 정책이 없다면 사용자가 속한 사용자 그룹에 정책이 있는지를 확인합니다. 정책이 있다면 S3을 사용할 수 있고, 없다면 본인이 가진 역할 중에서 S3의 사용 정책이 있는 역할 유무를 확인합니다. 만일, 역할 중 정책이 있는 역할이 있다면 사용이 가능하지만 없다면 해당 사용자는 S3에 대한 사용 권한이 없습니다.
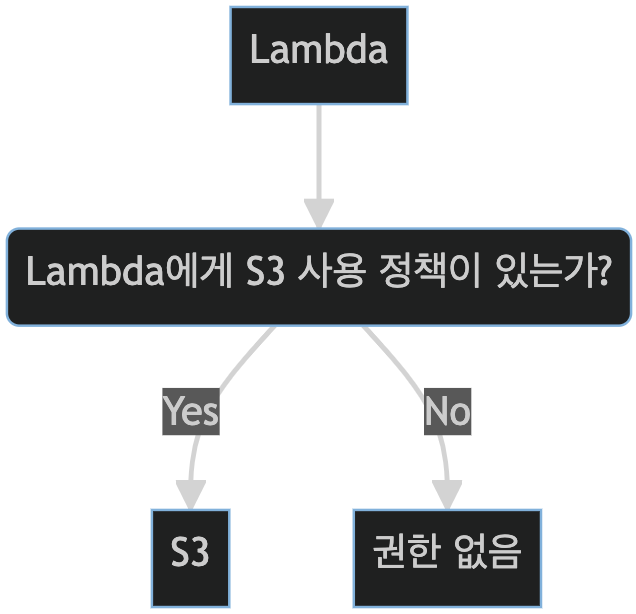
서비스에 정책이 있는지 확인
여기에서는 도커 컨테이너를 실행하는 서비스인 람다가 S3를 사용할 수 있는지 확인하는 방법을 살펴보겠습니다. 서비스의 경우, 유일한 판단 기준은 역할입니다. 즉, 서비스가 부여받은 역할이 사용하고자 하는 리소스에 대해 정책을 가지고 있는지만 확인합니다. 역할에 사용 정책이 부여되어 있다면 사용이 가능하지만, 없다면 접근 권한이 없습니다.
[4] AWS IAM 사용 시 주의사항
루트 사용자의 제한
AWS 계정을 생성하면 루트 사용자가 자동으로 생성됩니다. 루트 사용자는 모든 AWS 서비스에 대해 완전한 접근 권한을 가지고 있습니다. 그러나 루트 사용자를 일상적인 작업에 사용하는 것은 위험할 수 있습니다. 만약, 루트 사용자의 자격 증명이 유출되면 공격자는 AWS 리소스를 제어하거나 삭제할 수 있습니다. 따라서 루트 사용자를 사용하지 않고 IAM 사용자를 생성해 필요한 권한만 부여하는 것이 좋습니다.
불필요한 사용자의 제한
IAM 사용자는 AWS 리소스에 대한 접근를 제어하는데 필요합니다. 그러나 필요 이상의 IAM 사용자를 생성하면 보안 위험이 증가할 수 있습니다. 각 IAM 사용자는 고유한 자격 증명을 가지므로 관리해야 할 자격 증명이 많아집니다. 또한, 불필요한 IAM 사용자가 리소스에 접근하면 실수로 중요한 데이터를 변경하거나 삭제할 수 있습니다.
개별 사용자에게 정책이나 역할을 부여하는 대신 그룹 사용
IAM에서는 여러 IAM 사용자를 그룹으로 묶어 동일한 권한을 부여할 수 있습니다. 이렇게 하면 권한 관리가 훨씬 간편합니다. 예를 들어, 개발자 그룹을 만들고 해당 그룹에 'EC2 인스턴스 생성 권한'을 부여할 수 있습니다. 그러면 그룹에 속하는 모든 IAM 사용자는 EC2 인스턴스를 생성할 수 있습니다.
최소한의 권한만을 허용(Principle of least privilege)
최소 권한 원칙은 보안의 핵심 원칙 중 하나입니다. 해당 원칙에 따르면 IAM 사용자는 그들의 작업을 수행하는데 필요한 최소한의 권한만을 가지고 있어야 합니다. 예를 들어, 데이터베이스 관리자는 데이터베이스에 대한 전체 접근 권한이 필요하지만, 웹 서버를 관리하는 개발자는 데이터베이스에 대한 접근 권한이 필요하지 않을 수 있습니다.
MFA(Multi-Factor Authentication)의 사용
MFA는 계정 보안을 강화하는데 매우 효과적인 방법입니다. MFA를 설정하면 IAM 사용자는 자신의 자격 증명 외에도 추가적인 인증 요소(예 : 휴대폰에 전송된 코드)를 제공해야 합니다. 이렇게 하면 자격 증명이 유출되더라도 공격자가 계정에 접근하는 것을 막을 수 있습니다.
Accesskey 대신 역할 사용
IAM 역할은 AWS 리소스가 다른 AWS 리소스에 접근하는 방식을 정의합니다. 역할은 장기적인 자격 증명 대신 일시적인 보안 자격 증명을 제공하므로 보안 위험이 줄어듭니다. 예를 들어, EC2 인스턴스가 S3 버킷에 접근하는 경우 해당 인스턴스에 역할을 부여해 S3 버킷에 접근할 수 있는 권한을 제공할 수 있습니다.
요약
- AWS Identity and Access Management (IAM)은 AWS 리소스에 대한 액세스를 안전하게 제어하는데 도움이 되는 웹 서비스입니다.
- IAM을 사용하면 사용자가 액세스할 수 있는 AWS 리소스를 중앙에서 관리할 수 있는 권한을 조절할 수 있습니다.
- IAM은 누가 인증(로그인)되고, 권한이 있는지를 제어하는데 사용되고, 사용자와 그들의 AWS 콘솔에 대한 액세스 수준을 관리합니다.
퀴즈
문제 1
AWS 계정의 루트 사용자와 IAM 사용자에 대한 설명으로 올바른 것은 무엇인가요?
A. 루트 사용자는 모든 AWS 리소스에 대한 권한을 가지며, 일상적인 작업에도 사용하는 것이 좋다.
B. IAM 사용자는 계정의 결제 정보에 접근할 수 있다.
C. 루트 사용자는 계정 생성 시 자동으로 생성되며, 평상시에는 사용하지 않는 것이 좋다.
D. IAM 사용자는 루트 사용자로부터 권한을 위임받을 수 없다.
정답: C
해설: 루트 사용자는 계정 생성 시 자동으로 만들어지며, 보안상 평상시에는 사용하지 않는 것이 좋습니다.
문제 2
AWS IAM의 주요 구성 요소에 대한 설명으로 옳지 않은 것은 무엇인가요?
A. 사용자는 실제로 AWS를 사용하는 사람이나 애플리케이션을 의미한다.
B. 그룹은 여러 사용자를 묶어 동일한 권한을 부여할 수 있다.
C. 정책은 XML 형식으로 작성된 문서로 권한을 정의한다.
D. 역할은 AWS 리소스가 다른 리소스에 접근할 때 권한을 부여하는 데 사용한다.
정답: C
해설: 정책은 XML이 아니라 JSON 형식의 문서로 작성됩니다.
문제 3
IAM 정책을 부여하는 가장 권장되는 방법은 무엇인가요?
A. 각 사용자에게 직접 권한을 부여한다.
B. 그룹을 만들어 그룹에 권한을 부여한 뒤, 사용자를 그룹에 추가한다.
C. 모든 사용자에게 루트 권한을 부여한다.
D. 정책을 사용하지 않고 역할만 부여한다.
정답: B
해설: 권한 관리를 효율적으로 하기 위해 그룹에 권한을 부여하고, 사용자를 그룹에 추가하는 것이 가장 좋습니다.
문제 4
IAM 사용 시 보안을 강화하기 위한 올바른 방법이 아닌 것은 무엇인가요?
A. 루트 사용자에는 MFA(다중 인증)를 설정한다.
B. 필요 이상의 IAM 사용자를 생성한다.
C. 최소 권한 원칙을 적용한다.
D. 액세스 키는 안전하게 관리한다.
정답: B
해설: 필요 이상의 IAM 사용자를 생성하는 것은 보안 위험을 높이므로 권장되지 않습니다.
문제 5
AWS CLI를 사용해 AWS 리소스를 관리하려면 반드시 필요한 것은 무엇인가요?
A. 루트 사용자의 비밀번호
B. IAM 사용자의 액세스 키와 비밀 액세스 키
C. IAM 역할의 이름
D. 정책 문서의 ARN
정답: B
해설: AWS CLI를 사용하려면 IAM 사용자의 액세스 키와 비밀 액세스 키가 필요합니다.
3장 AWS 네트워크 핵심
웹 서비스를 만들기 위해서는 네트워크 설정이 필수적입니다. AWS의 네트워크는 상당히 복잡하게 구성되어 있고, 세부적인 설정은 대규모 서비스에서 주로 사용되는 개념입니다. 하지만 기본적인 네트워크 설정 방법은 보안상 안전한 서비스를 구축하기 위해서, 그리고 서비스를 인터넷에 연결하기 위해서는 필수적인 개념이기 때문에 반드시 알아 두어야 합니다.
[1] 리전과 가용 영역
AWS에서 리전이란 AWS가 전 세계에 설치한 데이터 센터군을 가리키는 개념입니다. 데이터 센터군이란 여러 개의 데이터 센터를 묶어둔 것인데 예를 들어, 미국 동부 버지니아 북부에 위치한 데이터 센터군은
us-east-1리전을 구성하고, 서울 지역에 설치된 데이터 센터군은ap-northeast-2리전을 구성합니다. 리전은 서로 네트워크적으로 격리되어 있기 때문에 리전 간에는 리소스와 데이터를 기본적으로 복제하지 않습니다. 사용자는 전 세계에 위치한 데이터 센터 중 어느 위치에 리소스를 생성할 것인지 직접 선택할 수 있습니다.리전의 주된 장점은 다음과 같습니다.
- 첫째, 사용자와 가까운 리전을 선택함으로써 애플리케이션의 대기 시간을 줄일 수 있습니다.
- 둘째, 리전별로 리소스를 분산 배치함으로써 서비스에 이중화(Redundancy)를 제공하고, 장애 시 격리가 가능합니다.
- 셋째, GDPR과 같은 데이터 보관과 관련된 법적요구사항을 충족할 수 있습니다.
- 넷째, 서로 다른 지리적 위치에서 배포와 운영을 수행할 수 있습니다.
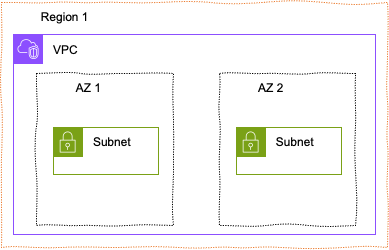
리전 내에는 가용 영역(Availability Zones)이라고 부르는 별도의 데이터 센터들이 여러 개 있습니다. 가용 영역은 하나의 리전 내에 여러 개가 존재하며, 각각의 영역은 독립된 전원, 냉각 및 네트워킹을 가지고 있습니다. 가용 영역은 하나의 데이터 센터를 의미하며, 리전 내에는 최소 2개 이상의 가용 영역이 존재합니다. 하나의 리전에 여러 개의 가용 영역이 존재하는 이유는 장애 시 서비스를 계속 운영할 수 있도록 하기 위함입니다. 예를 들어, 서울 리전의 가용 영역은
ap-northeast-2a,ap-northeast-2b,ap-northeast-2c가 있습니다. 이러한 가용 영역들은 서로 다른 데이터 센터에 위치하고 있으며, 하나의 가용 영역에 화재나 지진 등으로 문제가 발생하더라도 다른 가용 영역에서 서비스를 계속 운영할 수 있습니다.[2] VPC(Virtual Private Cloud)의 개념
Amazon VPC는 하나의 AWS 리전 내에서 완전히 논리적으로 격리된 가상 네트워크 환경을 제공하는 서비스입니다. 마치 자체 데이터 센터의 네트워크를 클라우드 상에 구축하는 것과 같다고 볼 수 있습니다. VPC를 생성할 때 사용자는 자신만의 IP 주소 범위를 할당하여 독립적인 네트워크 공간을 확보할 수 있으며, 이 공간 내에서 EC2 인스턴스, RDS 데이터베이스, Lambda 함수 등 다양한 AWS 서비스를 자유롭게 배포하고 관리할 수 있습니다.
VPC는 단순한 네트워크 공간을 넘어, 사용자가 직접 네트워크 구성을 제어할 수 있는 유연성을 제공합니다. 서브넷을 생성하여 VPC를 더 작은 논리적인 네트워크로 분할하고, 라우팅 테이블을 통해 서브넷 간의 통신 경로를 설정할 수 있습니다. 또한, 인터넷 게이트웨이를 연결하여 외부 인터넷과의 연결을 설정하고, VPN 연결을 통해 온프레미스 네트워크와 연결할 수도 있습니다.
VPC는 보안 기능 또한 강력하게 지원합니다. 보안 그룹은 EC2 인스턴스에 대한 인바운드와 아웃바운드 트래픽을 제어하여, 특정 IP 주소나 포트에서 오는 트래픽만 허용하도록 설정할 수 있습니다. 네트워크 ACL은 서브넷 수준에서 트래픽을 필터링하여 더욱 세밀한 보안 정책을 구현할 수 있습니다.
VPC를 활용하면 다음과 같은 이점을 얻을 수 있습니다.
독립적인 네트워크 환경: 다른 AWS 고객과 완전히 격리된 환경에서 서비스를 운영할 수 있습니다.
유연한 네트워크 구성: 서브넷, 라우팅 테이블, 게이트웨이 등을 자유롭게 구성하여 복잡한 네트워크 환경을 구축할 수 있습니다.
강력한 보안 기능: 보안 그룹과 네트워크 ACL을 통해 안전한 네트워크 환경을 구축할 수 있습니다.
확장성: 필요에 따라 VPC를 쉽게 확장할 수 있습니다.
요약하면, VPC는 사용자가 자신만의 가상 네트워크를 구축하고 관리할 수 있도록 하는 강력한 서비스입니다. VPC를 통해 안전하고 유연하며 확장 가능한 클라우드 환경을 구축할 수 있습니다.
[3] 서브넷(Subnet)의 개념
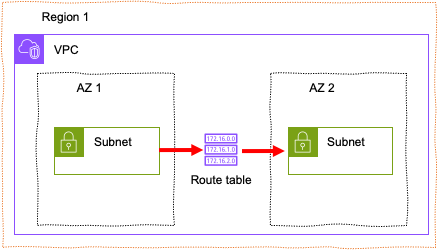
서브넷은 큰 네트워크 안에 있는 작은 네트워크를 의미하는데 IP 네트워크를 논리적으로 세분화한 것으로 하나의 네트워크를 두 개 이상의 네트워크로 나누는 작업입니다. 서브넷을 사용하면 한 서버에서 다른 서버의 경로를 단순화해서 네트워크를 더욱 효율적으로 만들 수 있습니다.
서브넷 내부의 네트워크 트래픽은 불필요한 라우터를 거치지 않고 짧은 거리를 이동해 목적지에 도달할 수 있습니다. 만일, 외부 네트워크에서 데이터가 수신되는 경우에는 데이터가 목적지까지 효율적으로 도달하도록 서브넷별로 데이터를 라우팅하게 됩니다. 이때, 사용되는 것이 라우팅 테이블로 서로 다른 네트워크 사이를 어떻게 연결할지를 정의해 놓은 테이블입니다. 라우팅 테이블은 서브넷에 연결된 인스턴스가 다른 서브넷에 있는 인스턴스와 통신할 수 있도록 합니다. VPC 내부에서 다른 서브넷으로 네트워크를 연결하는 경우에는 자동적으로 로컬 라우팅이 생성되기 때문에 별도의 라우팅 테이블을 생성할 필요가 없습니다.
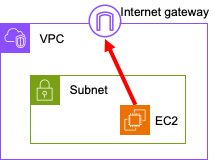
[4] 인터넷 게이트웨이(Internet Gateway)
AWS VPC에서 인터넷 게이트웨이는 마치 건물의 현관문과 같이 VPC 내부의 리소스들이 외부 인터넷과 소통할 수 있도록 연결해주는 가상 네트워크 장치입니다. 이는 VPC 내부의 서브넷과 외부 인터넷 사이의 트래픽을 중계하는 역할을 수행합니다.
퍼블릭 서브넷은 인터넷 게이트웨이에 직접 연결되어 있어 외부 인터넷과의 통신이 가능한 서브넷입니다. 퍼블릭 서브넷에 위치한 인스턴스는 인터넷에서 직접 접근할 수 있으며, 웹 서버, 로드밸런서 등 외부에서 접근해야 하는 서비스를 위한 인스턴스를 배치하는 데 적합합니다.
반면, 프라이빗 서브넷은 인터넷 게이트웨이에 직접 연결되어 있지 않아 외부 인터넷과의 직접적인 통신이 제한됩니다. 프라이빗 서브넷에 위치한 인스턴스는 주로 내부 시스템이나 다른 AWS 서비스와의 통신을 위한 목적으로 사용됩니다. 데이터베이스 서버, 내부 애플리케이션 서버 등 보안이 중요한 서비스를 위한 인스턴스를 배치하는 데 적합합니다.
인터넷 게이트웨이를 구성할 때는 퍼블릭 서브넷과 프라이빗 서브넷을 적절히 분리하여 사용해야 합니다. 퍼블릭 서브넷에는 인터넷에 노출되어도 문제가 없는 서비스를 위한 인스턴스를 배치하고, 프라이빗 서브넷에는 보안이 중요한 서비스를 위한 인스턴스를 배치하여 보안을 강화할 수 있습니다.
구체적인 예시를 들어 설명하면, 웹 서버를 운영하고 싶은 경우 웹 서버 인스턴스를 퍼블릭 서브넷에 배치하고, 인터넷 게이트웨이를 통해 외부에서 접근할 수 있도록 설정하면 됩니다. 반면, 데이터베이스 서버는 외부에서 직접 접근할 필요가 없으므로 프라이빗 서브넷에 배치하고, 필요한 경우 VPN 연결이나 VPC 엔드포인트를 통해 다른 서비스와 연결할 수 있습니다.
요약하면, 인터넷 게이트웨이는 VPC와 외부 인터넷 사이의 연결을 담당하고, 퍼블릭 서브넷과 프라이빗 서브넷은 각각 외부 인터넷과의 접근성에 따라 구분되는 서브넷입니다. 이들을 적절히 활용하여 안전하고 효율적인 클라우드 환경을 구축할 수 있습니다.
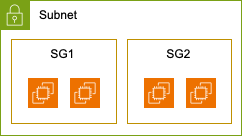
[5] 보안 그룹
보안 그룹은 AWS VPC에서 리소스에 대한 인바운드 및 아웃바운드 트래픽을 제어하는 가상 방화벽입니다. 인스턴스 수준에서 작동하며, 프로토콜, 포트, IP 주소 등을 기반으로 매우 세밀한 트래픽 제어 규칙을 설정할 수 있습니다. 예를 들어, 웹 서버에 대한 HTTP 및 HTTPS 트래픽만 허용하도록 설정해 보안을 강화할 수 있습니다.
보안 그룹은 동적으로 변경할 수 있으며, 여러 보안 그룹을 하나의 인스턴스에 연결해 복잡한 보안 정책을 구현할 수 있습니다. 뒤에서 설명할 네트워크 ACL과 함께 사용하면 더욱 강력한 네트워크 보안 체계를 구축할 수 있습니다. NACL은 서브넷 수준에서 작동하며, 보안 그룹보다 더 광범위한 제어를 제공합니다.
보안 그룹의 주요 활용 사례는 다음과 같습니다.
웹 서버: 특정 IP 주소에서만 접근 허용
데이터베이스 서버: 특정 포트(예: 3306)를 통한 접근만 허용
VPN 연결: VPN 트래픽만 허용
보안 그룹은 강력한 보안 기능을 제공하지만, DDoS 공격과 같은 고급 위협으로부터 완벽하게 보호하지 못할 수 있습니다. 따라서 다른 보안 조치와 함께 사용해야 합니다.
[6] ACL(Access Control Lists)의 개념
네트워크 액세스 제어 목록(Access Control Lists)은 서브넷 수준에서 작동하는 보안 장치입니다. 각 그룹에 대해 정의된 인바운드(inbound) 및 아웃바운드 (outbound)규칙을 통해 최소한의 접근 권한을 부여해서 VPC 서브넷 내의 모든 리소스에 엄격한 보안을 적용할 수 있습니다. 인바운드란 서브넷으로 들어오는 연결을 말하고, 아웃바운드란 서브넷에서 밖으로 나가는 연결을 의미합니다.
IP 주소 체계와 CIDR
ACL를 이해하려면 IP 주소가 어떻게 구성되는지를 알아야 합니다. 인터넷에 연결된 모든 기기는 고유한 주소를 가지고 있어야 합니다. 이 주소를 통해 데이터를 주고받으며 인터넷 통신이 이루어지는데, 이때 사용되는 주소 체계가 바로 IP 주소입니다. 현재 주로 사용되는 IP 주소 체계는 IPv4와 IPv6 두 가지가 있습니다.
IPv4는 오랫동안 사용되어 온 인터넷 주소 체계로, 32비트로 구성되어 약 43억 개의 주소를 생성할 수 있습니다. 192.168.0.1와 같이 숫자 4개를 점으로 구분하는 형태로 정의됩니다. 하지만 인터넷 기기의 폭발적인 증가로 인해 IPv4 주소가 부족해지는 문제가 발생했습니다. 이는 마치 전화번호가 부족해져 새로운 전화번호를 만들 수 없는 상황과 비슷합니다.
IPv6는 IPv4의 한계를 극복하기 위해 개발된 차세대 인터넷 주소 체계입니다. 128비트로 구성되어 거의 무한대에 가까운 주소를 생성할 수 있습니다. 2001:0db8:85a3:0000:0000:8a2e:0370:7334: 와 같이 16진수 숫자 8개로 구성되어 있습니다. 여기서 0이 연속되는 경우에는 생략이 가능해서 2001:db8:85a3::8a2e:370:7334처럼 표현할 수도 있습니다. IPv6는 IPv4에 비해 더욱 효율적인 주소 할당, 자동 구성, 보안 기능 등을 제공하며, 미래 인터넷 환경에 적합한 주소 체계로 평가받고 있습니다.
하지만 IPv6로의 전환은 단순한 주소 체계 변경을 넘어 네트워크 인프라 전체를 변경해야 하는 대규모 작업이기 때문에 시간이 오래 걸리고 있습니다. 현재는 IPv4와 IPv6를 함께 사용하는 이중 스택 환경이 주를 이루고 있으며, 점차 IPv6으로의 전환이 가속화되고 있습니다.
CIDR(Classless Inter-Domain Routing)은 IP주소를 효율적으로 관리하기 위한 방법 중 하나입니다. 기존에는 클래스를 기반으로 IP를 할당했습니다. 예를 들어, B 클래스 네트워크(128.0.0.0 ~ 191.255.255.255)를 할당받았다고 가정해 봅시다. 만약 1000개의 IP 주소만 필요한 경우에도 B 클래스 전체를 사용해야 하므로, 나머지 주소는 모두 낭비됩니다.
CIDR 방식을 사용하면 192.168.1.0/24와 같이 필요한 만큼의 주소만 할당할 수 있습니다.
192.168.1.0: 네트워크 주소
/24: 서브넷 마스크 (24비트)
이는 192.168.1.0부터 192.168.1.255까지의 IP 주소를 포함하는 서브넷을 의미합니다. 이 경우 256개의 IP 주소를 사용할 수 있으므로, 1,000개가 필요한 경우에는 여러 개의 서브넷을 만들어 사용하면 됩니다. 서브넷 마스크의 IP 갯수 계산 방법은 다음과 같습니다. IP주소는 총 32개의 비트로 구성되는데 32에서 서브넷 마스크를 뺀 숫자 만큼의 비트가 호스트 비트가 됩니다. 예를 들어 /24 서브넷 마스크라면 32-24=8이 되고, 2의 8제곱인 256에서 2를 뺀 254개 만큼의 호스트 수를 갖게 됩니다. 2를 빼는 이유는 첫 번째 값은 해당 네트워크 전체를 나타내는 네트워크 주소로, 마지막 값은 해당 네트워크에 속한 모든 호스트를 의미하는 브로드캐스트 주소로 사용되기 때문입니다.
기본 네트워크 ACL
기본 네트워크 ACL은 VPC를 처음 생성할 때 자동으로 만들어지는 ACL로, 서브넷에 들어오고 나가는 모든 트래픽을 허용합니다. 기본 네트워크 ACL이 있으면 모든 통신이 자유롭게 이루어지기 때문에 별도의 설정을 하지 않더라도 VPC를 바로 사용할 수 있어서 편리합니다. 하지만 모든 트래픽이 허용되기 때문에 실제로 VPC를 사용하기 전에는 올바른 규칙을 생성하는 것이 보안 상 안전합니다.
기본 네트워크 ACL은 다음과 같이 생성됩니다. 규칙 번호가 작은 규칙부터 먼저 적용되고, 규칙 번호가 *인 경우는 다른 모든 규칙이 일치하지 않을 때 해당 트래픽을 거부한다는 의미입니다. * 규칙은 삭제하거나 수정할 수 없습니다.
인바운드
규칙 # Type 프로토콜 포트 범위 소스 허용/거부 100 모든 IPv4 트래픽 모두 모두 0.0.0.0/0 ALLOW * 모든 IPv4 트래픽 모두 모두 0.0.0.0/0 DENY 아웃바운드
규칙 # Type 프로토콜 포트 범위 대상 주소 허용/거부 100 모든 IPv4 트래픽 모두 모두 0.0.0.0/0 ALLOW * 모든 IPv4 트래픽 모두 모두 0.0.0.0/0 DENY 다음은 연결된 IPv6 CIDR 블록이 있는 VPC에 대한 사용자 지정 네트워크 ACL 예시입니다. 이 네트워크 ACL에는 모든 IPv6 HTTP 및 HTTPS 트래픽에 대한 규칙이 포함됩니다. IPv4 및 IPv6 트래픽은 분리되어 있어서 IPv4 트래픽에 대한 규칙 중 어느 것도 IPv6 트래픽에 적용되지 않습니다.
인바운드
규칙 # Type 프로토콜 포트 범위 소스 허용/거부 설명 100 HTTP TCP 80 0.0.0.0/0 ALLOW 어떤 IPv4 주소에서 이루어지는 인바운드 HTTP 트래픽도 모두 허용 105 HTTP TCP 80 ::/0 ALLOW 어떤 IPv6 주소에서 이루어지는 인바운드 HTTP 트래픽도 모두 허용 110 HTTPS TCP 443 0.0.0.0/0 ALLOW 어떤 IPv4 주소에서 이루어지는 인바운드 HTTPS 트래픽도 모두 허용 115 HTTPS TCP 443 ::/0 ALLOW 어떤 IPv6 주소에서 이루어지는 인바운드 HTTPS 트래픽도 모두 허용 120 SSH TCP 22 192.0.2.0/24 ALLOW 홈 네트워크의 퍼블릭 IPv4 주소 범위로부터의 인바운드 SSH 트래픽 허용 130 RDP TCP 3389 192.0.2.0/24 ALLOW 홈 네트워크의 퍼블릭 IPv4 주소 범위로부터 웹 서버로의 인바운드 RDP 트래픽 허용 140 사용자 지정 TCP TCP 32768-65535 0.0.0.0/0 ALLOW 인터넷으로부터의 인바운드 리턴 IPv4 트래픽 허용 145 사용자 지정 TCP TCP 32768-65535 ::/0 ALLOW 인터넷으로부터의 인바운드 리턴 IPv6 트래픽 허용 * 모든 트래픽 모두 모두 0.0.0.0/0 DENY * 모든 트래픽 모두 모두 ::/0 DENY 아웃바운드
규칙 # Type 프로토콜 포트 범위 대상 주소 허용/거부 설명 100 HTTP TCP 80 0.0.0.0/0 ALLOW 서브넷에서 인터넷으로의 아웃바운드 IPv4 HTTP 트래픽 허용 105 HTTP TCP 80 ::/0 ALLOW 서브넷에서 인터넷으로의 아웃바운드 IPv6 HTTP 트래픽 허용 110 HTTPS TCP 443 0.0.0.0/0 ALLOW 서브넷에서 인터넷으로의 아웃바운드 IPv4 HTTPS 트래픽 허용 115 HTTPS TCP 443 ::/0 ALLOW 서브넷에서 인터넷으로의 아웃바운드 IPv6 HTTPS 트래픽 허용 140 사용자 지정 TCP TCP 32768-65535 0.0.0.0/0 ALLOW 인터넷에서 클라이언트에 대한 아웃바운드 IPv4 응답 허용 145 사용자 지정 TCP TCP 32768-65535 ::/0 ALLOW 인터넷에서 클라이언트에 대한 아웃바운드 IPv6 응답 허용 * 모든 트래픽 모두 모두 0.0.0.0/0 DENY * 모든 트래픽 모두 모두 ::/0 DENY ACL와 보안 그룹 비교
특징 ACL 보안 그룹 적용 범위 서브넷 인스턴스 규칙 종류 인바운드/아웃바운드 인바운드/아웃바운드 상태 상태 없음(stateless) 상태 존재(stateful) 규칙 순서 중요 중요 요약
AWS 네트워크의 핵심은 클라우드 인프라를 구성하는 기본 요소와 보안 메커니즘을 이해하는 것입니다.
리전, 가용 영역, VPC, 서브넷, 인터넷 게이트웨이 등을 사용해 AWS에서 네트워크 아키텍처를 구성할 수 있습니다.
보안 그룹과 ACL을 사용하면 네트워크 트래픽을 제어하고 리소스를 보호할 수 있습니다.
퀴즈
문제 1
AWS에서 "리전(Region)"과 "가용 영역(Availability Zone, AZ)"의 관계에 대한 설명으로 올바른 것은 무엇인가요?
A. 하나의 리전에는 반드시 하나의 가용 영역만 존재한다.
B. 가용 영역은 서로 다른 리전에 속할 수 있다.
C. 하나의 리전에는 여러 개의 가용 영역이 존재하며, 각 AZ는 독립적인 데이터센터다.
D. 가용 영역은 리전과 상관없이 자유롭게 생성할 수 있다.
정답: C
해설: AWS의 한 리전에는 여러 개의 가용 영역이 존재하며, 각 AZ는 독립적으로 운영되는 데이터센터입니다.
문제 2
Amazon VPC(Virtual Private Cloud)에 대한 설명으로 옳지 않은 것은 무엇인가요?
A. VPC는 논리적으로 격리된 가상 네트워크 환경을 제공한다.
B. VPC 내에서 서브넷을 생성해 네트워크를 분할할 수 있다.
C. VPC는 여러 리전에 걸쳐 확장할 수 있다.
D. VPC는 인터넷 게이트웨이를 연결해 외부 인터넷과 통신할 수 있다.
정답: C
해설: VPC는 하나의 리전 내에서만 생성 및 운영할 수 있으며, 여러 리전에 걸쳐 확장할 수 없습니다.
문제 3
퍼블릭 서브넷과 프라이빗 서브넷의 차이에 대한 설명으로 올바른 것은 무엇인가요?
A. 퍼블릭 서브넷은 인터넷 게이트웨이와 연결되어 외부와 직접 통신이 가능하다.
B. 프라이빗 서브넷은 인터넷 게이트웨이와 연결되어 외부와 직접 통신이 가능하다.
C. 퍼블릭 서브넷은 외부와 통신할 수 없고, 프라이빗 서브넷만 인터넷 접속이 가능하다.
D. 퍼블릭과 프라이빗 서브넷 모두 인터넷 게이트웨이 없이 외부와 통신할 수 있다.
정답: A
해설: 퍼블릭 서브넷은 인터넷 게이트웨이와 연결되어 외부 인터넷과 직접 통신할 수 있습니다. 프라이빗 서브넷은 직접 통신이 불가능합니다.
문제 4
보안 그룹(Security Group)과 네트워크 ACL(Network ACL)의 차이점으로 올바른 것은 무엇인가요?
A. 보안 그룹은 서브넷 단위로 동작하고, 네트워크 ACL은 인스턴스 단위로 동작한다.
B. 보안 그룹은 상태 저장(Stateful) 방식이고, 네트워크 ACL은 상태 비저장(Stateless) 방식이다.
C. 보안 그룹은 허용과 거부 규칙을 모두 설정할 수 있다.
D. 네트워크 ACL은 인스턴스별로 각각 적용된다.
정답: B
해설: 보안 그룹은 상태 저장(Stateful) 방식으로 동작하며, 네트워크 ACL은 상태 비저장(Stateless) 방식으로 동작합니다.
문제 5
VPC에서 외부 인터넷과의 통신을 위해 반드시 필요한 네트워크 장치는 무엇인가요?
A. NAT 게이트웨이
B. 라우팅 테이블
C. 인터넷 게이트웨이
D. 보안 그룹
정답: C
해설: VPC에서 외부 인터넷과 통신하려면 반드시 인터넷 게이트웨이를 연결해야 합니다.
4장 API 서버 구축하기
4장에서는 웹 애플리케이션의 핵심인 백엔드 API 서버를 AWS 환경에서 구축하는 방법을 다룹니다. EC2와 Lambda 등 AWS의 대표적인 컴퓨팅 서비스를 비교하고, 각각의 환경에서 Python 기반 FastAPI 서버를 구축하는 실습을 진행합니다. 도커와 ECR을 활용한 컨테이너 배포, API Gateway를 통한 서버리스 아키텍처 구현, 그리고 EC2/Lambda 환경에서 S3, RDS 등 주요 AWS 서비스와의 연동 방법을 익힙니다. 이를 통해 실제 서비스 운영에 필요한 API 서버 구축과 배포, 그리고 AWS 서비스 간의 통합 방법을 실전 중심으로 학습할 수 있습니다.
[1] API의 개념
API(Application Programming Interface)는 서로 다른 프로그램들이 데이터를 주고받을 수 있도록 연결해주는 인터페이스입니다. 웹 서비스에서는 백엔드 서버가 제공하는 기능을 통해 웹 브라우저나 모바일 앱 같은 프론트엔드와 데이터를 주고받을 수 있으며, 이러한 서버를 API 서버라고 부릅니다.
예를 들어, 웹 프론트엔드인 웹 브라우저에서 백엔드 서버로 API를 사용해 요청(Request)을 보내는 경우를 생각해 보겠습니다. 백엔드는 데이터베이스(Database)에서 프론트엔드가 요청한 데이터를 추출합니다. 추출된 데이터는 API의 응답(Response)으로 프론트엔드에 전달됩니다. API를 통해 회원 정보, 상품 정보와 같은 데이터를 요청할 수 있고, 새로운 회원이나 상품을 등록하도록 요청할 수도 있습니다. 결론적으로 API는 웹 서비스에서 매우 중요한 역할을 수행하고 있습니다. 따라서 API를 제공하는 백엔드 서버를 AWS에서 어떻게 구성하는지는 매우 중요한 문제입니다. 이제 AWS에서 백엔드 서버를 구성할 수 있는 여러 가지 방법을 살펴보고, 직접 서버를 배포해 보도록 하겠습니다.
[2] AWS의 컴퓨팅 서비스
백엔드 서버를 구성하기 위해서는 서버가 구동될 컴퓨팅 환경을 먼저 구축해야 합니다. 만일, 노트북이나 데스크톱에서 서버를 구성하고자 한다면, 먼저 리눅스 운영 체제를 설치하고, 리눅스 환경에서 서버를 구성해야 합니다. 그러나 AWS에서는 운영 체제와 필요한 라이브러리가 설치된 서버 컴퓨터를 바로 제공하기 때문에 이러한 과정을 생략할 수 있습니다. 몇 번의 클릭으로 AWS에서 제공하는 컴퓨팅 환경에서 서버를 구축할 수 있다는 점이 AWS 컴퓨팅 서비스의 장점입니다. 이외에도 AWS 컴퓨팅 서비스의 장점을 정리하면 다음과 같습니다.
신속성 : 클라우드를 사용하면 서버를 빠르게 만들 수 있기 때문에 새로운 기술을 좀더 쉽고 빠르게 사용할 수 있습니다. 컴퓨팅, 스토리지, 데이터베이스와 같은 인프라 서비스부터 사물 인터넷(IoT), 머신 러닝 등에 필요한 리소스를 신속하게 생성할 수 있습니다.
탄력성 : 클라우드를 사용하면 순간적으로 늘어나는 높은 트래픽을 처리하기 위해 미리 리소스를 준비할 필요가 없습니다. 대신 필요한 만큼의 리소스를 실시간으로 생성하면 됩니다. 즉, 리소스를 유연하게 확장하거나 축소해서 비즈니스 요구사항을 빠르게 충족시킬 수 있습니다.
비용 절감 : 클라우드를 사용하면 데이터 센터 또는 물리적 서버를 유지하는데 소모되는 고정 비용을 변동 비용으로 바꿀 수 있습니다. 사용한 만큼만 비용을 지불하기 때문에 매우 낮은 초기 비용으로 서비스를 시작할 수 있습니다.
빠른 배포 : 클라우드를 사용하면 몇 분 안에 서비스를 전 세계에 배포할 수 있습니다. AWS는 전 세계에 인프라를 보유하고 있으므로 클릭 몇 번으로 여러 물리적 위치에 애플리케이션을 배포할 수 있습니다. 예를 들어, 한국 세어 서비스를 개발했지만 사용자가 미국에 있는 경우 미국에 서버를 구축해 두면 고객의 요청에 좀더 신속하게 반응할 수 있습니다.
EC2(Elastic Compute Cloud)
AWS EC2는 클라우드 컴퓨팅 환경에서 탄력적인 컴퓨팅 자원을 제공하는 서비스입니다. 다양한 인스턴스 유형과 운영체제를 지원하며, 자동 확장 기능을 통해 처리 능력이 변화하는 경우에도 유연하게 대응할 수 있습니다. 특히, 99.99%의 높은 가용성 SLA를 제공하여 서비스 중단 없이 지속적인 운영이 가능합니다.
NOTE: SLA(Service Level Agreement)
SLA는 서비스 제공자와 고객 간에 서비스의 품질, 가용성, 성능 등에 대한 약정을 담은 계약입니다. 쉽게 말해, 서비스 제공자가 고객에게 약속하는 서비스 수준을 명시한 계약서라고 할 수 있습니다. SLA에는 서비스 다운타임 허용 시간, 응답 시간, 문제 해결 시간 등이 포함됩니다.
SLI(Service Level Indicator)는 SLA에서 약속된 서비스 수준을 측정하기 위한 지표입니다. 예를 들어, 웹 사이트의 응답 시간, 시스템 가용성, 오류 발생 횟수 등이 SLI에 해당합니다. SLA에서 정의된 목표를 달성하고 있는지 확인하기 위해 SLI를 지속적으로 모니터링하고 관리해야 합니다. 정리하자면 SLA가 서비스 수준에 대한 목표라면, SLI는 그 목표를 달성하고 있는지 확인하기 위한 측정 지표라고 할 수 있습니다.
EC2는 일반적으로 컴퓨터 한 대를 빌리는 것과 비슷합니다. 윈도우, 리눅스, 맥OS등 원하는 운영 체제를 선택하면 해당 운영 체제가 설치된 컴퓨터를 받게 됩니다. 특히 리눅스의 경우 아마존에서 직접 관리하는 Amazon Linux 2를 비롯해 다양한 리눅스 배포판과 버전을 사용할 수 있습니다. 서버 구동에 필요한 설정과 소프트웨어를 설치하는 것은 사용자가 직접 해야합니다.
Lambda
Lambda는 EC2와는 다른 형태의 컴퓨팅 서비스로 서버리스(Serverless) 컴퓨팅 환경을 제공합니다. 서버리스 컴퓨팅 환경은 실제로 서버가 없다는 의미가 아니고, 사용자 입장에서 EC2와 같이 항상 작동중인 서버를 직접 관리할 필요가 없다는 의미입니다. Lambda는 사용자가 원하는 시점에 원하는 시간만큼만 컴퓨팅을 사용할 수 있는 서비스로 함수를 만들어서 필요할 때마다 함수를 실행하는 방식입니다. 만일, API 요청이 많지 않고 각 요청을 처리하는데 드는 시간이 길지 않다면 EC2의 경우 대부분의 시간을 아무런 작업도 하지 않는 상태로 있게 됩니다. EC2는 아무 작업을 하지 않더라도 작동 시간만큼 비용을 지불해야 하는 반면, Lambda는 사용한 시간만큼만 비용을 지불하면 됩니다. 따라서 이런 경우에는 Lambda를 사용하는 것이 EC2에 비해 비용을 절약할 수 있습니다.
다음의 3가지 컴퓨팅 서비스는 대규모 컨테이너 실행 환경이 필요할 때 사용하는 도구들로 각 서비스에 대해 자세히 설명하는 것은 이 책의 범위를 벗어납니다. 따라서 간략하게만 설명하고 넘어가겠습니다.
ECS(Elastic Container Service)
컨테이너화된 애플리케이션의 배포, 관리, 확장을 간소화하는 완전 관리형 컨테이너 오케스트레이션 서비스입니다. 컨테이너 오케스트레이션이란 컨테이너의 생성, 삭제, 상태 관리 등을 수행하는 작업을 말합니다. 애플리케이션과 필요한 리소스를 정의하기만 하면 ECS가 애플리케이션에 필요한 다른 AWS 서비스와 자동적으로 연결되어 작동합니다.
EKS(Elastic Kubernetes Service(EKS)
컨테이너 오케스트레이션 시스템의 한 종류인 쿠버네티스(Kubernetes)를 실행하기 위한 관리형 쿠버네티스 서비스입니다. 클라우드에서 EKS는 컨테이너 스케줄링, 애플리케이션 가용성 관리, 클러스터 데이터 저장 및 기타 주요 작업을 담당하는 쿠버네티스 컨트롤 플레인 노드의 가용성 및 확장성을 자동으로 관리합니다. EKS를 사용하면 AWS 인프라의 모든 성능, 확장성, 안정성 및 가용성을 활용할 수 있을 뿐만 아니라 AWS 네트워킹 및 보안 서비스와의 통합을 활용할 수 있습니다.
Fargate
서버를 관리할 필요 없이 애플리케이션 구축에만 집중할 수 있는 서버리스 종량제 컴퓨팅 엔진입니다. Fargate는 ECS 또는 EKS 위에서 동작합니다. OCI 호환 컨테이너 이미지를 선택하고, 메모리와 컴퓨팅 리소스를 정의하며 서버리스 컴퓨팅으로 컨테이너를 실행할 수 있습니다.
EC2 VS Lambda의 비교
API를 제공하는 백엔드 서버를 만들기 위해서 EC2와 Lambda 중 어떤 것을 사용해야 할까요? 두 가지 판단 기준을 적용해 볼 수 있습니다.
작동 시간에서 EC2는 항상 작동하는 서버를 사용하는 반면, Lambda는 필요한 시점에만 서버를 사용합니다. 따라서 항상 작동 중인 서버가 필요한 경우에는 EC2를 사용하고, 필요한 시점에만 서버가 필요한 경우에는 Lambda를 사용합니다. 예를 들어, 매일 정해진 시간 동안만 서버가 필요한 경우는 Lambda를 사용하면 됩니다. 반면 백그라운드 작업과 같이 지속적으로 작업을 수행하다가 사용자 요청에 응답해야 하는 경우에는 EC2가 적합합니다.
연산 능력에서 AWS Lambda의 최대 메모리는 3GB에 불과합니다. 함수에서 복잡한 연산을 수행하거나 많은 메모리가 필요한 경우 실행 시간이 길어져 비용이 증가할 수 있습니다. 여기에 시간 초과 문제가 발생하거나 메모리 부족으로 함수가 예상치 못하게 종료될 수도 있습니다. 반면 EC2는 이러한 제한이 없으므로 높은 성능이 필요한 상황에서 유용합니다.
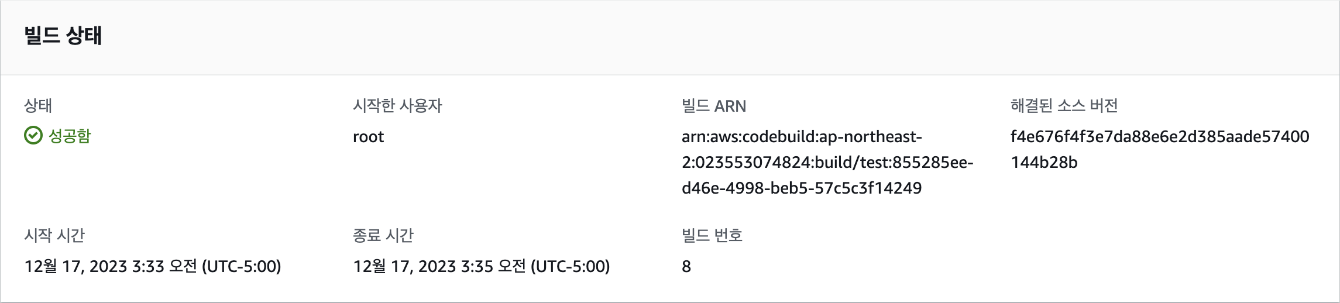
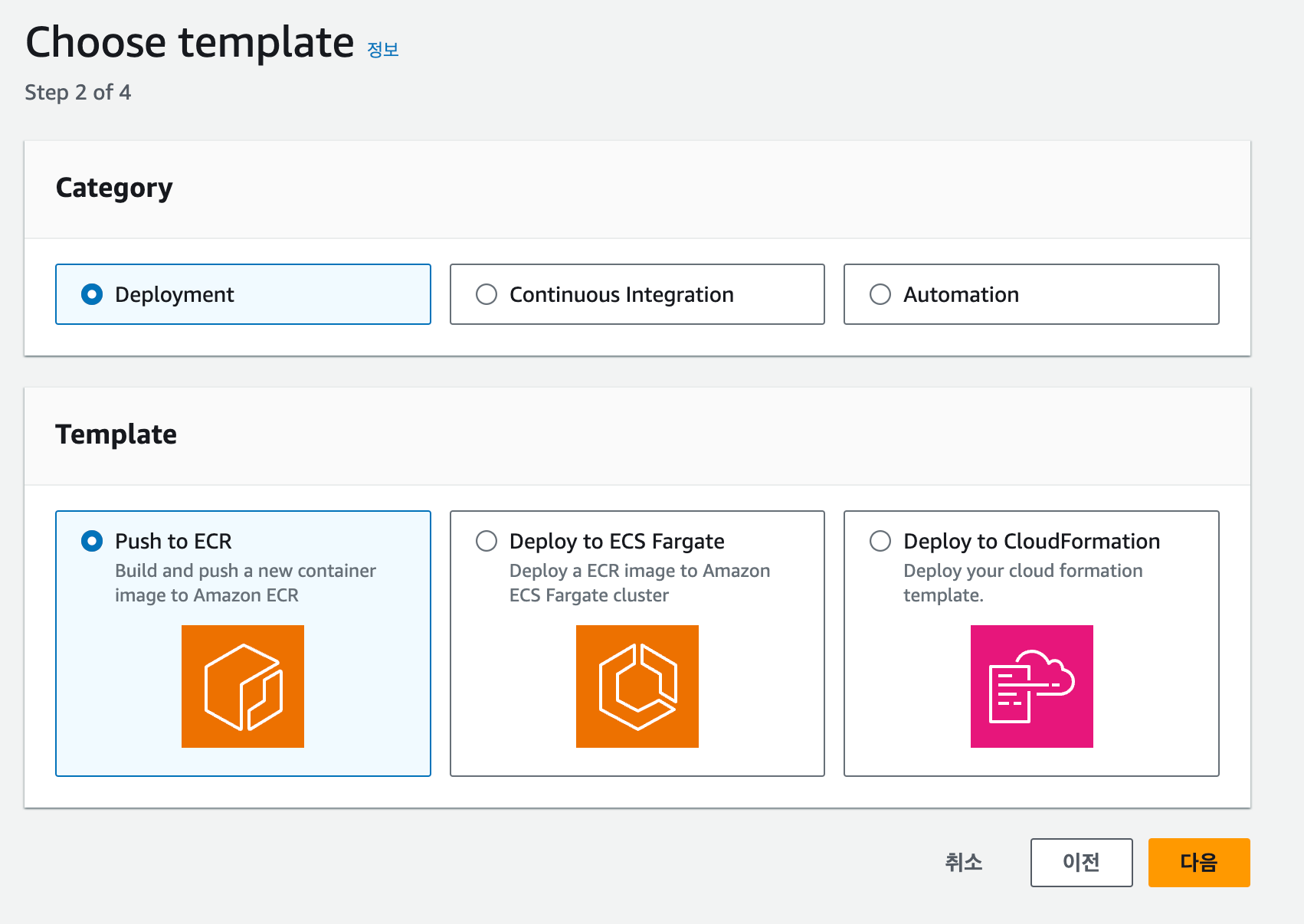
[3] EC2 우분투 서버 만들기
EC2를 이용해서 우분투 리눅스를 운영 체제로 사용하는 서버를 만들어 보겠습니다. 여기에서부터는 생성된 가상 서버를 인스턴스라고 부르겠습니다. 웹 브라우저에서 AWS Management Console에 로그인합니다. 검색란에 "EC2"를 검색해서 해당 서비스를 엽니다.
대시보드 링크 https://console.aws.amazon.com/ec2/home
EC2 인스턴스 생성하기
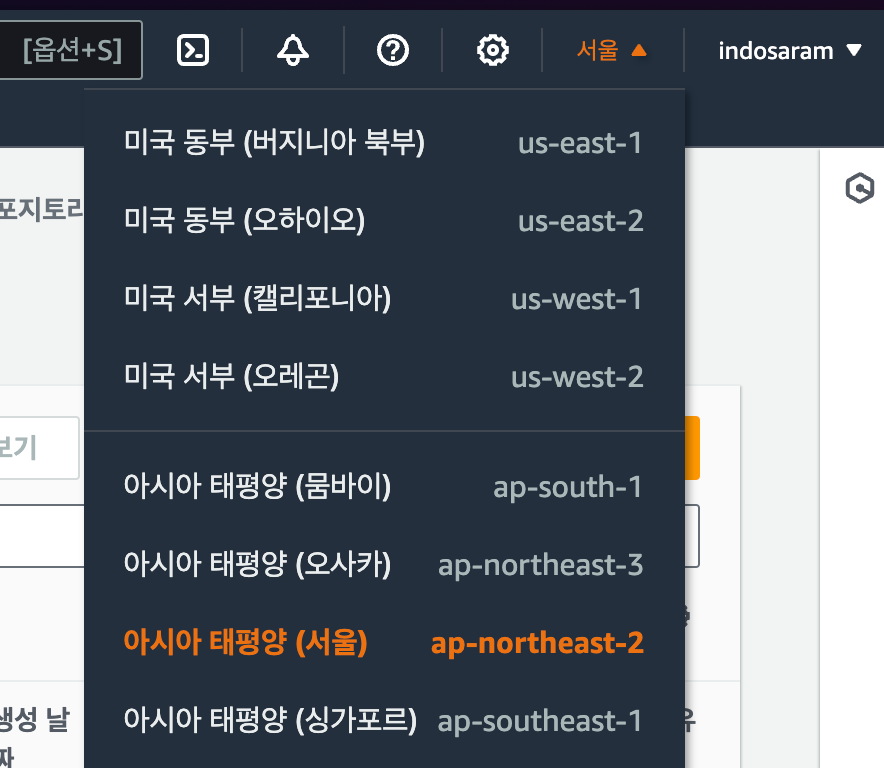
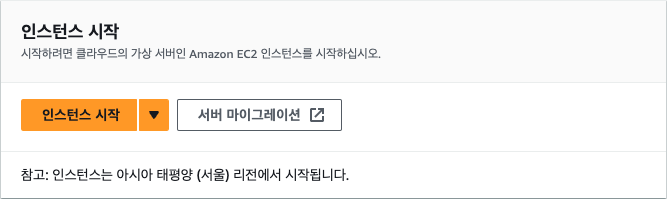
대시보드에서는 현재 리전이 올바르게 선택이 되었는지를 확인해야 합니다. 대한민국이 아닌 지역에 서버를 생성하고 싶은 경우가 아니라면, 서울 리전인 'ap-northeast-2'를 선택하면 됩니다.
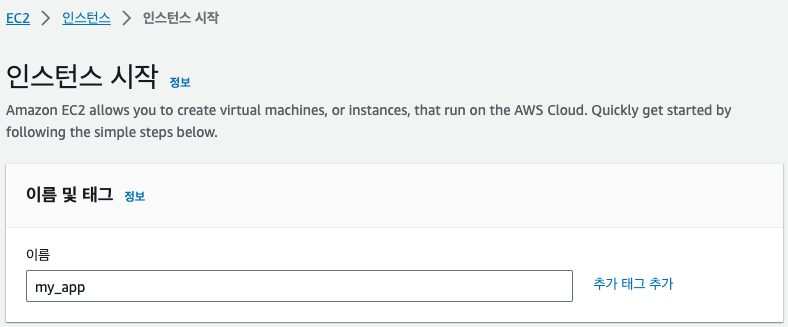
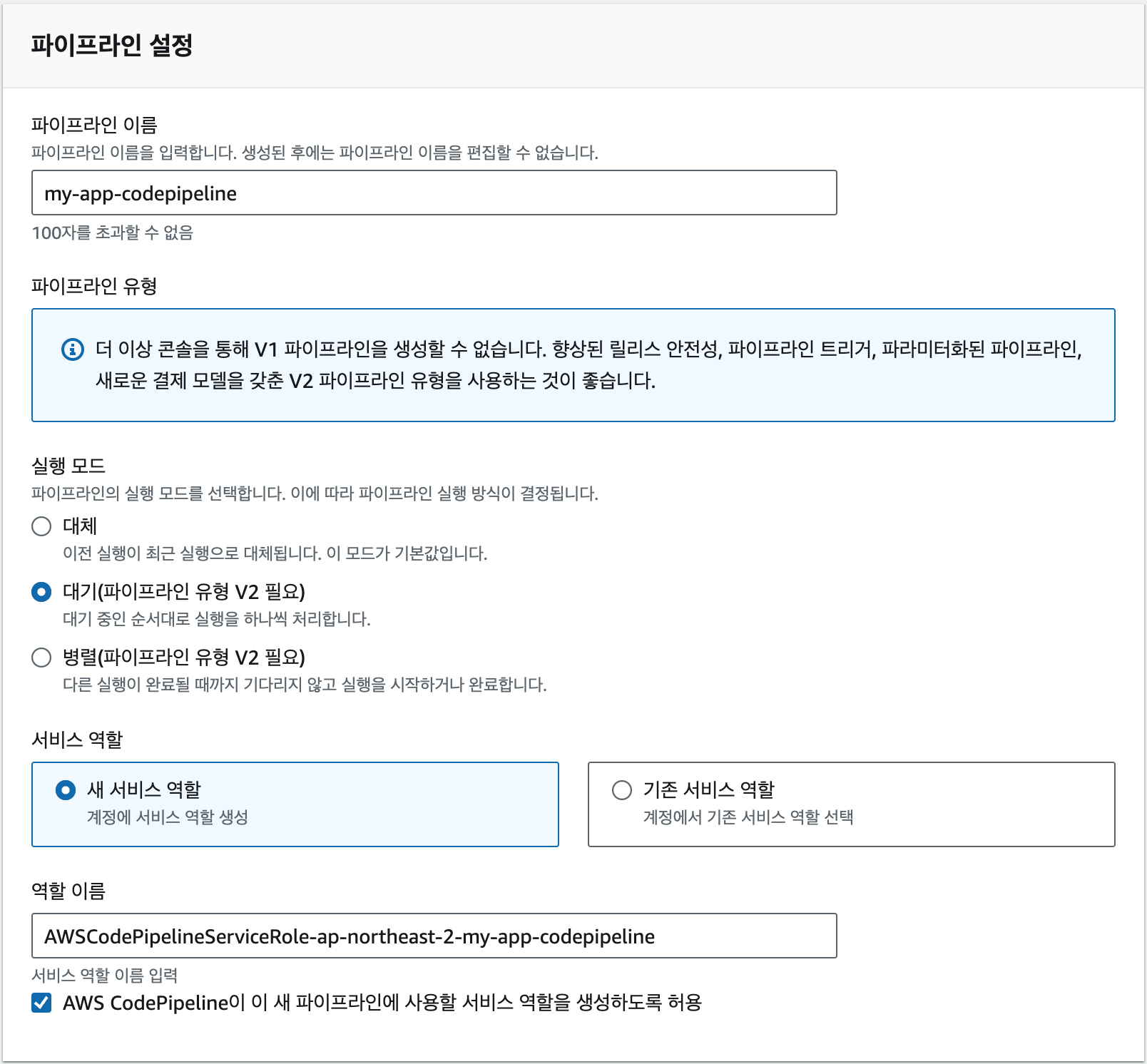
리전이 올바르게 선택되었다면 EC2 대시보드로 이동한 다음 [인스턴스 시작] 버튼을 클릭합니다. 여기서는 새로운 EC2 인스턴스 생성을 위한 설정을 입력하게 됩니다.
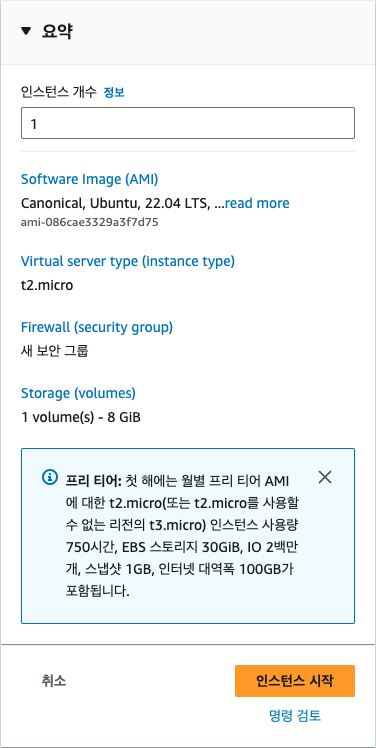
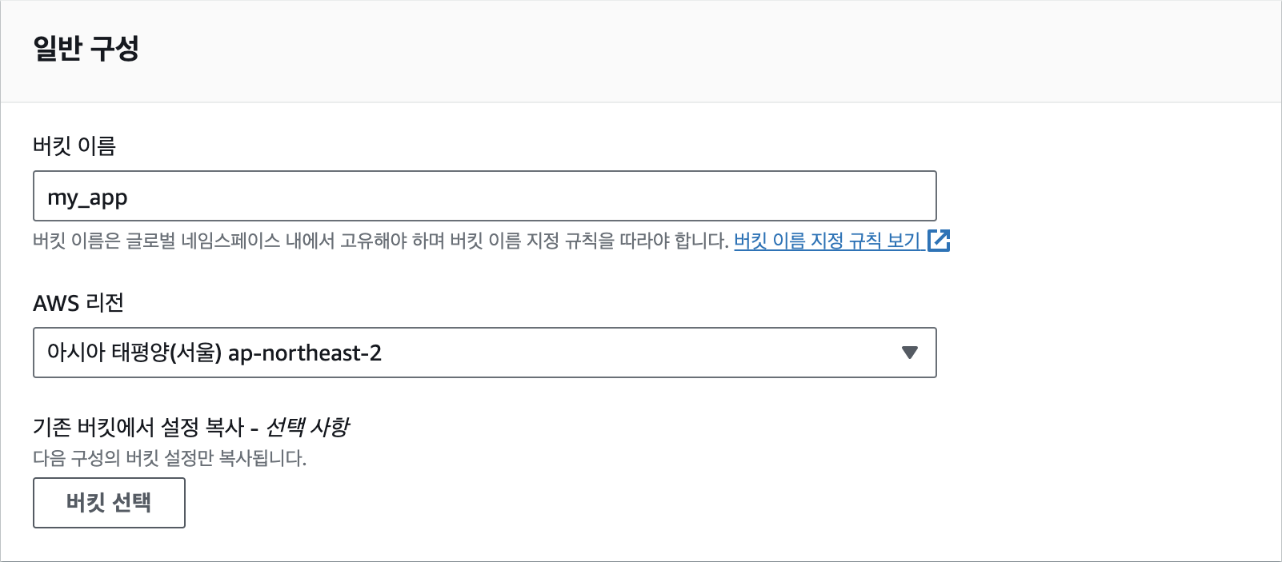
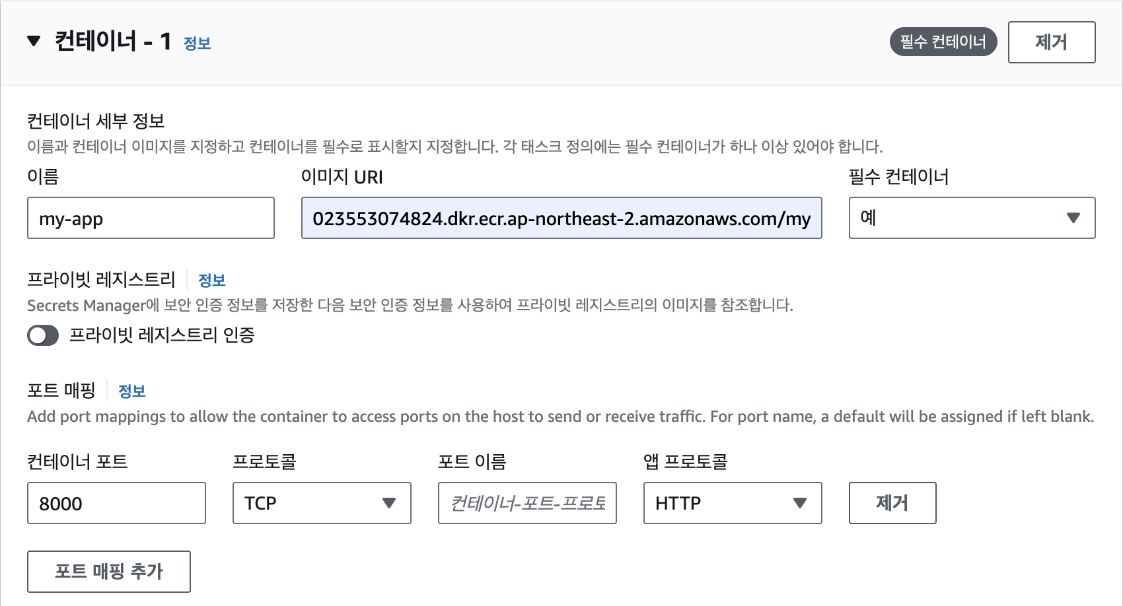
인스턴스 이름에 "my_app"를 입력하겠습니다. 인스턴스 이름은 나중에 인스턴스를 구분할 때 사용되므로 적절한 이름을 지정합니다.
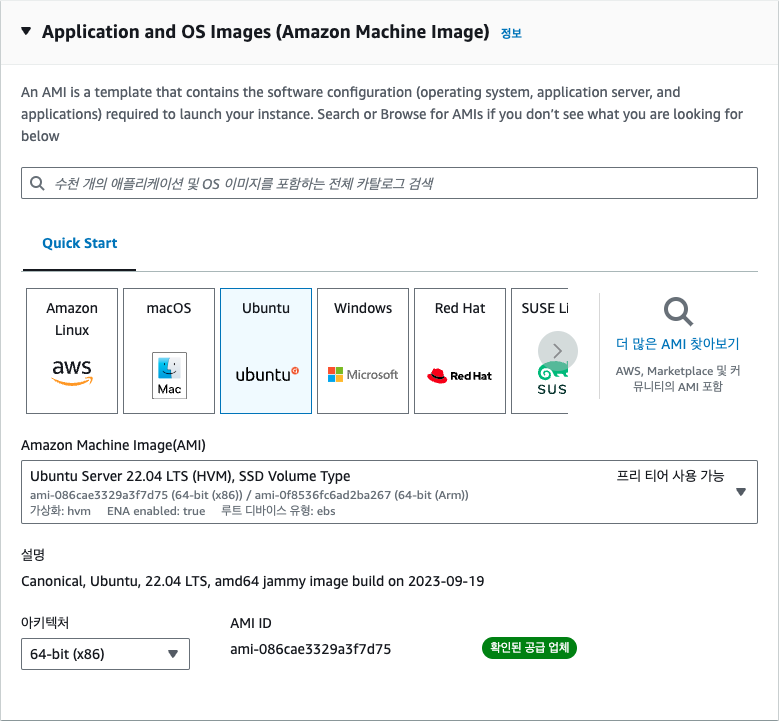
인스턴스 생성에 필요한 여러 가지 설정을 해야 합니다. 먼저, 사용할 운영 체제를 선택하되 여기에서는 가장 널리 사용되는 리눅스 배포판 중 우분투 리눅스를 사용해 보겠습니다. 우분투 리눅스를 선택한 후 AWS에서 EC2 사용을 쉽게 하기 위해 제공하는 운영 체제 이미지 AMI(Amazon Machine Image)를 선택합니다. 집필 시점에서 가장 최신 이미지인 22.04 LTS를 선택합니다. LTS(Long Term Service)는 우분투 재단에서 일정 기간 동안 해당 버전의 리눅스가 제대로 동작하도록 지원하는 안정화된 버전입니다. 22. 10과 같은 좀더 최신 버전의 이미지도 있지만, LTS 버전을 선택하는 것이 서비스를 운영할 때에는 좀더 안정적입니다. 그 다음으로 아키텍처는 [64-bit(x86)]을 선택합니다.
그 다음으로 인스턴스 유형을 선택합니다. 인스턴스 유형이란 AWS에서 CPU, 메모리 크기에 따라 미리 지정해 놓은 인스턴스의 종류를 의미합니다. AWS EC2 인스턴스 유형은 하드웨어 유형과 제공하는 기능에 대한 정보에서 명명 규칙을 따릅니다. 이름을 기준으로 인스턴스 유형을 분류하는 방법은 다음과 같습니다.
- 유형 접두사 : 첫 글자는 적합한 또는 최적화된 용도를 나타냅니다(- c=컴퓨트, m=일반/메인, r=메모리, i=IOPS/스토리지, g=그래픽, p=GPU, f=FPGA).
- 세대 : 숫자는 최신/고급 세대를 나타내며, 숫자가 높을수록 최신 세대입니다. 예를 들어, m4보다 m5가 최신 세대입니다.
- 유형 크기 : 점 뒤의 부분은 nano, micro, small, medium, large, xlarge, 2xlarge 등 제품군 내의 상대적인 크기를 나타냅니다. X가 많을수록 더 큰 크기를 나타냅니다.
- 특수 유형 : 일부 접미사는 특수 하드웨어 또는 기능을 나타냅니다(n - 네트워크 최적화, x - 고용량(Extreme) 메모리, i - IOPS 최적화, e - 추가 저장 공간, a - ARM 기반 프로세서).
이를 적용한 몇 가지 예시는 다음과 같습니다.
- c5.9xlarge : 컴퓨팅 최적화, 5세대, 9xlarge 크기 - g4dn.xlarge : 그래픽 최적화, 4세대, 네트워크 최적화, 대형 사이즈 - r6i.32xlarge : 메모리 최적화, 지역 스토리지, 6세대, 32xlarge 크기접두사, 세대 번호, 크기 용어 및 특수 접미사를 알고 있으면 EC2 인스턴스 유형이 제공하는 하드웨어 유형, 기능 및 특성을 대략적으로 파악할 수 있습니다. 여기에서는 인스턴스 유형을 t2.micro로 선택합니다. 앞에서 설명한 것처럼 AWS 프리 티어에서 t2.micro를 사용하면 1년 동안 무료로 사용할 수 있습니다. t2.micro는 메모리가 1GB이고, CPU는 1개입니다. 이 정도 사양이면 일반적인 웹 서비스를 구축하는데 충분합니다. 만일, 더 높은 사양의 인스턴스를 사용하고 싶다면 CPU나 메모리가 더 큰 인스턴스 유형을 선택하면 되지만 이런 경우에는 추가적인 비용이 발생합니다.
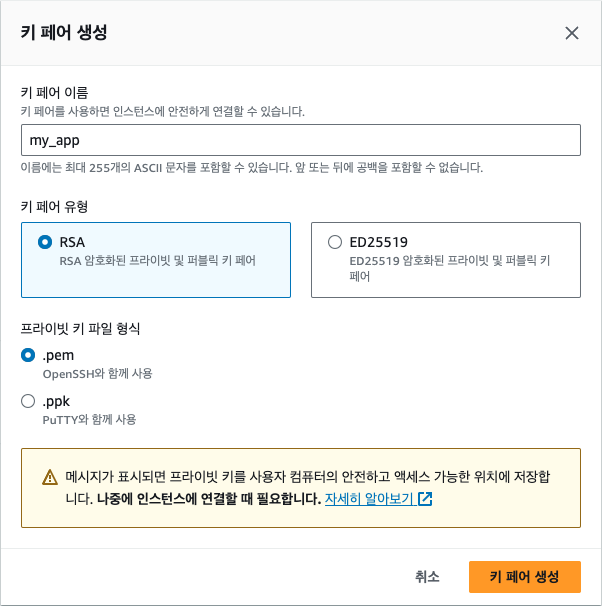
EC2 인스턴스는 가상 컴퓨터이기 때문에 EC2에 로그인해 작업을 하기 위한 인증 수단인 키 페어(Key pair)가 필요합니다. 키 페어란 공개 키(Public key)와 개인 키(Private key)로 구성된 쌍으로 공개 키는 EC2에 저장되고, 개인 키는 사용자가 보관합니다. EC2에 접속할 때는 개인 키를 사용합니다. 기존에 생성해둔 키 페어가 없다면 새로운 키 페어를 생성해야 합니다. 키 페어를 생성하려면 우측의 '새 키 페어 생성'을 클릭합니다.
키 페어 이름은 기억하기 쉬운 이름으로 지정하는데 여기에서는 'my_app'으로 정했습니다. 키 페어 유형은 키에 저장되는 인증 정보에서 암호화할 알고리즘을 선택하는 것인데, 여기에서는 RSA 방식을 선택했지만 ED25519를 선택해도 됩니다. 프라이빗 키 파일 형식으로는 추후 SSH 연결을 위해 '.pem'을 선택합니다. [키 페어 생성] 버튼을 클릭하면 my_app.pem 파일이 다운로드됩니다. pem 키 파일은 한 번 다운로드하면 다시 발급받을 수 없으므로 반드시 안전한 위치에 저장해 둡니다. 만일, 키 파일을 분실한 경우는 기존 키 페이를 삭제하고, 새로운 키 페어를 생성해야 합니다.
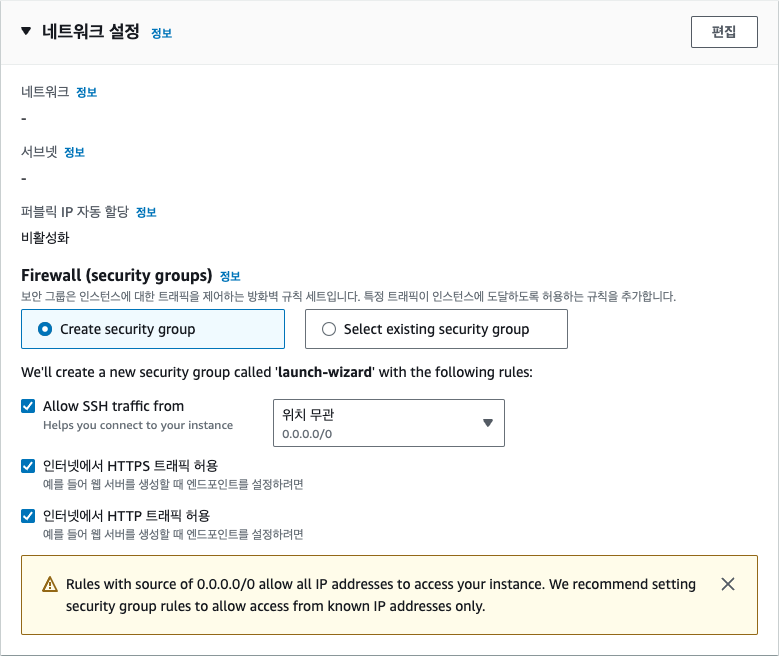
그 다음으로는 EC2에 네트워크를 연결하기 위해 보안 그룹을 선택해야 합니다. 보안 그룹은 EC2 인스턴스에 접근할 수 있는 IP 주소를 제한하는 방화벽 역할을 합니다. 여기에서는 모든 IP 주소에서 접근을 허용하도록 설정했습니다. 이렇게 설정하면 어디서든 EC2 인스턴스에 접근할 수 있습니다. 보안 그룹은 나중에 필요에 따라 수정할 수 있으므로 지금은 모든 IP 주소에서 접근을 허용하는 것으로 설정합니다.
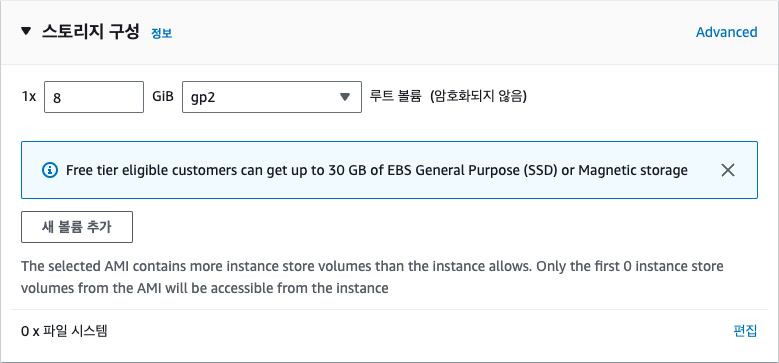
스토리지는 컴퓨터에서 파일을 저장할 수 있는 공간으로 EC2 인스턴스에는 여러 가지 스토리지 옵션을 선택할 수 있습니다. 여기에서는 기본적으로 제공되는 8GB의 스토리지를 사용하겠습니다. 프리 티어에서는 최대 30GB까지 무료로 사용할 수 있습니다.
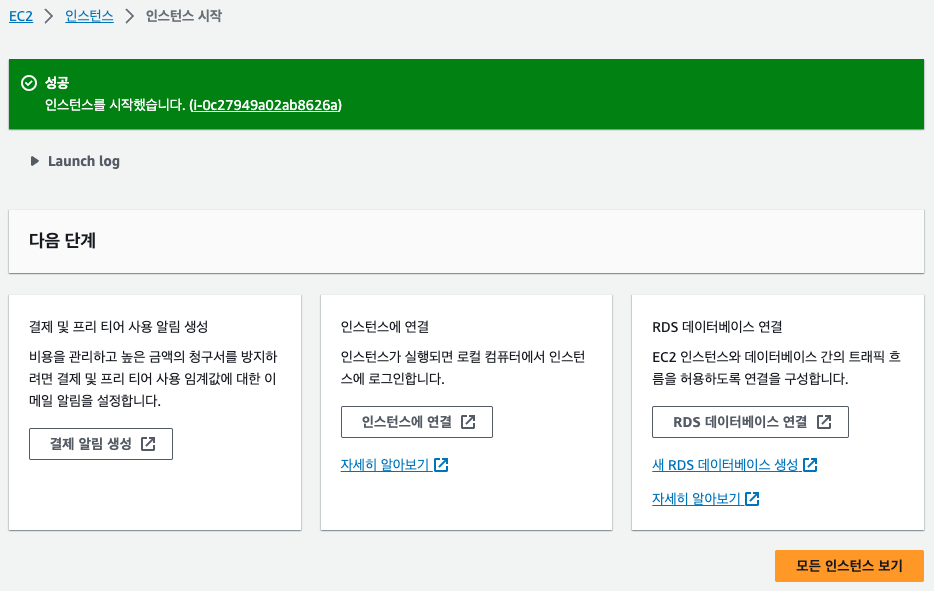
인스턴스 개수는 동일한 설정으로 여러 개의 인스턴스를 생성할 때 사용하는 옵션입니다. 여기에서는 1개만 생성하겠습니다. [인스턴스 시작] 버튼을 클릭하면 인스턴스가 생성됩니다.
[모든 인스턴스 보기] 버튼을 클릭하면 생성된 인스턴스를 확인할 수 있습니다.
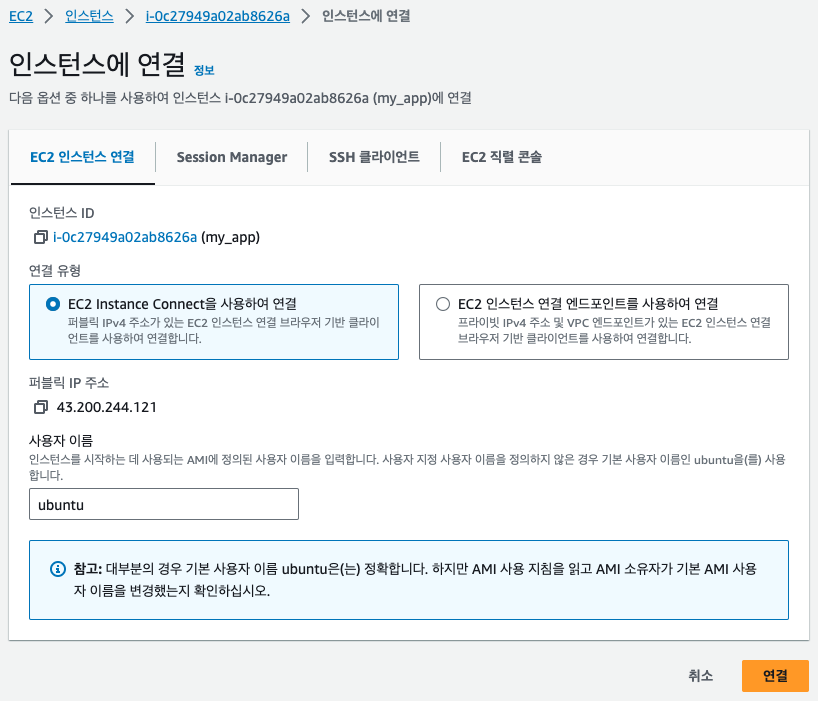
생성된 서버에 접속하기 위해 방금 생성한 인스턴스를 선택하고, [연결] 버튼을 클릭합니다.
[EC2 인스턴스 연결] 탭의 하단에서 [연결] 버튼을 클릭하면 해당 인스턴스 터미널에 접속하게 됩니다.
방금 다운로드 받은 pem 키를 사용해 SSH(Secure Shell) 접속을 할 수도 있습니다. SSH를 사용하면 AWS 콘솔에 로그인할 필요 없이 EC2 머신에 바로 연결할 수 있어 편리합니다. 다만, 접속할 컴퓨터의 22번 포트가 열려 있어야 접속이 가능합니다. AWS EC2의 경우 기본적으로 22번 포트가 열려 있습니다. SSH 접속은 대부분의 리눅스와 맥 운영 체제의 터미널에서 기본적으로 제공되기 때문에 다음과 같이 입력하면 됩니다.
$ ssh -i my_app.pem ubuntu@my_server_ip만일, 윈도우 사용자 중
ssh명령어가 없다는 에러가 발생하면 명령 프롬프트가 아닌 'PowerShell' 또는 'PowerShell Core'를 사용합니다. PowerShell은 윈도우에서 기본적으로 제공되는 터미널 프로그램입니다. PowerShell에서 위의 명령어를 그대로 사용하면 됩니다. 만일, Powershell Core를 설치하려면 다음의 링크로 접속합니다.https://github.com/PowerShell/PowerShell
일부 블로그나 강의 등에서는 PuTTy라는 도구를 사용하라고 알려주는 경우가 있는데 이는 사용법도 불편하고 오래된 프로그램인 데다, 윈도우가 아닌 다른 운영 체제에서는 사용할 수 없는 방법이라 추천하지 않습니다.
파이썬으로 FastAPI 서버 만들기
이번에는 EC2 인스턴스에 파이썬 FastAPI 서버를 만들고 실행시켜 보겠습니다. 먼저 우분투 리눅스의 패키지를 업데이트합니다. 처음 업데이트는 시간이 약간 소요됩니다. 코드의 첫 번째 줄 sudo update-alternatives --install /usr/bin/python python /usr/bin/python3 10은 python 명령어에 대한 대체 프로그램을 설정합니다. 이 명령어는 python 명령어를 실행할 때 python3를 사용하도록 지정합니다. 많은 리눅스 운영체제에서는 python 명령어를 파이썬 2.7버전에 사용하고 python3을 파이썬 3.X 버전에 사용하고 있기 때문에 python 명령을 입력하면 python3를 실행하도록 편의성을 위해 바꾸어주는 것입니다. 마지막의 숫자 10은 우선순위를 나타내며, 더 높은 숫자, 즉 높은 우선순위를 갖는 프로그램이 있다면 해당 프로그램이 대신 사용됩니다.
두 번째 줄 sudo apt-get update는 패키지 목록을 업데이트하고, 세 번째 줄 sudo apt-get install -y python3-pip은 python3-pip 패키지를 설치합니다. 이 패키지는 Python 3용 pip 패키지 관리자를 설치합니다.
마지막 줄 sudo update-alternatives --install /usr/bin/pip pip /usr/bin/pip3 10은 pip 명령어에 대한 대체 프로그램을 설정합니다. 이 명령어는 pip 명령어를 실행할 때 pip3를 사용하도록 지정합니다. 파이썬과 마찬가지로 pip3 대신 pip이라는 짧은 이름을 사용하기 위해 이렇게 지정합니다.
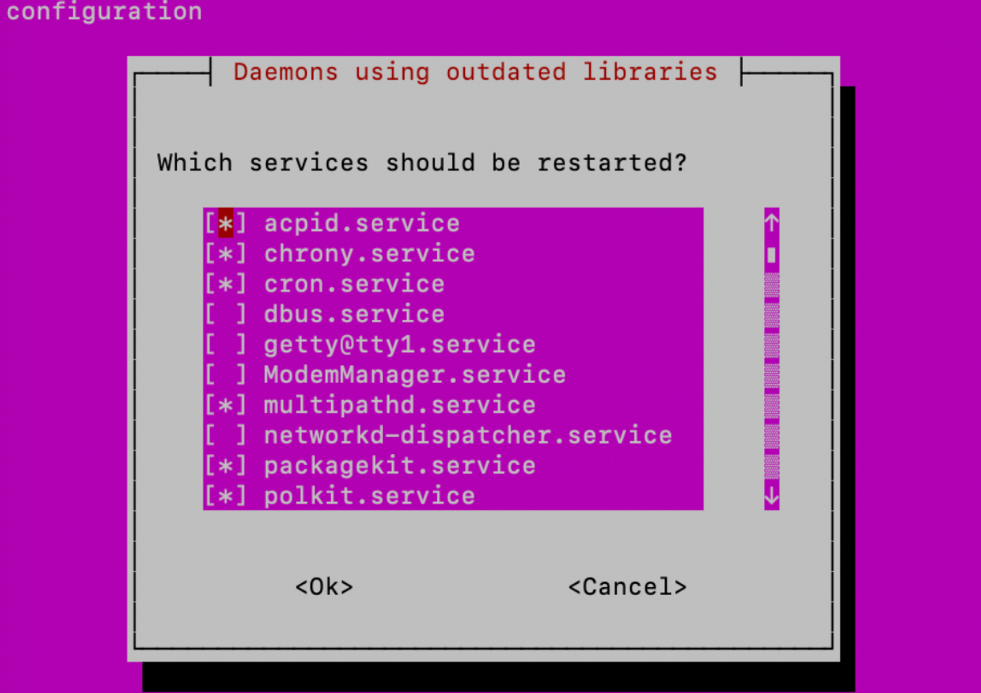
# python3 -> python $ sudo update-alternatives --install /usr/bin/python python /usr/bin/python3 10 # pip3 -> pip $ sudo apt-get update $ sudo apt-get install -y python3-pip $ sudo update-alternatives --install /usr/bin/pip pip /usr/bin/pip3 10진행 중 다음과 같은 화면이 나타나면 'OK'를 선택한 후 [Enter] 키를 눌러 창을 닫기 합니다. 운영 체제에 백그라운드로 실행 중인 프로그램을 재시작한다는 말인데, 우리는 아직 아무 프로그램도 실행중이지 않기 때문에 재시작해도 상관이 없습니다. 아래 그림에 대한 설명이 맞나요?
다음으로는 FastAPI와 uvicorn를 설치합니다. FastAPI는 파이썬으로 작성된 현대적이고 빠른 웹 프레임워크입니다. API 개발에 최적화되어 있으며, 높은 성능과 쉬운 학습이라는 두 마리 토끼를 모두 잡았습니다. FastAPI는 타입 힌트를 적극 활용하여 코드의 안정성을 높이고, 자동으로 OpenAPI 문서를 생성하여 API를 개발하고 관리하는 과정을 효율적으로 만들어 줍니다. 또한, 비동기 처리를 지원하여 많은 양의 요청을 동시에 처리할 수 있으며, 데이터 검증 기능을 통해 안전하고 신뢰할 수 있는 API를 개발할 수 있도록 도와줍니다. 마치 레고 블록을 쌓듯이 간단하고 직관적인 문법으로 복잡한 API를 빠르게 구축할 수 있다는 것이 FastAPI의 가장 큰 장점입니다.
Uvicorn은 파이썬으로 작성된 고성능의 ASGI(Asynchronous Server Gateway Interface) 서버입니다. 마치 웹 서버가 웹 브라우저와 통신하는 것처럼, Uvicorn은 FastAPI와 같은 웹 프레임워크가 외부의 요청을 받아들이고 처리할 수 있도록 연결해주는 역할을 합니다. 쉽게 말해, Uvicorn은 FastAPI가 만든 웹 애플리케이션을 실제로 인터넷에 연결하여 사용자들의 요청을 받고 응답을 보내는 역할을 담당하는, 마치 웹 애플리케이션의 문지기와 같은 존재라고 할 수 있습니다. Uvicorn은 빠른 속도와 효율적인 성능을 제공하여 많은 개발자들에게 사랑받는 ASGI 서버입니다.
다음 명령어는 파이썬 패키지 관리자인 pip를 사용하여 FastAPI 프레임워크와 Uvicorn ASGI 서버를 설치하는 명령입니다. 좀 더 자세히 설명하면, pip3 install 부분은 파이썬 3 버전에서 사용하는 패키지 설치 명령입니다. 그 뒤에 설치할 패키지 이름을 나열해주면 되는데, uvicorn[standard] 에서 [standard]는 중 표준 기능으로 설치하겠다는 의미입니다. 이렇게 기능을 설정할 떄에는 반드시 쌍따옴표로 전체 이름을 묶어주어야 합니다. 참고로 [standard]에는 개발에 유용한 여러 가지 기능과 더불어 가장 빠른 성능을 제공하는 uvloop라는 라이브러리가 들어있기 때문에 항상 [standard]를 빼놓지 않는 것이 좋습니다. 이제 이 명령어를 터미널에 입력해 패키지를 설치해주세요.
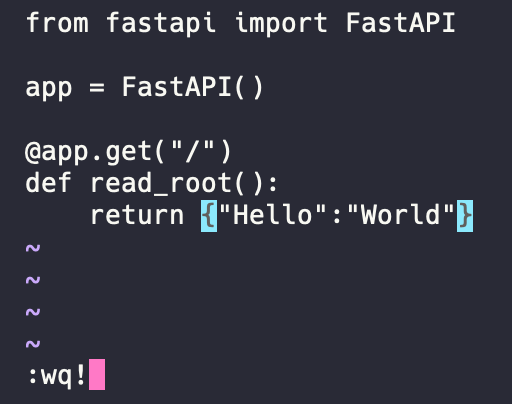
$ pip3 install fastapi "uvicorn[standard]"이제 FastAPI 서버를 만들어 보겠습니다. 서버를 만들기 위해서는 파이썬 코드를 작성해야 하고, 서버 코드를 작성하기 위해서는 텍스트 에디터가 필요합니다. 우분투 리눅스에는 기본적으로 vi 텍스트 에디터가 설치되어 있습니다. vi 텍스트 에디터를 사용해서 서버 코드를 작성해 보겠습니다. 다음 명령어를 터미널에 입력합니다.
$ vi main.py
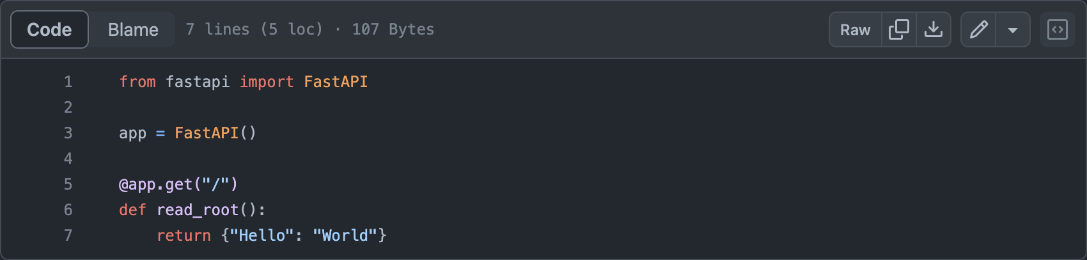
vi를 사용할 때 새로운 텍스트를 입력하려면 키보드에서 "i"를 입력합니다. 그리고 다음의 코드를 복사해서 입력합니다.from fastapi import FastAPI app = FastAPI() @app.get("/") def read_root(): return {"Hello": "World"}
코드를 입력한 후 파일을 저장하려면 [ESC] 키를 누른 다음 "wq!"를 입력하고, [Enter] 키를 누릅니다. w는 파일에 내용을 쓰겠다는 의미이고, q는 편집기를 종료한다는 뜻입니다. 서버 코드를 작성한 다음에는 서버를 실행시켜 보겠습니다. 호스트 주소를 0.0.0.0으로 지정합니다. 포트는 별도로 지정하지 않으면 8000번 포트로 시작합니다. 만일, 포트를 직접 지정하려면
--port 3000과 같이 입력합니다.$ python3 -m uvicorn main:app --host 0.0.0.0[TIP] localhost와 0.0.0.0서버를 실행할 때 주소를 지정해야 하는데, 만일 주소를 지정하지 않으면 기본적으로 localhost 주소가 사용됩니다. localhost 주소는 현재 실행 중인 컴퓨터를 의미합니다. 그러나 EC2 인스턴스는 외부에서 접속할 수 있는 공개 IP 주소를 가지고 있습니다. 따라서 외부에서 접속할 수 있는 공개 IP 주소를 사용하려면 localhost가 아닌 0.0.0.0을 사용해야 합니다. 0.0.0.0은 모든 네트워크 인터페이스를 의미하며, 이는 서버가 모든 IP 주소에서 들어오는 연결을 수락합니다. 외부에서 접속할 수 있는 공개 IP 주소를 사용하려면 서버를 0.0.0.0 주소로 설정해야 합니다. 이렇게 하면 EC2 인스턴스가 외부에서 접속할 수 있게 됩니다. 그러나 보안상의 이유로 특정 IP 주소만 허용하도록 설정하는 것이 좋습니다. 이는 보안 그룹 또는 네트워크 ACL을 통해 설정할 수 있습니다.
서버가 http://0.0.0.0:8000 주소에서 실행 중인 것을 확인할 수 있습니다.
터미널 하단을 보면 EC2 인스턴스에 연결할 수 있는 공개(Public) IP 주소가 있습니다.
이제 웹 브라우저에서 해당 주소로 접속해 보겠습니다. EC2 인스턴스에 연결할 수 있는 공개 IP 주소를 복사해서 웹 브라우저에 붙여넣기 합니다. 예를 들어, 다음과 같이 입력합니다.
http://43.200.244.121:8000/하지만 접속을 해도 서버에 연결할 수 없습니다. 그 이유는 인스턴스가 외부 인터넷과의 연결을 허용하도록 설정되어 있지 않기 때문입니다. 이를 해결하기 위해 다시 인스턴스 대시보드로 돌아가 인스턴스 ID를 클릭합니다.
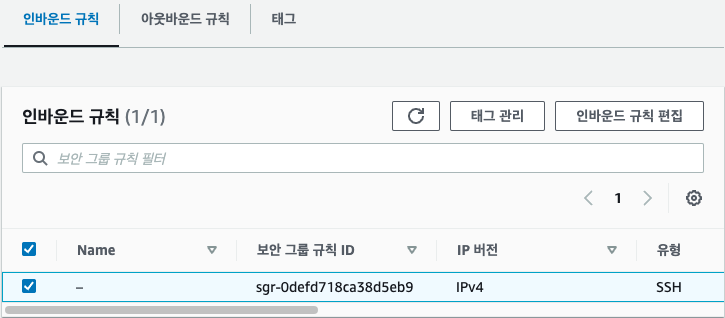
인스턴스 상세 정보를 볼 수 있는 페이지가 나타나면 [보안] 탭에서 '보안 그룹'을 클릭합니다.
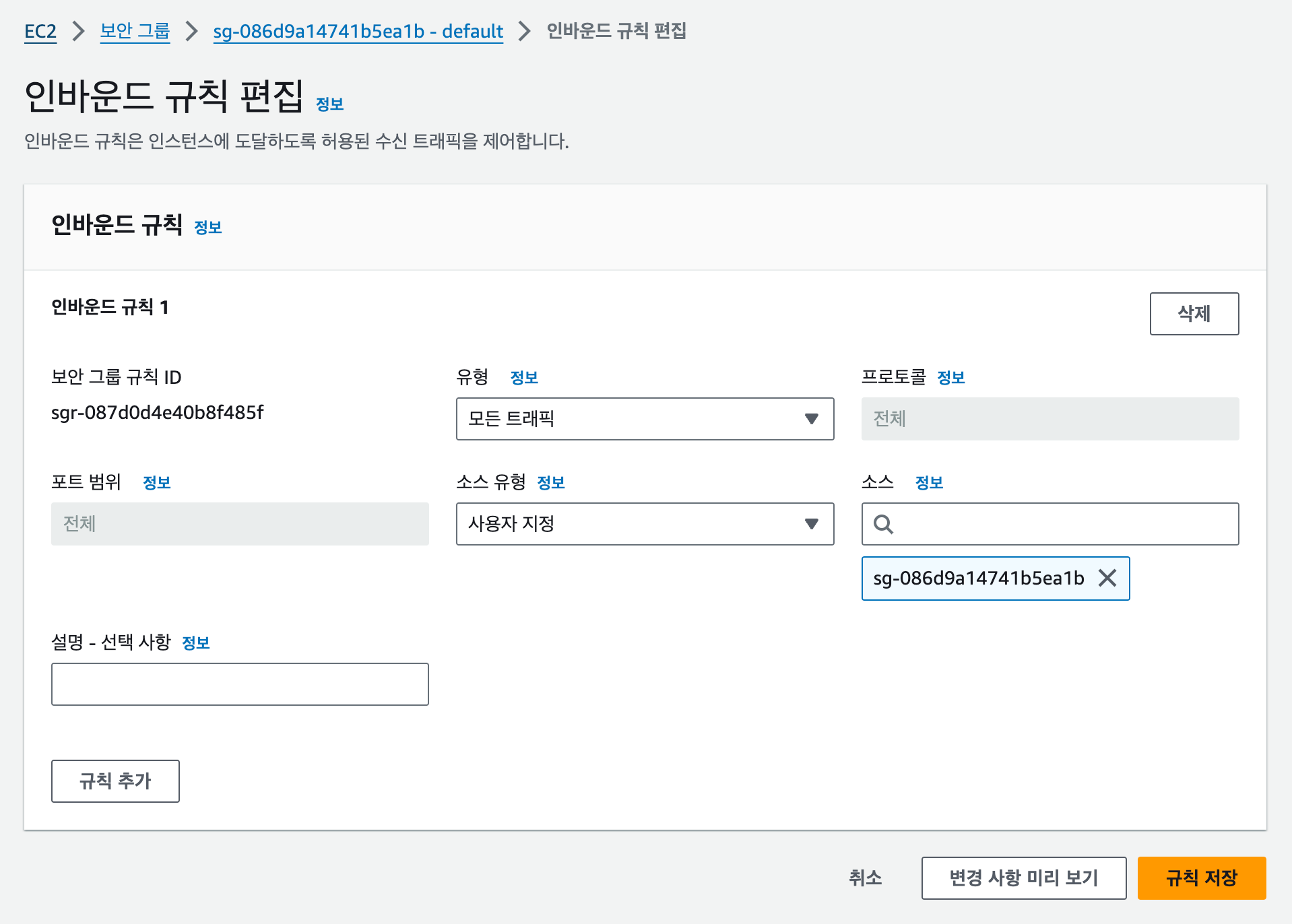
[인바운드 규칙] 탭에서 선택한 보안 그룹의 [인바운드 규칙 편집] 버튼을 클릭합니다.
유형을 [모든 트래픽]으로 선택하고, [규칙 저장] 버튼을 클릭합니다. 지금은 편의상 모든 트래픽을 허용하지만 나중에는 적절한 보안 그룹과 규칙을 적용해 제한된 포트와 통신 방식만 허용하도록 할 수 있습니다.
image-40.png 설명과 그림이 일치하지 않는데... 지문에 맞는 그림이 필요합니다.
이제 웹 브라우저에서 공개 IP주소로 접속하면 다음과 같은 텍스트가 화면에 나타납니다. 이처럼 EC2에 서버를 만들고, 공개 IP와 내가 원하는 포트를 사용해 API 서버를 구성할 수 있습니다.
{"Hello":"World"}[4] EC2에서 도커로 서버 실행하기
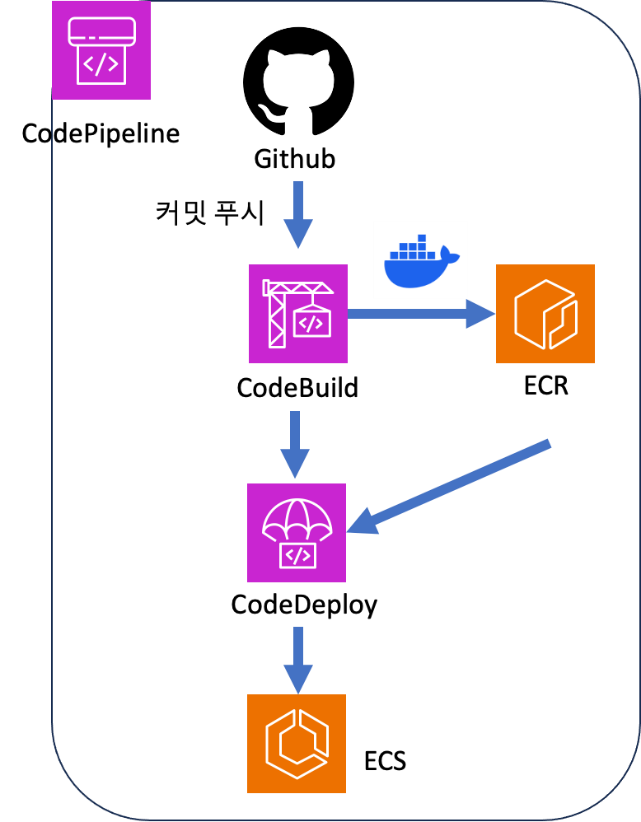
ECR 사용하기
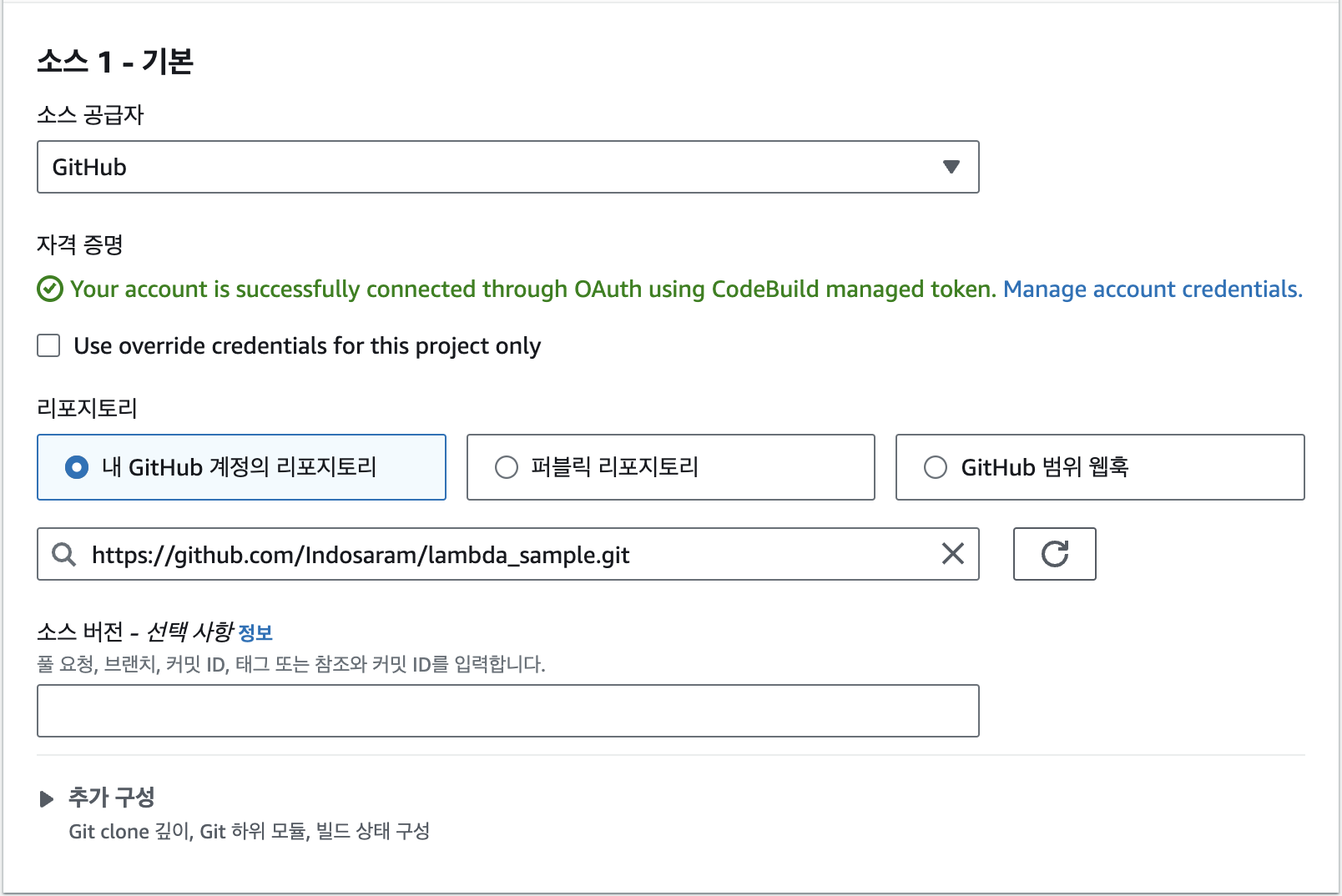
도커 이미지를 사용하려면 가장 먼저 AWS에 도커 이미지를 배포해야 합니다. 여기에서는 AWS ECR(Elastic Container Registry)이라는 이미지 저장소 서비스를 사용합니다. ECR은 1장에서 설명한 사설 도커 레지스트리에 해당합니다. 앞으로 ECR에 도커 이미지를 저장하고 Lambda나 다른 AWS 서비스에서 해당 이미지를 다운로드해서 사용하게 됩니다.
검색란에 "Elastic Container Registry"를 검색해서 콘솔로 들어갑니다. 그 다음 레포지토리 생성에서 [시작하기] 버튼을 클릭합니다.
{width="6.5in" height="3.216666666666667in"}
위 설명에 맞는 그림을 삽입해 주세요.
먼저 일반 설정에서는 표시 여부를 선택할 수 있습니다. 프라이빗은 해당 레포지토리에 접근할 때 IAM 권한이 있는 사용자만 접근할 수 있고, 퍼블릭은 누구나 접근할 수 있습니다. 지금은 나 이외의 다른 사람들의 접근이 필요하지 않기 때문에 '프라이빗'으로 선택합니다. 레포지토리 이름에 "my_app"을 입력하고, 하단의 [레포지토리 생성] 버튼을 클릭합니다. 나머지 설정은 변경하지 않습니다.
{width="5.341488407699037in" height="3.543307086614173in"}image-43.png
이제 대시보드에 'my_app' 레포지토리가 생성되었습니다. 레포지토리 이름을 클릭합니다.
{width="6.573522528433946in" height="0.6692913385826772in"} image-44.png
우측 상단의 [푸시 명령 보기] 버튼을 클릭하면 도커 이미지를 업로드하는 방법이 나타납니다. 맥OS 또는 리눅스와 윈도우 운영 체제에서의 명령어가 약간 다르기 때문에 자신의 운영 체제에 맞는 명령어를 선택합니다. 이때, 이미 만들어져 있는 도커 이미지를 사용할 것이기 때문에 여기에서 안내되는 도커 관련 명령어는 입력하지 않습니다.
{width="5.2403291776028in" height="2.0866141732283463in"}image-45.png
2장에서 설치한 AWS CLI를 사용해 ECR에 로그인합니다. 맥/리눅스/윈도우의 명령어가 다르기 때문에 주의합니다. 아래 코드에서
000000000000``으로`` ``표시된``저장소 주소를 실제 저장소 주소로 바꾸는 것도 잊지 마세요.+-----------------------------------------------------------------------+ | # macOS / Linux | | aws ecr g | | et-login-password --region ap-northeast-2 | docker login --username A | | WS --password-stdin 000000000000.dkr.ecr.ap-northeast-2.amazonaws.com | | | | # Windows | | (Get-ECRLoginCommand).Password | docker login --username A | | WS --password-stdin 000000000000.dkr.ecr.ap-northeast-2.amazonaws.com | +=======================================================================+ +-----------------------------------------------------------------------+
명령어를 실행하면 다음과 같은 경고가 나타나는데, 이는 비밀번호가 암호화되지 않은 상태로 저장되기 때문입니다. 일반적으로 서비스 계정의 비밀번호를 로컬 컴퓨터에 저장하지 않고, AWS 서비스 내부에서만 ECR에 접근하기 때문에 여기에서는 무시하고 넘어갑니다. 성공적으로 로그인이 되었다면 'Login Succeeded'라는 메시지가 나타납니다.
+-----------------------------------------------------------------------+ | WARNING! Your pa | | ssword will be stored unencrypted in /Users/indo/.docker/config.json. | | Configure a credential helper to remove this warning. See | | https:// | | docs.docker.com/engine/reference/commandline/login/#credentials-store | | | | Login Succeeded | +=======================================================================+ +-----------------------------------------------------------------------+
도커 이미지 만들고 배포하기
이번에는 도커 이미지를 빌드하고, ECR에 업로드해 보겠습니다. 먼저 1장에서 도커와 AWS CLI를 설치한 내 컴퓨터(AWS EC2가 아닙니다)에서 빈 폴더를 원하는 위치에 하나 생성한 다음 파이썬 파일
main.py를 만들어주세요. 그리고 vi 에디터나 코드 편집기를 사용해 다음의 코드를 입력합니다. vi에서 파일을 저장하려면 esc를 먼저 입력한 다음 wq!를 입력합니다.+-----------------------------------------------------------------------+ | from fastapi import FastAPI | | | | app = FastAPI() | | | | @app.get("/") | | def read_root(): | | return {"Hello": "World"} | +=======================================================================+ +-----------------------------------------------------------------------+
그 다음에는 도커 이미지를 빌드하기 위한 설정 파일인
Dockerfile``을만들어 보겠습니다. 파이썬 파일과 같은 위치에 생성하면 됩니다. EC2 인스턴스에서 파이썬 서버를 실행하기 위해서 설치했던 의존성과 파이썬 패키지들을 동일하게 도커 이미지에도 정의하는 과정입니다. Dockerfile의 내용은 다음과 같습니다. 각 라인이 의미하는 내용을 주석으로 표기했습니다.+-----------------------------------------------------------------------+ | # 도커 이미지를 생성할 기본 운영 체제 이미지 | | FROM ubuntu:20.04 | | | | # 도커 이미지에 패키지를 업데이트하고 파이썬 설치 | | RUN apt-get update && apt-get install -y python3 python3-pip | | | | # FastAPI와 Uvicorn을 설치 | | RUN pip3 install fastapi "uvicorn[standard]" | | | | # 도커 이미지에 필요한 파일을 복사 | | COPY main.py /app/main.py | | | | # 도커 이미지를 실행할 폴더 | | WORKDIR /app | | | | # 도커 이미지를 실행할 명령어 | | CMD ["uvicorn", "main:app", "--host", "0.0.0.0" ] | +=======================================================================+ +-----------------------------------------------------------------------+
Dockerfile이 있는 폴더에서 다음의 명령어를 실행합니다. docker build는 이미지를 생성하는 명령어이고 뒤에 "."를 붙이는 것은 현재 경로에 있는 도커파일을 참조한다는 뜻입니다. -t 옵션은 이미지의 태그를 지정하는 것으로 이미지의 이름이라고 생각하면 됩니다. '000000000000'은 자신의 계정 ID로 변경해야 합니다.+-----------------------------------------------------------------------+ | docker build | | . -t 000000000000.dkr.ecr.ap-northeast-2.amazonaws.com/my_app:latest | | docker build | | . -t 000000000000.dkr.ecr.ap-northeast-2.amazonaws.com/my_app:latest | | [+] Building 1.7s (10/10) FINISHED | | => [internal] load .dockerignore 0.0s | | => => transferring context: 2B 0.0s | | => [internal] load build definition from Dockerfile 0.0s | | => => transferring dockerfile: 261B 0.0s | | => [internal] load metadata for docker.io/library/ubun 1.6s | | => [internal] load build context 0.0s | | => => transferring context: 28B 0.0s | | => [1/5] FROM docker.io/library/ubuntu:20.04@sha256:ed 0.0s | | ... | | => exporting to image 0.0s | | | | image 0.0s | | => => exporting layers 0.0s | | => => writing image sha256:52e1c2337749a6409fc97d293e7 | | image sha256:52e1c2337749a6409fc97d293e7 0.0s | | | | => => naming to 000000000000.dkr.ecr.ap-northeast-2.am 0.0s | +=======================================================================+ +-----------------------------------------------------------------------+
도커 이미지가 정상적으로 빌드되면 도커 이미지를 컨테이너로 실행해서 제대로 작동하는지 실행해 보겠습니다. 다음의 명령어를 실행합니다.
-p옵션은 도커의 내부 포트 8000번을 로컬 포트(내 컴퓨터) 8000번으로 포워딩하는 옵션입니다. 즉, 내 컴퓨터에서 http://localhost:8000/ 주소로 접속하면 도커 내부의 8000번 포트로 연결됩니다. FastAPI 서버가 8000번 포트에서 작동하고 있기 때문에 8000번을 포워딩한 것입니다.+-----------------------------------------------------------------------+ | docker run -p 8000 | | :8000 000000000000.dkr.ecr.ap-northeast-2.amazonaws.com/my_app:latest | +=======================================================================+ +-----------------------------------------------------------------------+
웹 브라우저에서 http://localhost:8000/ 주소로 접속했을 때 다음과 같이 나타나면 서버가 정상적으로 실행된 것입니다.
+-----------------------------------------------------------------------+ | {"Hello":"World"} | +=======================================================================+ +-----------------------------------------------------------------------+
이제 도커 이미지를 ECR에 업로드해 보겠습니다. docker push는 이미지를 저장소에 업로드할 때 사용하는 명령어로, 그 뒤에는 업로드할 이미지의 태그를 입력하면 됩니다.
+-----------------------------------------------------------------------+ | docker | | push 000000000000.dkr.ecr.ap-northeast-2.amazonaws.com/my_app:latest | | The push refers to | | repository [000000000000.dkr.ecr.ap-northeast-2.amazonaws.com/my_app] | | 1a5bdedeab15: Pushed | | ... | | 6c3e7df31590: Pushed | | latest: digest: sha256:7c0d41 | | bf22c40ead9321605276f9876158d0eeae55fbaccc44de4288a46b553d size: 1367 | +=======================================================================+ +-----------------------------------------------------------------------+
도커 이미지를 성공적으로 업로드하면 ECR의 my_app 레포지토리에서 이미지가 업로드된 것을 확인할 수 있습니다.
{width="6.667045056867892in" height="1.5520833333333333in"} image-52.png
EC2에서 도커 컨테이너 실행하기
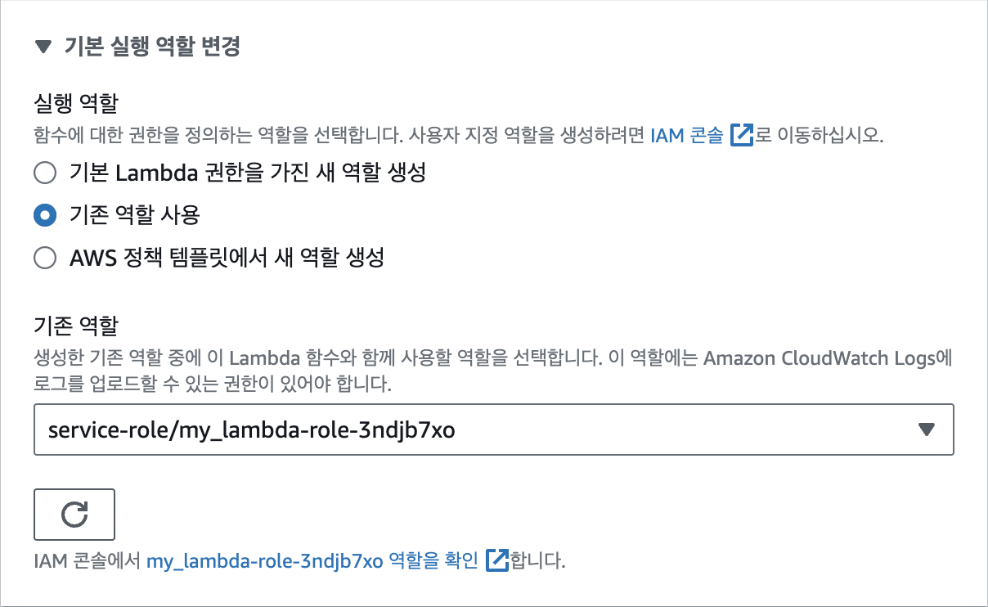
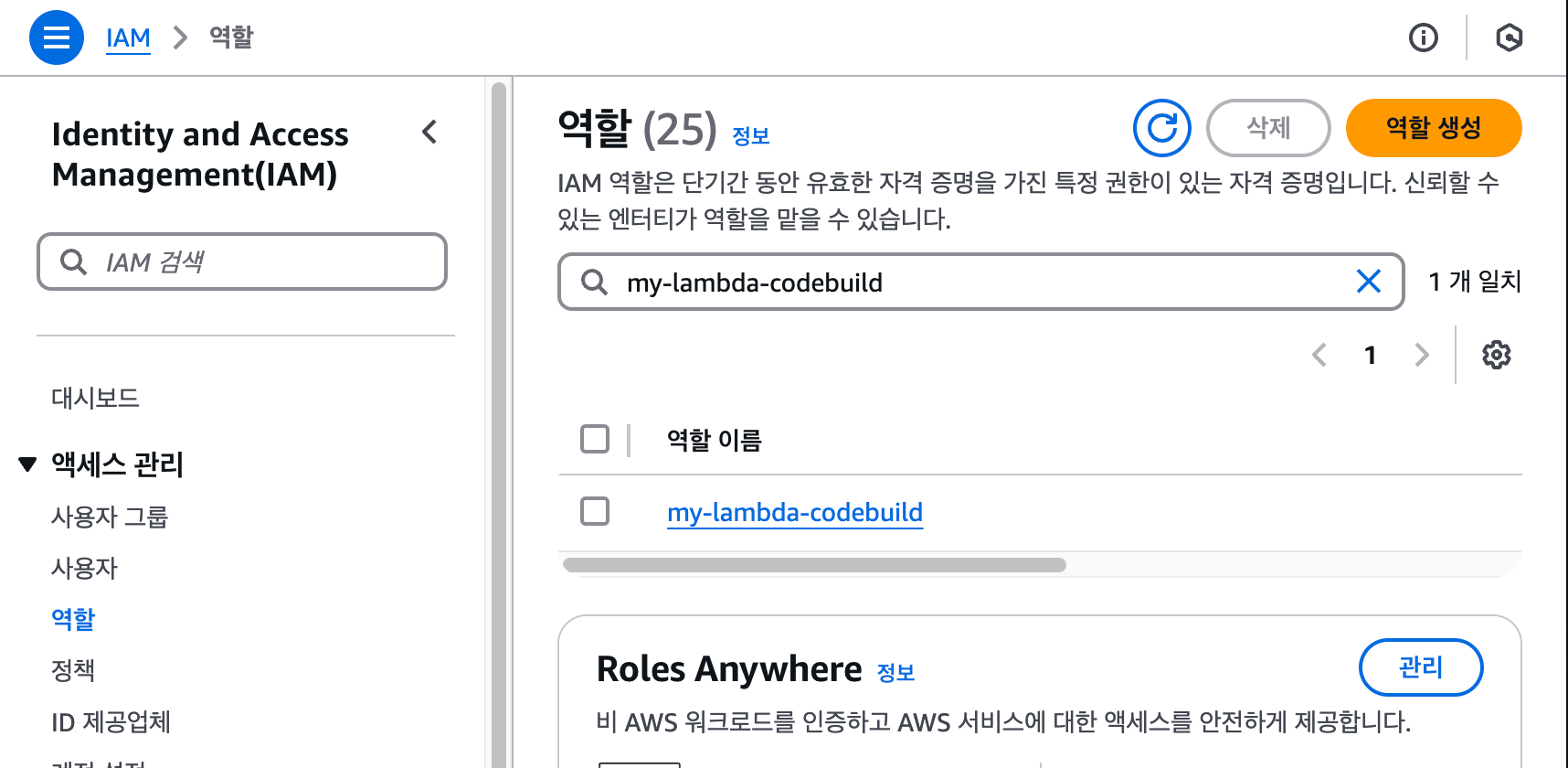
이번에는 EC2에서 방금 푸시한 도커 이미지를 다운로드하고 컨테이너를 실행해 보겠습니다. 먼저, EC2가 ECR에 접속할 수 있도록 IAM 역할을 생성하고 부여하기 위해 콘솔 검색에서 "IAM"을 입력한 후 대시보드에서 '역할' 패널로 이동합니다. 우측 상단의 [역할 생성] 버튼을 클릭합니다.
{width="6.130380577427822in" height="0.7086614173228346in"} image-63.png
신뢰할 수 있는 엔터티 유형은 AWS 서비스로 사용 사례에서 [EC2]를 선택하고, [다음] 버튼을 클릭합니다.
{width="4.985777559055118in" height="3.543307086614173in"} image-64.png
권한 정책에서 [AmazonEC2ContainerRegistryReadOnly]를 선택하고, [다음] 버튼을 클릭합니다. 해당 정책은 EC2 인스턴스에서 ECR 레포지토리에 저장된 이미지를 다운로드할 수 있게 허용합니다. 하지만 이미지를 푸시하는 것은 허용되지 않습니다.
{width="5.058783902012248in" height="1.7716535433070866in"} image-66.png
역할 이름은 "ec2-ecr-role"로 입력합니다.
{width="6.5in" height="3.915277777777778in"}
그리고 마지막으로 하단의 [역할 생성] 버튼을 클릭합니다.
{width="6.5in" height="3.452777777777778in"}
지문에 맞는 그림을 삽입해 주세요.
역할 생성이 완료되면 다시 EC2 대시보드로 돌아가서 인스턴스를 클릭하고, [작업]-[보안]-[IAM 역할 수정]을 선택합니다.
{width="5.624711286089239in" height="1.2992125984251968in"}
image-67.png
IAM 역할 목록에서 생성한 IAM 역할을 선택하고, [IAM 역할 업데이트] 버튼을 클릭합니다.
{width="5.639666447944007in" height="1.6141732283464567in"}
image-68.png
EC2에 권한이 부여되었으니 ECR에 접근이 되는지 확인해 보겠습니다. EC2 대시보드에서 인스턴스에 연결하거나 SSH를 사용해 터미널로 진입합니다. 그리고 EC2에 도커를 설치합니다. 여기서 설치하는 도커는 GUI로 도커를 관리할 수 있는 도커 데스크탑과 다르게 터미널에서 도커를 실행하고 관리할 수 있는 기능인 도커 엔진만 들어있습니다.
+-----------------------------------------------------------------------+ | sudo apt-get install -y docker.io unzip | | | | curl "https: | | //awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" | | unzip awscliv2.zip | | sudo ./aws/install | +=======================================================================+ +-----------------------------------------------------------------------+
도커를 설치한 다음에는 AWS CLI를 사용해 ECR에 로그인합니다.
+-----------------------------------------------------------------------+ | aws ecr g | | et-login-password --region ap-northeast-2 | docker login --username A | | WS --password-stdin 000000000000.dkr.ecr.ap-northeast-2.amazonaws.com | +=======================================================================+ +-----------------------------------------------------------------------+
만일, 다음과 같은 에러 메세지가 나오는 경우는 D
ocker사용자의 권한이 부족하다는의미입니다.
+-----------------------------------------------------------------------+ | permission denied while trying t | | o connect to the Docker daemon socket at unix:///var/run/docker.sock: | +=======================================================================+ +-----------------------------------------------------------------------+
다음의 명령어를 실행해
docker사용자를sudo권한으로 실행할 수 있도록 설정합니다. 첫 번째 부분인 'sudo usermod -aG docker $USER'는 현재 사용자를 도커 그룹에 추가하는 명령입니다. 여기서 'sudo'는 관리자 권한으로 명령을 실행하겠다는 의미이고, 'usermod'는 사용자 계정을 수정하는 명령어입니다. '-aG' 옵션은 사용자를 새 그룹에 추가한다는 의미이며, 'docker'는 추가할 그룹의 이름입니다. '$USER'는 현재 로그인한 사용자를 가리키는 환경 변수입니다. 두 번째 부분인 'newgrp docker'는 현재 세션에 새로운 그룹 설정을 즉시 적용하는 명령입니다. 이 명령을 실행하면 로그아웃하고 다시 로그인할 필요 없이 바로 도커 그룹의 권한을 얻을 수 있습니다.이 과정을 거치면 일반 사용자도 'sudo' 없이 도커 명령어를 실행할 수 있게 됩니다. 이는 보안상의 이유로 권장되는 설정이며, 도커를 더 편리하게 사용할 수 있게 해줍니다. 하지만 이 설정은 해당 사용자에게 높은 수준의 권한을 부여하므로, 신중하게 적용해야 합니다.
+-----------------------------------------------------------------------+ | sudo usermod -aG docker $USER | | newgrp docker | +=======================================================================+ +-----------------------------------------------------------------------+
docker pull 명령어를 사용해 도커 이미지를 다운로드 받습니다. 다음의 명령어에서 '000000000000'은 자신의 계정 ID로 변경해 주세요.
+-----------------------------------------------------------------------+ | docker | | pull 000000000000.dkr.ecr.ap-northeast-2.amazonaws.com/my_app:latest | +=======================================================================+ +-----------------------------------------------------------------------+
이제 다운로드 받은 이미지로 컨테이너를 실행해 보겠습니다.
--name옵션을 추가해 컨테이너에 이름을 부여합니다. 잠시 후에 docker ps로 실행 중인 컨테이너를 확인해 보면 여기서 지정한 이름으로 컨테이너가 실행 중인 것을 확인할 수 있습니다.+-----------------------------------------------------------------------+ | docker run -p 8000:8000 --name my_app 0 | | 00000000000.dkr.ecr.ap-northeast-2.amazonaws.com/my_app:latest my_app | +=======================================================================+ +-----------------------------------------------------------------------+
이제 파이썬 코드를 직접 실행한 것과 동일하게 공개 IP주소에서 서버 응답을 받을 수 있습니다. 참고로 도커 컨테이너를 실행하면 인스턴스에서 연결을 끊더라도(SSH 접속을 종료하는 경우) 명시적으로 컨테이너를 종료하지 않는 이상 계속 실행됩니다. 컨테이너를 종료하려면 컨테이너의 이름
my_app을 사용합니다.+-----------------------------------------------------------------------+ | docker stop my_app | +=======================================================================+ +-----------------------------------------------------------------------+
명령어를 실행하면 프로그램이 계속 실행 중이라 다른 명령어를 입력할 수 없을 것입니다. 터미널에 Ctrl + C를 입력하면 프로그램 실행이 종료됩니다. 이 경우 터미널이 종료되면 프로그램도 종료되기 때문에 서버 프로그램과 같이 계속 실행 중이어야 하는 프로그램은 백그라운드로 실행하면 편리합니다. 백그라운드에서 컨테이너를 계속 실행하려면 docker run 다음에
-d옵션을 추가합니다. 나머지 옵션은 동일합니다.+-----------------------------------------------------------------------+ | docker run -d -p 8000:8000 --name my_app 0 | | 00000000000.dkr.ecr.ap-northeast-2.amazonaws.com/my_app:latest my_app | +=======================================================================+ +-----------------------------------------------------------------------+
이제 다른 명령어를 입력할 수 있습니다. 실행 중인 컨테이너 목록을
docker ps로 확인해 보면 다음과 같습니다.+-----------------------------------------------------------------------+ | docker ps | | | | CONTAINER ID IMAGE | | COMMAND CREATED | | IMAGE | | COMMAND CREATED | | STATUS PORTS NAMES | | | | 6f57b28bde36 000000000000.dkr.ecr.ap-northeast- | | 2.amazonaws.com/my_app:latest "uvicorn main:app --…" 2 seconds ag | | o Up 2 seconds 0.0.0.0:8000->8000/tcp, :::8000->8000/tcp my_app | +=======================================================================+ +-----------------------------------------------------------------------+
[5] Lambda에 API 서버 만들기
이번에는 Lambda를 사용해서 API 서버를 만들어 보겠습니다. Lambda를 만드는 방법은 두 가지가 있습니다. 첫째는 지원되는 런타임을 사용해서 소스 코드를 바로 실행하는 방법입니다. Node.js, Python, Ruby, Go, Java, C# 코드를 실행할 수 있지만 Lambda 웹에서 코드를 바로 편집할 수 있는 콘솔 편집기는 Node.js, Python, Ruby만 지원합니다. 이러한 방식을 사용하는 경우 추가적인 라이브러리나 파일을 별도로 Lambda에 업로드해서 설정해야 하기 때문에 불편합니다. 둘째는 도커 이미지를 사용하는 방법입니다. 미리 만들어진 도커 이미지를 사용해 Lambda 함수를 만들 수 있습니다. 해당 방법은 Node.js, Python, Ruby, Java, Go, .NET Core, PowerShell, Custom Runtime을 지원합니다. 이러한 방법은 미리 만들어진 도커 이미지를 사용하기 때문에 콘솔 편집기를 사용하지 않고도 다양한 언어를 사용할 수 있습니다. 또한, 도커 이미지를 사용하면 라이브러리를 미리 설치해 놓을 수 있기 때문에 라이브러리 설치에 대한 제약이 없습니다. 따라서 도커 이미지를 사용하는 방법을 추천합니다.
API Gateway
AWS API Gateway는 다양한 클라이언트 애플리케이션이 서버리스 함수, 웹 애플리케이션, 그리고 다른 HTTP 엔드포인트와 같은 백엔드 서비스에 쉽게 접근할 수 있도록 해주는 관리형 서비스입니다. 마치 건물의 현관문과 같이, API Gateway는 외부에서 들어오는 모든 요청을 관리하고, 적절한 백엔드 서비스로 연결해 줍니다.
API Gateway를 사용하면 개발자는 RESTful API와 WebSocket API를 쉽게 만들고 관리할 수 있습니다. 또한, API Gateway는 자동으로 API를 위한 스케일링, 모니터링, 그리고 보안 기능을 제공합니다. 예를 들어, API Gateway는 트래픽 증가에 따라 자동으로 용량을 확장하고, API 사용량을 모니터링하여 이상 징후를 감지하고, API 키를 사용하여 API에 대한 접근을 제한하는 등의 기능을 수행합니다.
API Gateway의 가장 큰 장점 중 하나는 서버리스 아키텍처와의 뛰어난 호환성입니다. AWS Lambda와 같은 서버리스 함수와 API Gateway를 함께 사용하면 서버 관리 없이도 강력한 API를 구축할 수 있습니다. 이는 개발 생산성을 높이고 비용을 절감하는 데 큰 도움이 됩니다. 실제로 API Gateway를 구축하는 것은 Lambda를 설정하는 과정에서 살펴보도록 하겠습니다.
도커 이미지 만들기
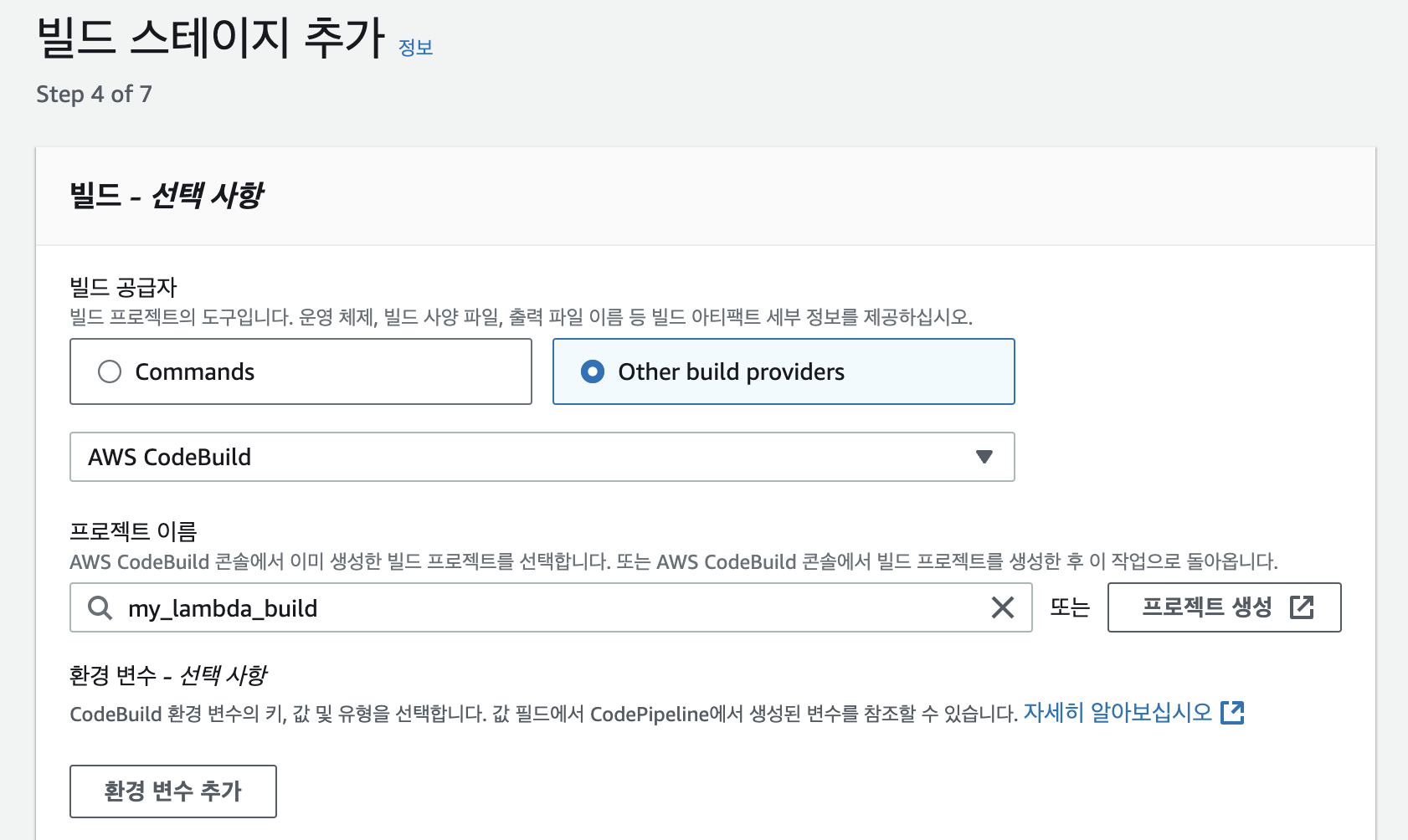
Lambda 함수를 위한 새로운 도커 이미지를 저장할 ECR 저장소를 만들어야 합니다. 이전에 EC2에서 했던 방식과 동일하게 생성하면 됩니다. 이번엔 저장소 이름을
my_lambda로 지정하겠습니다.그리고 로컬 컴퓨터에서는 도커파일과 소스코드를 저장할 새로운 폴더 labmda_python을 원하는 위치에 생성합니다. 소스코드는 app.py 파일을 만들면 됩니다. Lambda와 API Gateway를 함께 사용할 때는 특별한 주의가 필요합니다. Lambda 함수가 API Gateway와 원활하게 통신하려면, 정해진 형식에 맞춰 JSON 응답을 생성해야 합니다. 이를 위해 app.py 파일에 다음과 같은 코드를 작성합니다.
이 코드는 Lambda 함수의 기본 구조를 보여줍니다.
handler함수는 이벤트와 컨텍스트를 입력받아, API Gateway가 이해할 수 있는 형식의 응답을 반환합니다. 여기서는 상태 코드 200(성공)과 함께 간단한 "Hello from Lambda!" 메시지를 JSON 형식으로 반환하고 있습니다. 이렇게 구성하면 API Gateway를 통해 Lambda 함수를 호출했을 때, 적절한 응답을 받을 수 있습니다.import json def handler(event, context): return { "statusCode": 200, "body": json.dumps({"text": "Hello from Lambda!"}) }
Dockerfile은 다음과 같이 정의합니다. AWS에서는 Lambda 함수를 실행할 때 사용할 수 있는 기본 도커 이미지를 제공합니다. 이 도커 이미지는 Lambda 함수를 실행하는데 필요한 모든 라이브러리와 실행 환경을 포함하고 있습니다. 따라서 Lambda에서 실행할 코드인 app.py 파일만 도커 이미지에 복사해서 넣으면 됩니다. LAMBDA_TASK_ROOT가 소스 코드를 넣을 경로로 미리 지정된 환경 변수입니다. 그리고 컨테이너에서 실행할 명령어는 항상 app.handler여야 app.py에 정의된 handler 함수를 정상적으로 실행할 수 있습니다.FROM public.ecr.aws/lambda/python:3.11 # app.py 파일을 도커 이미지로 복사 COPY app.py ${LAMBDA_TASK_ROOT} # app.py 파일에 정의된 handler 함수를 실행 CMD [ "app.handler" ]NOTE: AWS Lambda의 기본 이미지는 https://gallery.ecr.aws/lambda에서 전체 목록을 확인할 수 있습니다.이제 다운로드 베이스 이미지에서 파이썬 코드를 추가한 새로운 이미지를 빌드합니다. 주소 뒷부분에는 이전에 생성한 레포지토리 이름인
/my_lambda과 태그를 붙여줍니다. 태그에는:latest를 붙여줍니다.$ docker build -t 000000000000.dkr.ecr.ap-northeast-2.amazonaws.com/my_lambda:latest .이제 로컬에서 제대로 작동하는지를 실행해 보겠습니다. 다음 명령어를 통해 컨테이너를 실행하면 Lambda 서버가 작동합니다.
$ docker run -p 9000:80 000000000000.dkr.ecr.ap-northeast-2.amazonaws.com/my_lambda:latest이 서버에 터미널에서 다음과 같이 요청을 보내 보면 "Hello from Lambda!"라는 응답을 받을 수 있습니다.
$ curl "http://localhost:9000/2015-03-31/functions/function/invocations" -d '{}'윈도우 환경에 curl이 설치되어 있지 않다면 다음 명령어를 사용하세요.
Invoke-WebRequest -Uri "http://localhost:9000/2015-03-31/functions/function/invocations" -Method Post -Body '{}' -ContentType "application/json"컨테이너가 정상적으로 작동하는 것을 확인했다면 도커 이미지를 저장소에 푸시하겠습니다. 실행이 완료되었을 때 마지막에
sha256:\...과 같이 결과값이 나오면 정상적으로 저장소에 이미지가 푸시된 것입니다.$ docker push 000000000000.dkr.ecr.ap-northeast-2.amazonaws.com/my_lambda:latestLambda 함수 만들기
이제 Lambda 함수를 만들어 보겠습니다. 서비스 검색창에 "Lambda"를 검색해서 해당 서비스 페이지로 들어간 다음, Lambda 함수 페이지에서 [함수 생성] 버튼을 클릭합니다.
Lambda 함수의 종류는 3가지 중에 선택할 수 있습니다. 여기에서는 도커 이미지를 사용할 것이므로 '컨테이너 이미지'를 선택하고, 함수 이름에는 "my_lambda"로 입력합니다.
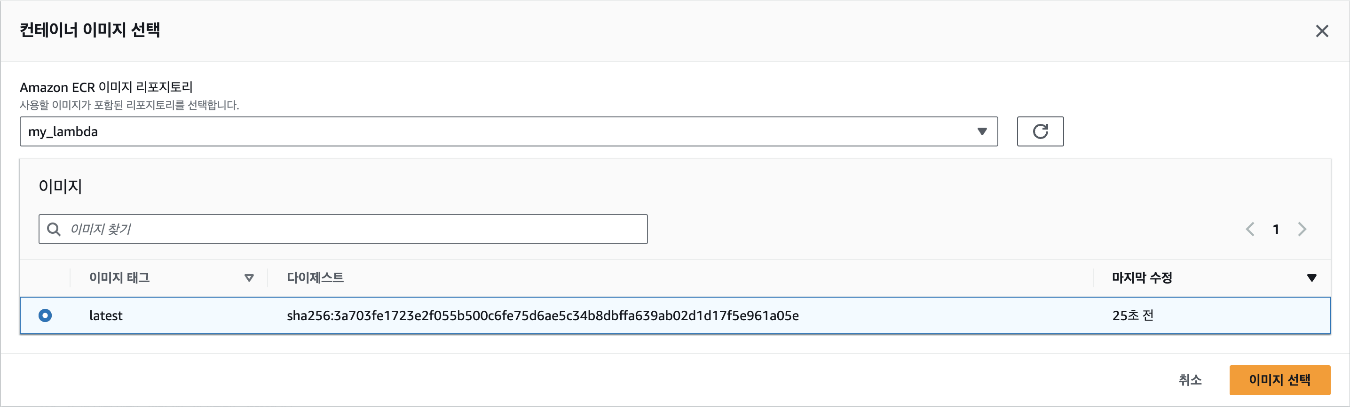
그 다음은 어떤 이미지를 사용할지 입력해야 하는데, ECR에서 주소를 복사해도 되지만 [이미지 찾아보기] 버튼을 클릭하면 쉽게 이미지를 찾을 수 있습니다.
레포지토리 이름을 선택하면 업로드한 이미지가 나타납니다. 해당 이미지를 선택하고, 우측 하단의 [이미지 선택] 버튼을 클릭합니다.
아키텍처 선택은
x86_64로 설정하고, [함수 생성] 버튼을 클릭합니다.
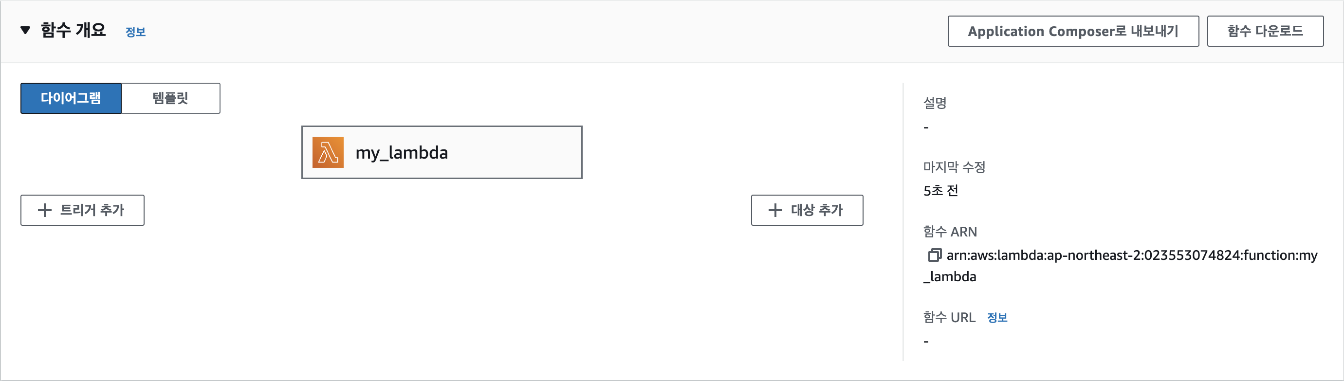
함수 생성 버튼을 클릭하고 나면 다음 그림처럼 함수에 대한 전반적인 설명을 볼 수 있는 함수 개요 패널로 이동되게 됩니다.
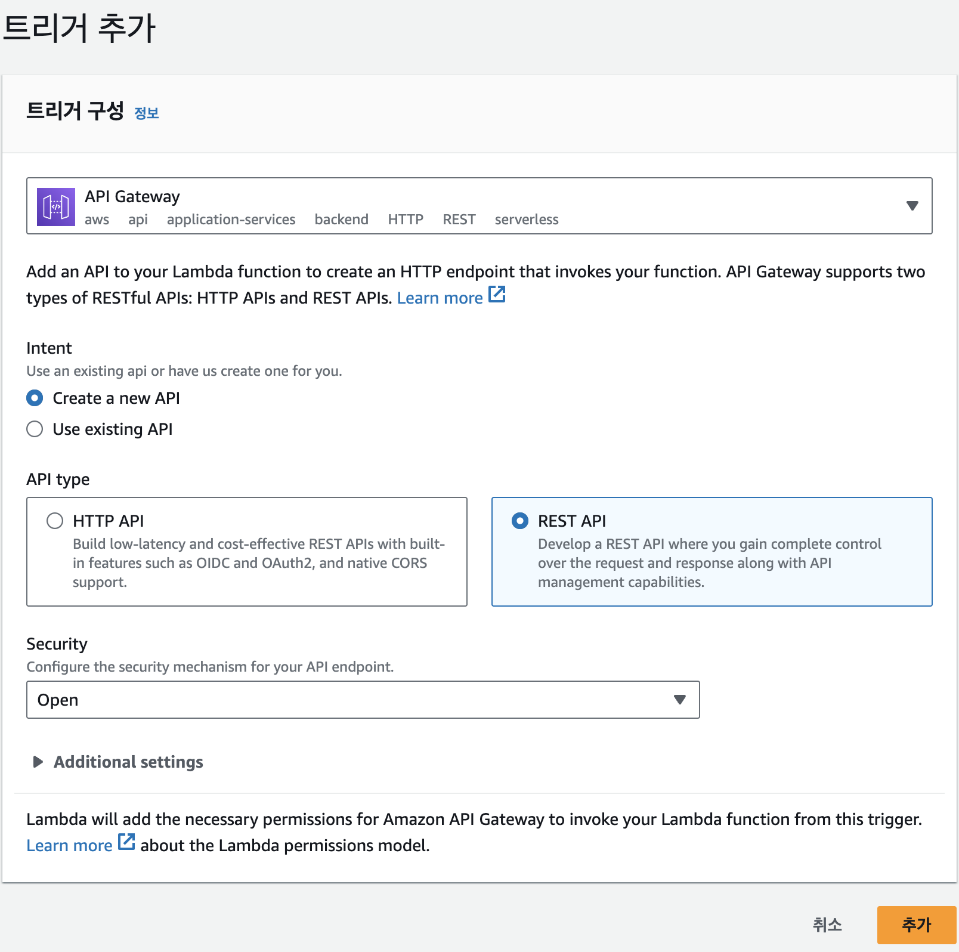
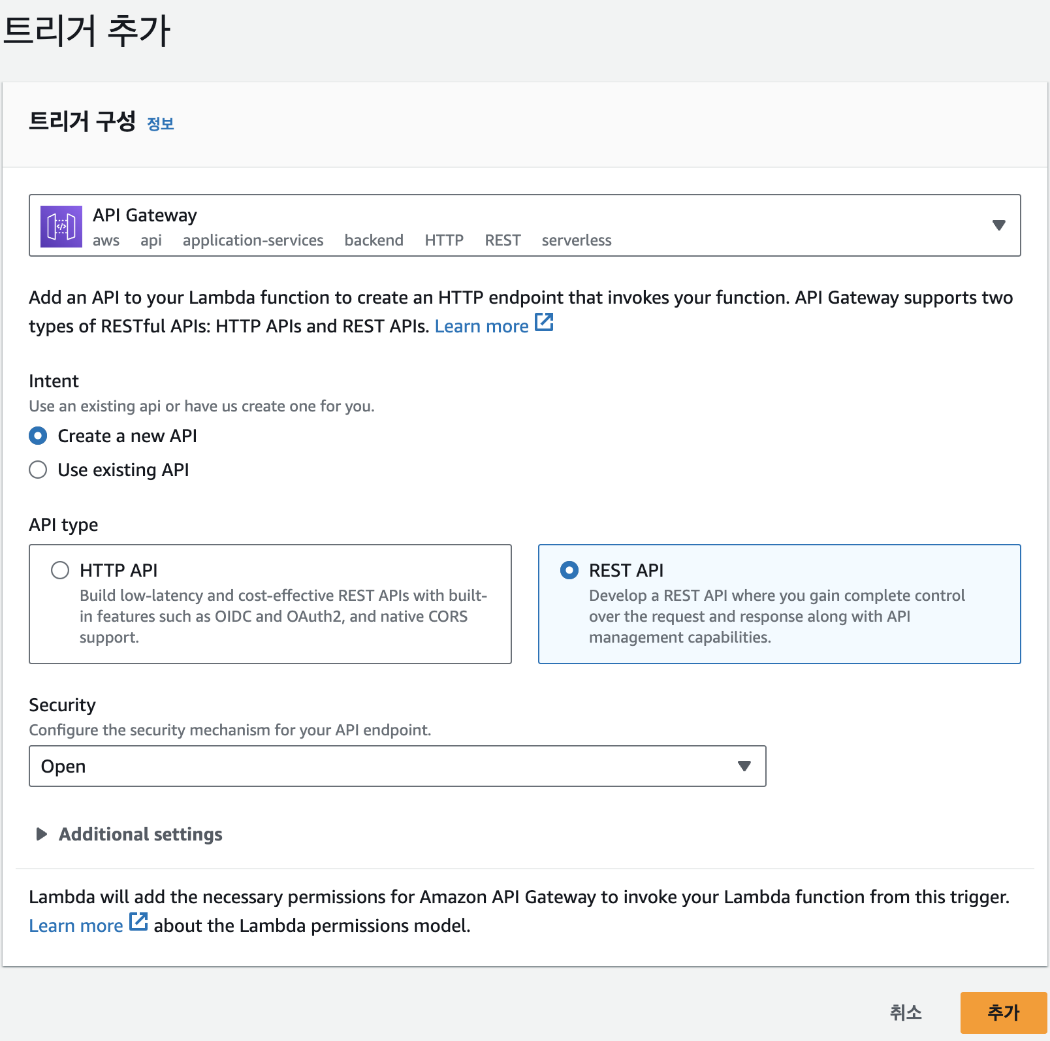
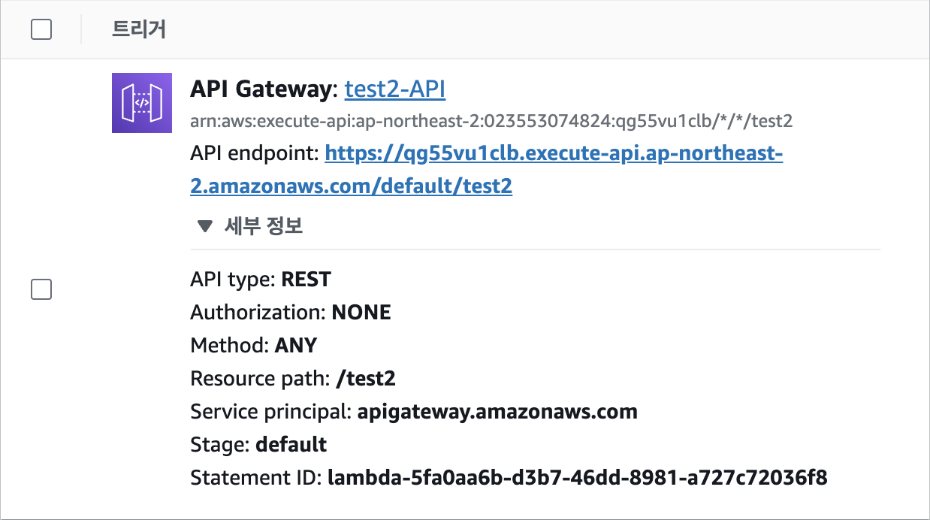
Lambda 함수가 생성된 것을 확인했으니 이제 해당 함수가 실행될 조건을 추가해야 합니다. 여기에서는 HTTP 요청이 들어올 때마다 해당 함수가 실행되도록 하겠습니다. 화면에서 [트리거 추가]를 클릭한 후 트리거 구성에서 [API Gateway]를 선택하고, 'Create a new API'를 클릭해 API를 새로 생성합니다. 계속해서 API type은 'REST API'로, Security는 ' Open'으로 선택합니다. 이렇게 설정하면 API 주소를 아는 사람은 누구나 API 요청을 보낼 수 있어서 보안 상 취약하지만, 지금은 넘어가겠습니다. 그 다음 [추가] 버튼을 클릭합니다.
이제 추가된 트리거(my_lambda-API)에서 API로 요청을 보낼 주소인 API Endpoint를 확인할 수 있습니다.
해당 주소로 웹 브라우저에 접속하면 Lambda 함수가 실행되고, 실행된 결과는 현재 설정한 것처럼 json 형태의 응답으로 오게 됩니다.
{ "text": "Hello from Lambda!" }[6] 자주 언급되는 질문
EC2와 Lambda 중 어떤 것을 사용해야 할까요?
EC2는 항상 작동하는 서버를 사용하는 반면, Lambda는 필요한 시점에만 서버를 사용합니다. 따라서 EC2는 항상 작동하는 서버가 필요한 경우에 사용하고, 필요한 시점에만 서버를 사용하는 경우는 Lambda를 사용합니다. 예를 들어, 매일 오전 9시에 실행하거나 자주 실행되지 않는 경우에는 Lambda가 적합합니다. 그러나 매일 정해진 시간이 아니라 사용자가 요청할 때마다 서버가 필요한 경우 그리고 요청이 자주 들어오는 경우에는 EC2를 사용해야 합니다.
Lambda에서 코드를 직접 작성하는 것과 도커 이미지를 사용하는 것 중 어떤 것이 좋을까요?
결론적으로 도커 이미지를 사용하는 것이 좋습니다. 그 이유는 여러 가지가 있습니다.
- Lambda에서 코드를 직접 작성하는 방법은 Node.js, Python, Ruby만 지원합니다.
- 콘솔 편집기를 사용해서 코드를 작성하기 때문에 코드를 수정하고 배포하는 것이 불편합니다.
- 함수 실행에 필요한 패키지나 라이브러리 등 의존성 레이어를 만들어 추가해야 하므로 매우 불편합니다.
반면, 도커 이미지를 사용하면 프로그래밍 언어의 제약 없이 애플리케이션을 만들 수 있습니다. 또한, 라이브러리를 미리 설치해 놓을 수 있기 때문에 편리합니다. 가장 중요한 점은 도커 이미지를 소스 코드나 라이브러리 업데이트에 따라 새로운 이미지를 빌드하고 람다에 새로운 이미지를 적용하는 모든 과정을 자동화할 수 있습니다.
Cloudwatch를 반드시 설정해야 하나요?
Cloudwatch는 AWS에서 제공하는 로깅 및 상태 감시 서비스입니다. EC2 인스턴스 또는 Lambda를 생성할 때 별도로 설정하지 않으면 각 서비스의 상태나 애플리케이션 실행 관련 기록이 Cloudwatch에 자동으로 기록됩니다. 만일, EC2나 Lambda 실행 중 문제가 발생한 경우 문제의 원인을 찾고 분석하기 위해서 당시 애플리케이션의 상태와 로깅 기록이 필요하기 때문에 애플리케이션을 운영하는데 필수적인 도구입니다. Cloudwatch에 관해서는 7장에서 자세하게 설명할 것입니다. 참고로 Lambda 실행 도중 타임아웃이 발생하는 경우 Cloudwatch 로그에는 해당 내용이 남지 않기 때문에 주의가 필요합니다.
요약
EC2와 Lambda의 특징을 비교해 백엔드 API 서버를 구축하는 방법을 학습했습니다.
Docker와 ECR을 활용해 컨테이너를 배포할 수 있습니다.
API Gateway를 통해 API서버에 인터넷을 연결할 수 있습니다.
EC2와 Lambda 환경에서 S3, RDS 등 AWS 주요 서비스와 연동하는 방법을 학습했습니다.
퀴즈
문제 1
아래 중 API 서버의 역할로 올바른 것은 무엇인가요?
A. 프론트엔드와 백엔드가 데이터를 주고받을 수 있도록 기능을 제공한다.
B. 데이터베이스와 직접 통신하지 않고, 오직 파일 저장만 담당한다.
C. 오직 정적 파일만을 제공하는 서버이다.
D. 오직 내부 네트워크에서만 동작할 수 있다.
정답: A
해설: API 서버는 프론트엔드와 백엔드 간 데이터 송수신을 위한 인터페이스를 제공합니다.
문제 2
AWS EC2와 Lambda의 주요 차이점으로 올바른 것은 무엇인가요?
A. EC2는 항상 동작하는 서버를 직접 관리해야 하고, Lambda는 이벤트가 발생할 때만 실행된다.
B. Lambda는 항상 동작하며, EC2는 서버리스 환경이다.
C. EC2는 서버리스이고, Lambda는 항상 동작하는 서버이다.
D. 둘 다 서버를 직접 관리해야 한다.
정답: A
해설: EC2는 사용자가 서버를 직접 관리해야 하며, Lambda는 이벤트 기반으로 실행되는 서버리스 컴퓨팅 서비스입니다.
문제 3
Lambda에서 도커 이미지를 사용하는 주된 장점은 무엇인가요?
A. Lambda에서만 사용할 수 있는 특수 언어를 지원한다.
B. 다양한 언어와 라이브러리, 의존성을 자유롭게 포함할 수 있다.
C. 도커 이미지는 Lambda에서만 실행할 수 있다.
D. 도커 이미지를 사용하면 비용이 무조건 더 저렴하다.
정답: B
해설: 도커 이미지를 사용하면 언어와 라이브러리, 의존성에 제약 없이 다양한 환경을 자유롭게 구성할 수 있습니다.
문제 4
API Gateway의 주요 역할로 올바른 것은 무엇인가요?
A. 데이터베이스에 직접 쿼리를 실행한다.
B. 외부 요청을 받아 Lambda나 다른 백엔드 서비스로 전달한다.
C. EC2 인스턴스를 자동으로 생성한다.
D. 정적 웹사이트만 호스팅할 수 있다.
정답: B
해설: API Gateway는 외부에서 들어오는 요청을 받아 Lambda 등 백엔드 서비스로 전달하는 역할을 합니다.
문제 5
EC2에서 도커 컨테이너를 실행할 때 ECR과 IAM 역할이 필요한 이유로 올바른 것은 무엇인가요?
A. ECR에 저장된 도커 이미지를 EC2가 다운로드하려면 권한이 필요하다.
B. EC2는 도커 이미지를 로컬에서만 빌드할 수 있다.
C. IAM 역할 없이도 모든 EC2 인스턴스가 ECR에 접근할 수 있다.
D. ECR은 도커 이미지를 저장할 수 없다.
정답: A
해설: EC2 인스턴스가 ECR에 저장된 도커 이미지를 다운로드하려면 적절한 IAM 역할이 부여되어야 합니다.
5장 데이터베이스와 스토리지
AWS(Amazon Web Services)는 클라우드 컴퓨팅을 제공하는 강력한 플랫폼으로, 데이터 저장 및 관리에 있어 중요한 역할을 합니다. 이 중 S3(Simple Storage Service)는 파일과 같은 대용량 데이터를 저장하는 객체 스토리지 서비스로, 비용 효율적이고 확장 가능한 저장소를 제공합니다. RDS(Relational Database Service)와 같은 AWS의 데이터베이스 서비스는 관리형 관계형 데이터베이스를 제공하여 사용자가 복잡한 데이터베이스 설정 및 유지보수를 신경 쓸 필요 없이 데이터 관리를 할 수 있도록 돕습니다. 이 두 서비스는 데이터 관리와 저장을 간소화하고, 확장성을 높여 애플리케이션 개발에 있어 필수적인 도구입니다.
[1] 데이터베이스와 스토리지의 개념
데이터베이스의 개념과 특징
데이터베이스는 쿼리, 업데이트 및 조작할 수 있는 구조화된 데이터를 안정적으로 저장해야 할 때 필요합니다. 그리고 엑셀 스프레드시트와 유사한 행과 열로 구성된 테이블이라는 형태로 데이터를 구성합니다. 이러한 조직 구조를 통해 데이터베이스 내의 정보를 빠르게 검색 및 분석해 인사이트와 패턴을 찾을 수 있습니다.
데이터베이스의 구조화된 특성은 시간이 지나도 데이터의 무결성과 일관성을 보장합니다. 데이터베이스는 SQL과 같은 쿼리 언어를 사용해 데이터를 저장, 변경 및 접근할 수 있습니다. 또한, 트랜잭션(Transaction)을 지원해 하나의 데이터베이스 변경 과정이 성공적으로 끝나거나 실패하는 경우에는 데이터가 변경되지 않도록 보장합니다. 데이터를 지속적으로 저장하면서도 데이터의 무결성을 유지해야 하는 애플리케이션의 경우 데이터베이스가 필수적입니다. 이러한 데이터베이스의 유형은 크게 관계형 데이터베이스와 NoSQL 데이터베이스의 두 가지 종류로 나눌 수 있습니다.
관계형 데이터베이스의 특징
관계형 데이터베이스는 데이터를 테이블 형태로 저장하는 데이터베이스로 테이블 간의 관계를 정의할 수 있습니다. 테이블은 행과 열로 구성되어 있으며, 각 행은 고유한 키를 가지고 있습니다. 예를 들어, 사용자 정보를 저장하는 테이블과 상품 정보를 저장하는 테이블이 있다고 가정할 때 사용자가 상품을 구매하면 사용자 정보 테이블과 상품 정보 테이블 간의 관계를 정의해 사용자가 구매한 상품 정보를 저장할 수 있습니다. 관계형 데이터베이스는 이러한 관계를 정의할 수 있기 때문에 데이터를 효율적으로 저장할 수 있습니다. 관계형 데이터베이스를 사용하기 위해서 EC2에 직접 데이터베이스 서버를 구축하는 방법도 있지만, AWS의 대표적인 관계형 데이터베이스 서비스인 RDS를 사용하면 좀더 편리합니다. 두 가지 방법의 장단점을 비교해 보면 다음과 같습니다.
+------+--------------------------------+------------------------------+ | 구분 | EC2에 데이터베이스 구축 | RDS 사용 | +======+================================+==============================+ | 장점 | - 서버 하드웨어에 대한 전체 | - 데이터베이스 관리 기능 | | | 제어 가능 | 제공 | | | | | | | - 데이터베이스 엔진 및 버전 | - 높은 가용성 보장 | | | 선택의 자유 | | | | | - 자동 백업 및 복구 지원 | | | - 사용량이 적다면 더 저렴함 | | +------+--------------------------------+------------------------------+ | 단점 | - 백업 및 재해 복구 구현 필요 | - AWS가 결정한 데이터베이스 | | | | 엔진 및 하드웨어만 사용 가능 | | | - 가용성 보장을 위한 추가 | | | | 작업 필요 | - 데이터 이동에 제약이 있을 | | | | 수 있음 | +------+--------------------------------+------------------------------+
RDS는 데이터베이스 서버를 직접 관리하는 번거로움 없이 AWS에서 관리하는 데이터베이스를 사용할 수 있다는 장점이 있지만, EC2에서 직접 구축하는 경우 많은 유연성과 제어가 가능하고, 사용량이 매우 작다면 EC2를 사용하는 것이 더 저렴할 수도 있습니다. 하지만 대부분의 경우 RDS를 사용하는 것이 더 편리하고 데이터가 항상 보존되기 때문에 안전합니다. 이제 RDS에서 MySQL을 사용해 데이터베이스를 구축할 것입니다.
관계형 데이터베이스를 사용하려면 SQL이라는 언어를 사용해야 합니다. SQL은 데이터베이스 관리, 데이터 조회 및 수정 등을 수행할 수 있는 도구입니다. 이 책에서는 데이터베이스와 관련해서 간단한 작업만 수행하기 때문에 지금은 SQL을 몰라도 괜찮지만, 현업에서 데이터베이스를 많이 다룬다면 필수적으로 배워야 하는 언어입니다.
NoSQL 데이터베이스의 특징
NoSQL 데이터베이스는 관계형 데이터베이스와 달리 테이블 형태로 데이터를 저장하지 않고, 키-밸류(Key-Value) 형태로 데이터를 저장합니다. 관계형 데이터베이스의 테이블 대신 컬렉션(Collection)이라는 개념을 사용합니다. 컬렉션은 테이블과 비슷한 개념이지만, 테이블과 달리 스키마(Schema)를 가지고 있지 않습니다. 따라서 컬렉션에 저장되는 데이터는 모두 다른 형태일 수 있습니다. 예를 들어, 사용자 정보를 저장하는 컬렉션에는 이름, 나이, 성별 등의 정보가 저장될 수 있고, 상품 정보를 저장하는 컬렉션에는 상품명, 가격, 재고 등의 정보가 저장될 수 있습니다. 이러한 특징 때문에 NoSQL 데이터베이스는 관계형 데이터베이스보다 유연하게 데이터를 저장할 수 있습니다. AWS의 대표적인 NoSQL 데이터베이스 서비스로는 DynamoDB와 DocumentDB가 있습니다. 두 서비스의 특징을 정리해 보면 다음과 같습니다.
구분 Amazon DynamoDB Amazon DocumentDB **데이터베이스 키-밸류 스토어 엔진 MongoDB 호환 고성능 엔진 엔진** 성능 모든 요청에 한 자릿수 밀리 확장 가능한 인메모리 최적화 초의 지연 시간을 제공하고, 아키텍처로 대규모 데이터 수요에 따라 확장해 성능 손실 세트에 대해 데이터베이스가 없이 초당 2천만 건 이상의 쿼리를 빠르게 평가할 수 있음 요청을 처리할 수 있음 가용성 고유한 스토리지 모델로 3개의 가용성 영역에 데이터 고가용성을 제공 사본 6개를 자동으로 복제해 99.99%의 가용성을 제공
만일, 서비스의 규모가 작다면 DynamoDB를 사용하는 것이 더 저렴하고, 서비스의 규모가 크다면 DocumentDB를 사용하는 것이 더 저렴합니다. 이는 DocumentDB가 DynamoDB보다 저렴한 가격에 보다 높은 성능을 제공하기 때문입니다.
구분 데이터베이스 오브젝트 스토리지 데이터 종류 관계형, 정형 데이터 비정형, 정적 데이터(사진, 동영상) 업데이트 주기 자주 업데이트 가끔 업데이트 동시성 엄격함 엄격하지 않음
스토리지의 개념과 특징
스토리지 서비스는 대량의 데이터를 안정적으로 저장할 때 필수적인 기능으로 파일, 이미지, 동영상, 로그 데이터, 백업 및 아카이브와 같은 비정형 데이터를 위한 중앙 집중식 저장 공간을 의미합니다. 비정형 데이터란 데이터의 크기와 형태를 미리 알 수 없다는 의미로 일반적인 파일을 생각하면 됩니다. 또는, 드롭 박스나 구글 드라이브와 같이 파일을 업로드해서 공유할 수 있는 서비스와 비슷합니다.
클라우드 스토리지 서비스는 여러 서버와 시설에 데이터를 복제해 장애로부터 데이터를 보호함으로써 고가용성을 제공하는 것이 필수적입니다. 또한, 필요할 때마다 스토리지 용량을 쉽게 확장할 수 있어 많은 양의 데이터를 빈번하게 접근해야 하는 경우에 적합합니다. 최근 중요성이 커지고 있는 AI/ML 관련 서비스를 구축할 때 필요한 데이터셋 또는 모델을 저장하고 관리하는데 많이 사용되고 있습니다.
S3(Simple Storage Service)
S3은 AWS에서 제공하는 오브젝트 스토리지 서비스입니다. 오브젝트 스토리지는 쉽게 말해서 문서, 이미지, 비디오 같은 컴퓨터 파일을 저장하는 공간입니다. 저장 공간 측면에서 S3은 사실상 무제한 데이터를 저장할 수 있습니다. 또한 각 오브젝트에 쉽게 접근할 수 있는 다양한 방법을 제공하고 있습니다. 오브젝트를 웹 브라우저에서 바로 다운로드 받는 것은 물론이고 다른 AWS 서비스에서도 간단한 방법으로 오브젝트를 업로드하고 다운로드할 수 있습니다.
S3은 데이터를 저장할 때 버킷(Bucket)이라는 개념을 사용합니다. 버킷은 S3에 데이터를 저장할 때 사용하는 저장소로 S3에 저장되는 모든 데이터의 컨테이너입니다. 버킷은 모든 AWS 리전에서 전역적으로 고유한 이름을 가져야 합니다. 즉, 하나의 리전에서 사용한 이름은 다른 리전에서 사용할 수 없습니다.
[TIP] S3 GlacierS3의 비용을 절감하기 위해 사용되는 서비스로 S3과 동일한 인터페이스를 제공하지만, 데이터를 저장하는 시간과 데이터를 검색하는 시간이 오래 걸립니다. 따라서 데이터를 자주 접근하지 않는 경우에 사용됩니다. 예를 들어, 1년에 한 번씩만 접근하는 데이터를 S3 Glacier에 저장하면 S3에 저장하는 것보다 훨씬 저렴하게 데이터를 저장할 수 있습니다.
[2] MySQL 만들기
이번에는 MySQL 데이터베이스를 만들어 보겠습니다. AWS RDS 대시보드로 이동한 후 우측 상단에서 [데이터베이스 생성] 버튼을 클릭합니다.
image-72.png
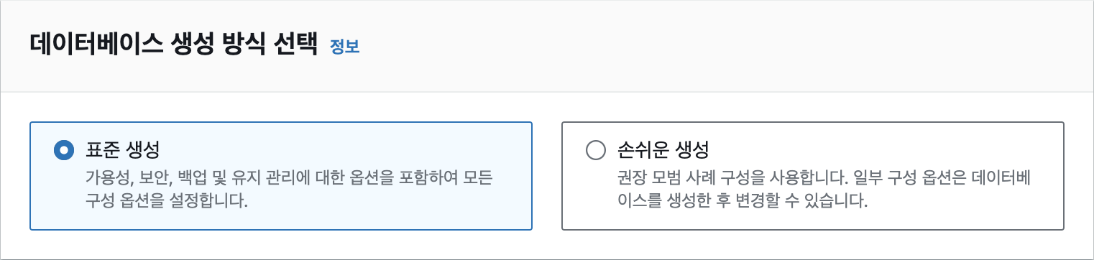
데이터베이스 생성 방식 선택에서 '표준 생성'을 선택합니다. 손쉬운 생성은 좀더 간편한 방식이지만 프리 티어를 사용하는 등의 설정을 하려면 '표준 생성'을 선택해야 합니다.
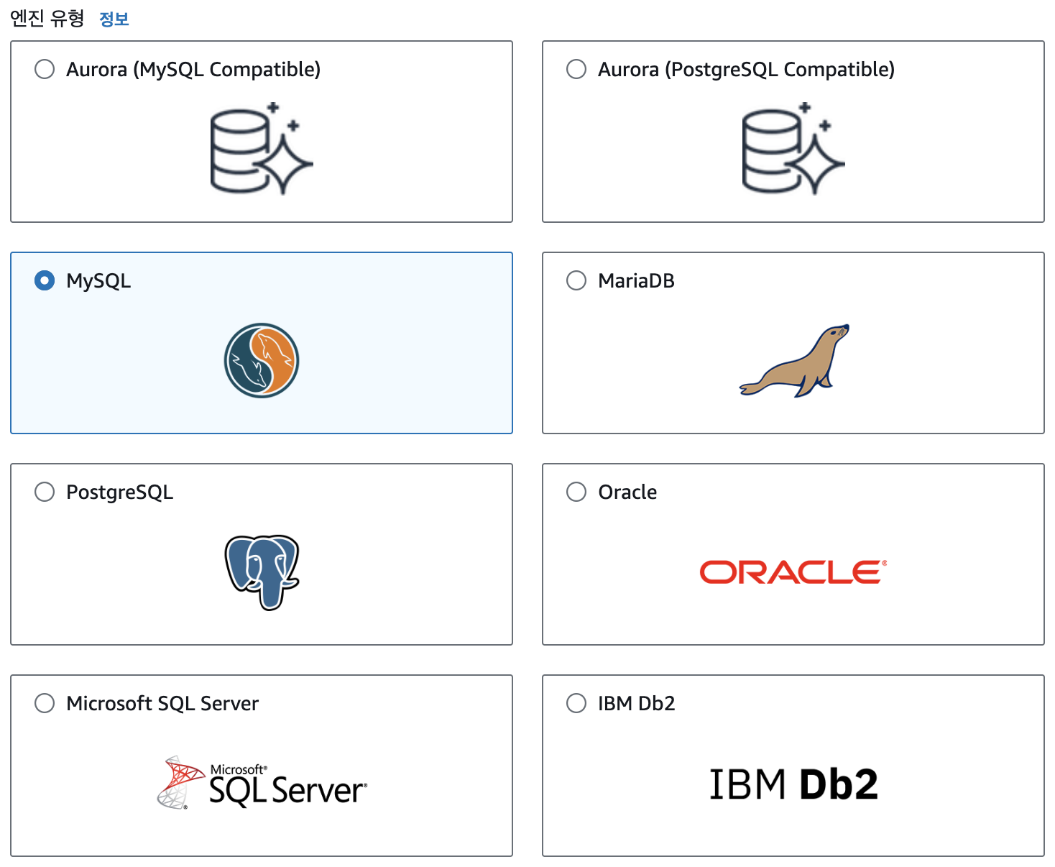
엔진 유형에서는 'MySQL'을 선택합니다. 참고로 엔진 버전은 바로 밑에서 확인할 수 있는데, 여기에서는 MySQL 8.0.33으로 진행하지만 최신 버전을 사용하면 됩니다.
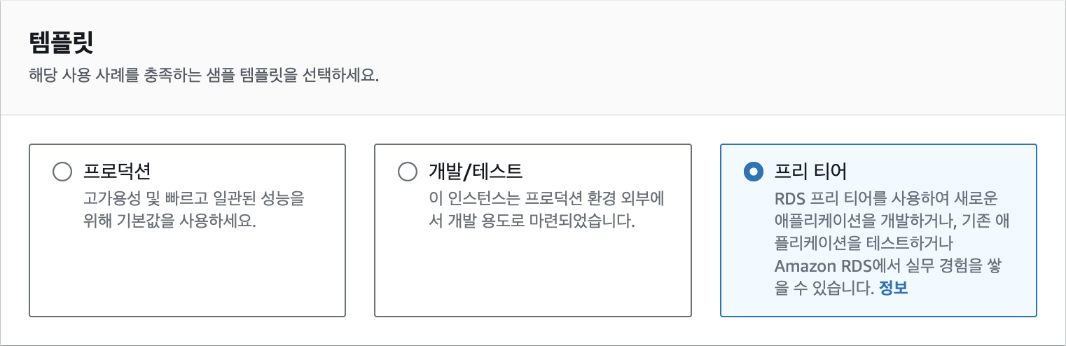
프리 티어를 적극적으로 활용하기 위해 템플릿은 '프리 티어'로 선택합니다.
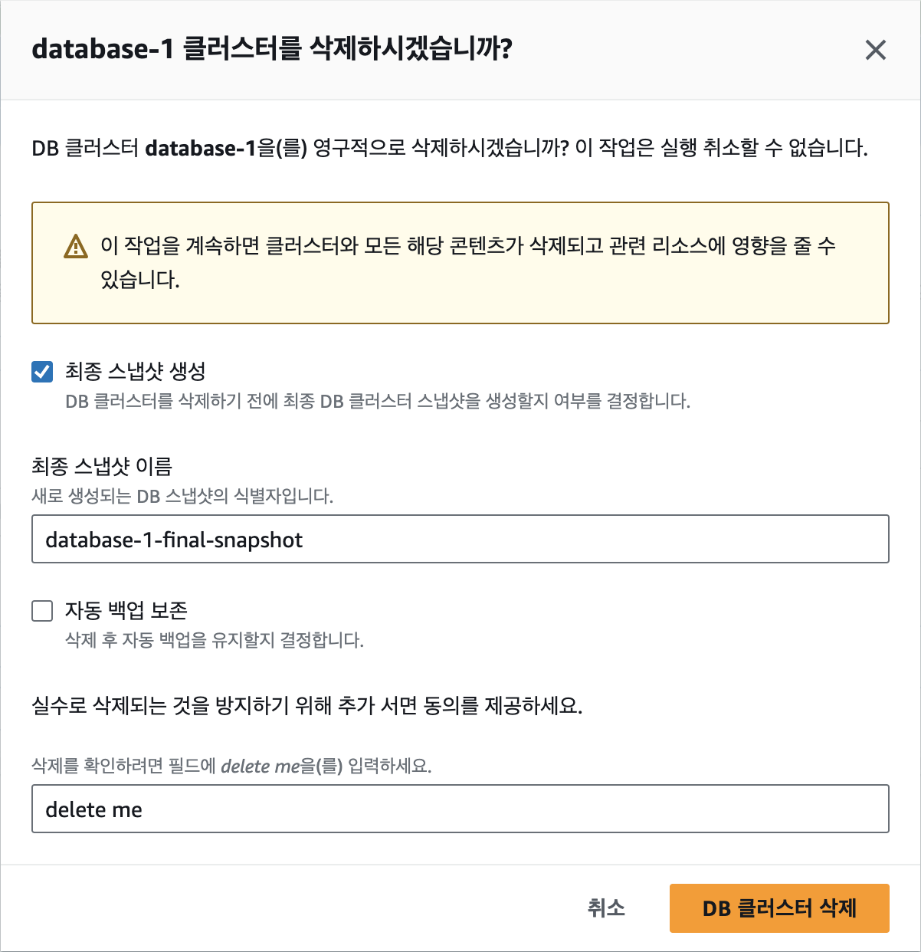
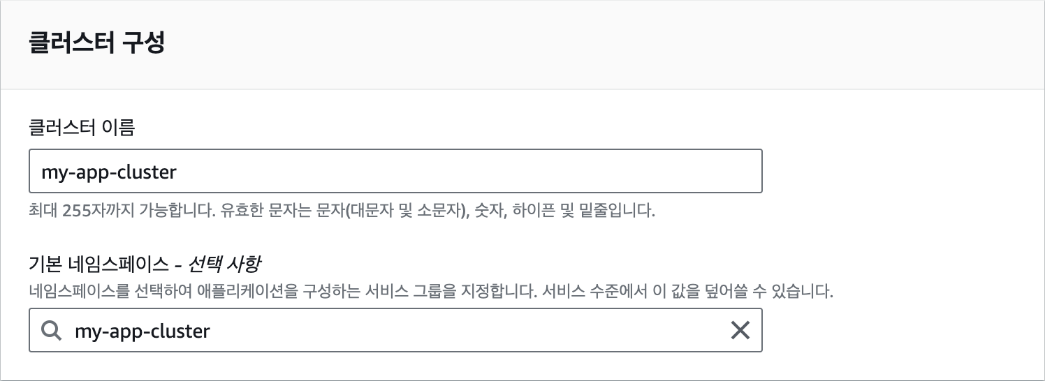
[설정] 탭에서 DB 클러스터 식별자로 기본값인 "database-1"이라는 이름을 입력합니다. DB 클러스터 식별자는 데이터베이스를 구분하기 위한 이름입니다.
자격 증명 설정에서 마스터 사용자 이름에 기본값인 "admin"을 입력하고, '암호 자동 생성'을 체크(선택)해 무작위로 생성되는 안전한 암호를 사용합니다. 실제 서비스에서도 암호를 직접 설정하는 대신 무작위 암호를 사용하는 것이 좋습니다. 암호는 추후 데이터베이스에 접속할 때 사용됩니다.
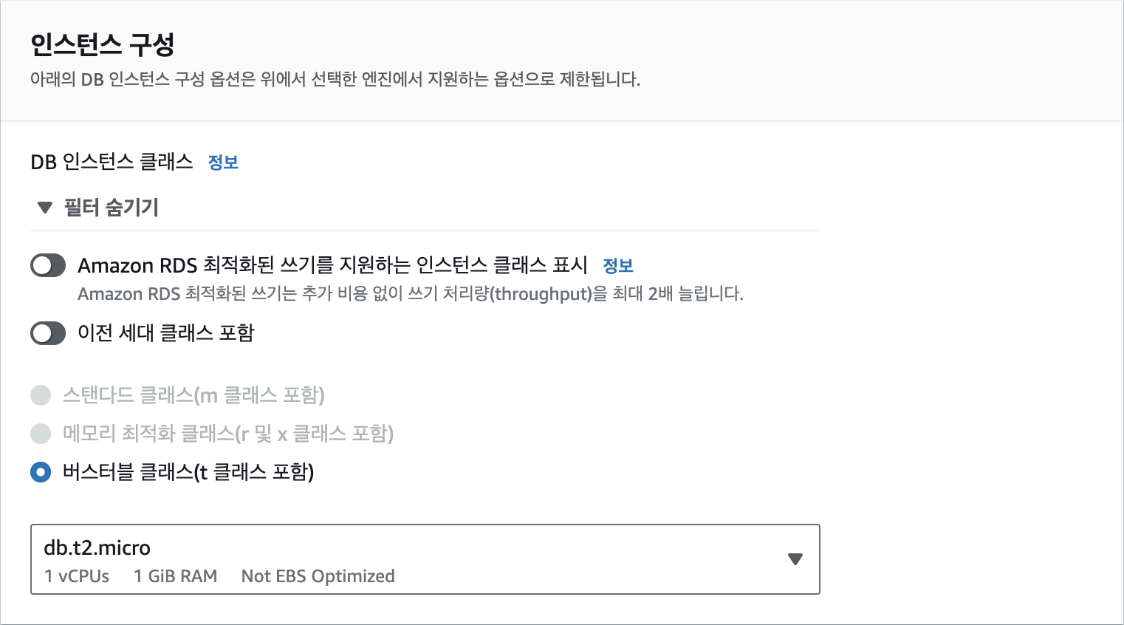
인스턴스 구성에서 DB 인스턴스 클래스는 가장 작은 크기인 [db.t2.micro]를 선택합니다.
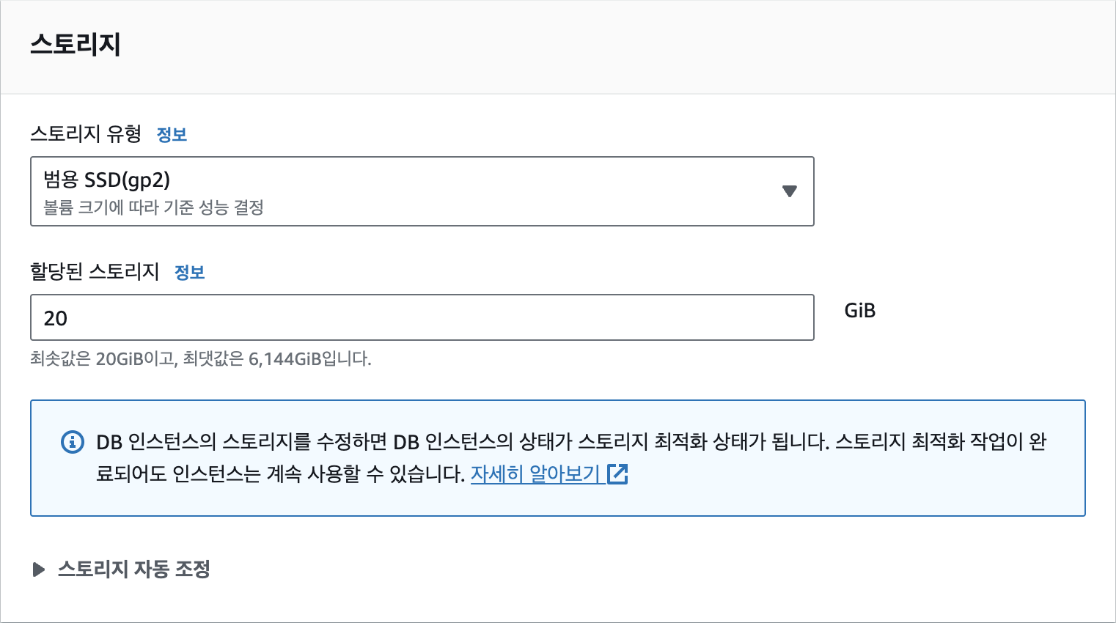
데이터를 저장할 스토리지에서는 최솟값인 '20GiB'로 설정합니다.
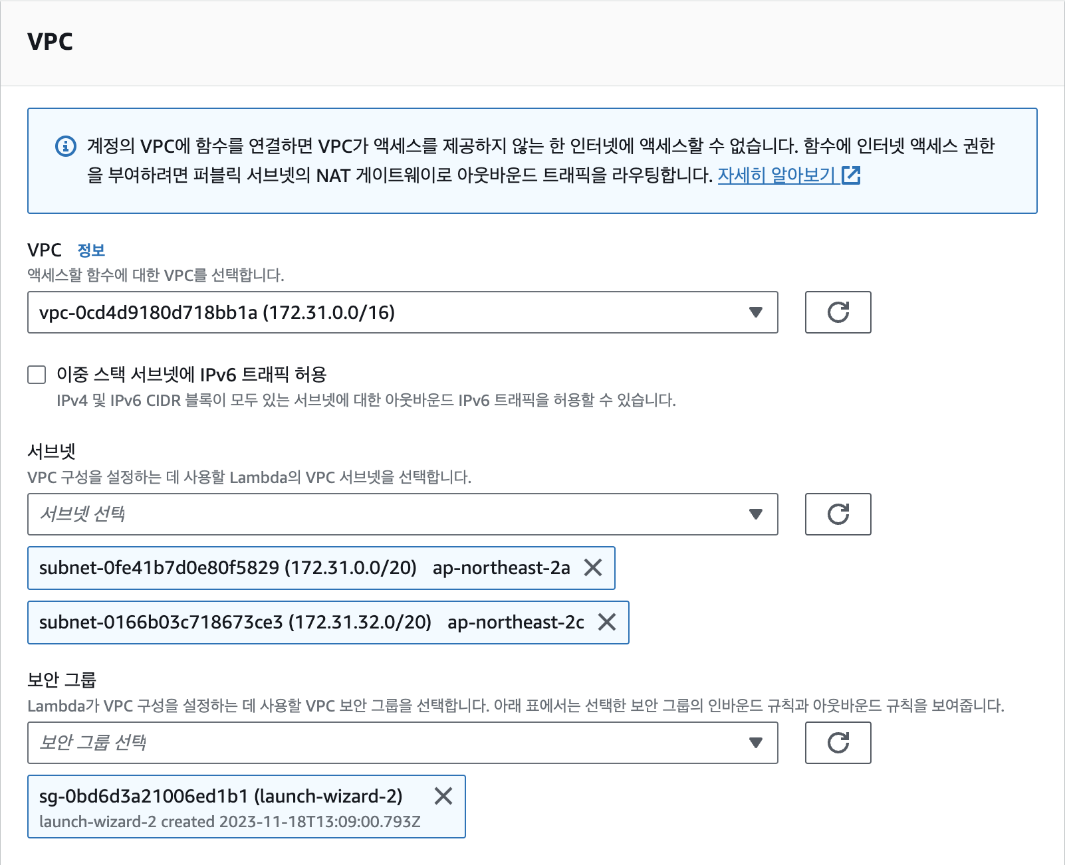
마지막으로 [연결] 탭에서 VPC가 EC2와 동일한 VPC와 보안 그룹으로 설정되어 있는지를 확인합니다. 데이터베이스가 생성된 다음에는 VPC를 변경할 수 없기 때문에 반드시 확인해야 합니다. EC2의 VPC를 확인하려면 EC2 대시보드의 [인스턴스 세부 정보]-[네트워킹]에서 VPC ID를 클릭하면 VPC 이름을 확인할 수 있습니다. 별도 VPC를 생성하지 않았다면 기본값인 'default'를 사용하면 됩니다. 보안 그룹 역시 EC2와 동일한 이름을 선택했는지 확인합니다.
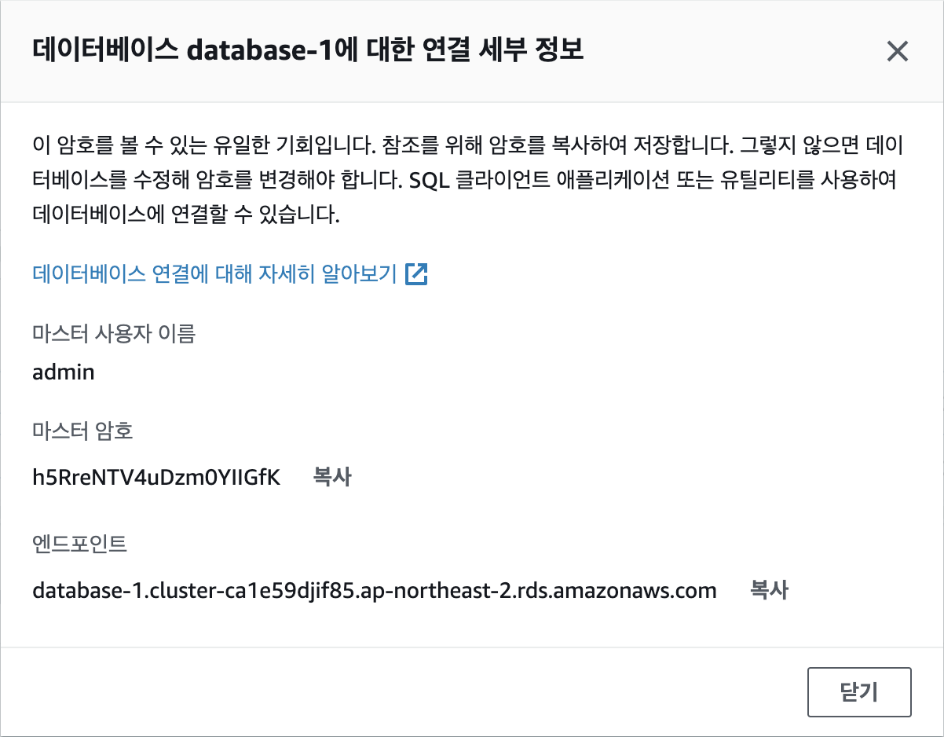
이제 [데이터베이스 생성] 버튼을 클릭합니다. 데이터베이스가 생성되는 데는 5~10분 정도의 시간이 소요됩니다. 데이터베이스가 생성되면 [연결 세부 정보 보기] 버튼을 클릭해 데이터베이스에 연결할 수 있는 접속 정보를 확인합니다.
image-80.png
해당 정보는 단 한 번만 확인할 수 있으므로 반드시 기록해야 합니다. 마스터 사용자 이름, 마스터 암호, 엔드포인트의 3가지를 복사해 둡니다.
마지막으로 EC2 인스턴스에서 RDS에 연결하기 위해서는 보안 그룹의 인바운드 규칙을 수정해야 합니다. EC2와 RDS에 공통으로 설정된 보안 그룹에서 인바운드 규칙에 다음의 규칙을 추가합니다. RDS MySQL는 접속 시 3306번 포트를 사용하기 때문에 보안 그룹에서 해당 포트 번호의 접속을 허용하는 것입니다.
EC2 터미널에 접속해
mysql-client를 설치합니다.mysql-client는mysql명령줄 도구를 터미널에서 사용할 수 있도록 해주는 패키지입니다. 다음의 명령어를 실행합니다.mysql명령어는 MySQL 서버에 접속해 데이터베이스를 관리하거나 데이터를 조회 및 수정 등을 할 수 있습니다. 참고로, 현업에서는mysql명령줄 도구보다 그래픽 화면이 지원되는 MySQL Workbench나 DBeaver와 같은 도구를 좀더 많이 사용합니다.$ sudo apt install mysql-client이제 EC2 인스턴스로 접속해 RDS에 연결해 보겠습니다. 이전에 복사해둔 마스터 사용자 이름, 마스터 암호, 엔드포인트를 사용합니다. 다음의 명령어를 실행합니다. 이때,
-h뒤의 엔드포인트는 복사해둔 것으로 바꾸어야 합니다. 명령어는admin사용자로 데이터베이스 엔드포인트에 접속하고,-p옵션을 사용해 비밀번호로 인증한다는 의미입니다.$ mysql -u admin -h database-1.cluster-something.ap-northeast-2.rds.amazonaws.com -p명령어를 입력하면 암호를 입력하라는 메시지가 나타납니다. 이때, 복사해둔 마스터 암호를 입력합니다.
$ Enter password:접속이 성공하면 다음과 같이
mysql>프롬프트가 나타납니다.Welcome to the MySQL monitor. Commands end with; or \g. Your MySQL connection id is 113 Server version: 8.0.28 Source distribution Copyright (c) 2000, 2023, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>이제 데이터베이스와 테이블을 만들어 보겠습니다. 먼저,
MY_APP데이터베이스를 생성하되 명령어는 다음과 같습니다.mysql> CREATE DATABASE MY_APP; Query OK, 1 row affected (0.00 sec)
MY_APP데이터베이스를 사용하겠다는 명령어는 다음과 같습니다.mysql> USE MY_APP; Database changed
Users테이블을 생성하는 명령어는 다음과 같습니다.mysql> CREATE TABLE Users ( -> id INT NOT NULL AUTO_INCREMENT, -> name VARCHAR(255) NOT NULL, -> age INT NOT NULL, -> PRIMARY KEY (id) -> ); Query OK, 0 rows affected (0.02 sec)이제 데이터베이스 설정이 완료되었습니다.
[2] MySQL 만들기
이번에는 MySQL 데이터베이스를 만들어 보겠습니다. AWS RDS 대시보드로 이동한 후 우측 상단에서 [데이터베이스 생성] 버튼을 클릭합니다.
데이터베이스 생성 방식 선택에서 '표준 생성'을 선택합니다. 손쉬운 생성은 좀더 간편한 방식이지만 프리 티어를 사용하는 등의 설정을 하려면 '표준 생성'을 선택해야 합니다.
엔진 유형에서는 'MySQL'을 선택합니다. 참고로 엔진 버전은 바로 밑에서 확인할 수 있는데, 여기에서는 MySQL 8.0.33으로 진행하지만 최신 버전을 사용하면 됩니다.
프리 티어를 적극적으로 활용하기 위해 템플릿은 '프리 티어'로 선택합니다.
[설정] 탭에서 DB 클러스터 식별자로 기본값인 "database-1"이라는 이름을 입력합니다. DB 클러스터 식별자는 데이터베이스를 구분하기 위한 이름입니다.
자격 증명 설정에서 마스터 사용자 이름에 기본값인 "admin"을 입력하고, '암호 자동 생성'을 체크(선택)해 무작위로 생성되는 안전한 암호를 사용합니다. 실제 서비스에서도 암호를 직접 설정하는 대신 무작위 암호를 사용하는 것이 좋습니다. 암호는 추후 데이터베이스에 접속할 때 사용됩니다.
인스턴스 구성에서 DB 인스턴스 클래스는 가장 작은 크기인 [db.t2.micro]를 선택합니다.
데이터를 저장할 스토리지에서는 최솟값인 '20GiB'로 설정합니다.
마지막으로 [연결] 탭에서 VPC가 EC2와 동일한 VPC와 보안 그룹으로 설정되어 있는지를 확인합니다. 데이터베이스가 생성된 다음에는 VPC를 변경할 수 없기 때문에 반드시 확인해야 합니다. EC2의 VPC를 확인하려면 EC2 대시보드의 [인스턴스 세부 정보]-[네트워킹]에서 VPC ID를 클릭하면 VPC 이름을 확인할 수 있습니다. 별도 VPC를 생성하지 않았다면 기본값인 'default'를 사용하면 됩니다. 보안 그룹 역시 EC2와 동일한 이름을 선택했는지 확인합니다.
이제 [데이터베이스 생성] 버튼을 클릭합니다. 데이터베이스가 생성되는 데는 5~10분 정도의 시간이 소요됩니다. 데이터베이스가 생성되면 [연결 세부 정보 보기] 버튼을 클릭해 데이터베이스에 연결할 수 있는 접속 정보를 확인합니다.
해당 정보는 단 한 번만 확인할 수 있으므로 반드시 기록해야 합니다. 마스터 사용자 이름, 마스터 암호, 엔드포인트의 3가지를 복사해 둡니다.
마지막으로 EC2 인스턴스에서 RDS에 연결하기 위해서는 보안 그룹의 인바운드 규칙을 수정해야 합니다. EC2와 RDS에 공통으로 설정된 보안 그룹에서 인바운드 규칙에 다음의 규칙을 추가합니다. RDS MySQL는 접속 시 3306번 포트를 사용하기 때문에 보안 그룹에서 해당 포트 번호의 접속을 허용하는 것입니다.
EC2 터미널에 접속해
mysql-client를 설치합니다.mysql-client는mysql명령줄 도구를 터미널에서 사용할 수 있도록 해주는 패키지입니다. 다음의 명령어를 실행합니다.mysql명령어는 MySQL 서버에 접속해 데이터베이스를 관리하거나 데이터를 조회 및 수정 등을 할 수 있습니다. 참고로, 현업에서는mysql명령줄 도구보다 그래픽 화면이 지원되는 MySQL Workbench나 DBeaver와 같은 도구를 좀더 많이 사용합니다.sudo apt install mysql-client이제 EC2 인스턴스로 접속해 RDS에 연결해 보겠습니다. 이전에 복사해둔 마스터 사용자 이름, 마스터 암호, 엔드포인트를 사용합니다. 다음의 명령어를 실행합니다. 이때,
-h뒤의 엔드포인트는 복사해둔 것으로 바꾸어야 합니다. 명령어는admin사용자로 데이터베이스 엔드포인트에 접속하고,-p옵션을 사용해 비밀번호로 인증한다는 의미입니다.mysql -u admin -h database-1.cluster-something.ap-northeast-2.rds.amazonaws.com -p명령어를 입력하면 암호를 입력하라는 메시지가 나타납니다. 이때, 복사해둔 마스터 암호를 입력합니다.
Enter password:접속이 성공하면 다음과 같이
mysql>프롬프트가 나타납니다.Welcome to the MySQL monitor. Commands end with `;` or `\g`. Your MySQL connection id is 113 Server version: 8.0.28 Source distribution Copyright (c) 2000, 2023, Oracle and/or its affiliates. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>이제 데이터베이스와 테이블을 만들어 보겠습니다. 먼저,
MY_APP데이터베이스를 생성하되 명령어는 다음과 같습니다.mysql> CREATE DATABASE MY_APP; Query OK, 1 row affected (0.00 sec)
MY_APP데이터베이스를 사용하겠다는 명령어는 다음과 같습니다.mysql> USE MY_APP; Database changed
Users테이블을 생성하는 명령어는 다음과 같습니다.mysql> CREATE TABLE Users ( -> id INT NOT NULL AUTO_INCREMENT, -> name VARCHAR(255) NOT NULL, -> age INT NOT NULL, -> PRIMARY KEY (id) -> ); Query OK, 0 rows affected (0.02 sec)이제 데이터베이스 설정이 완료되었습니다.
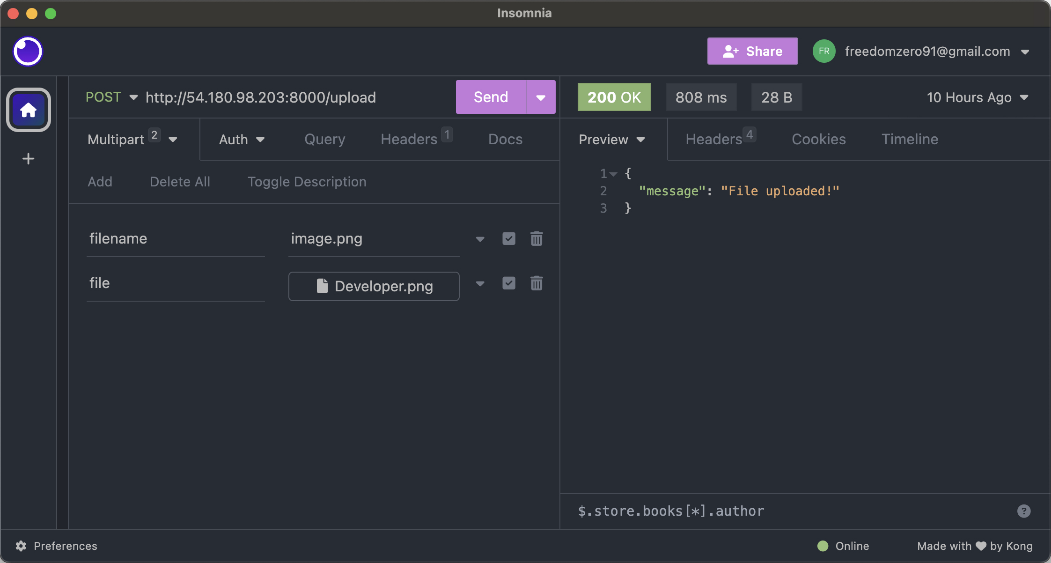
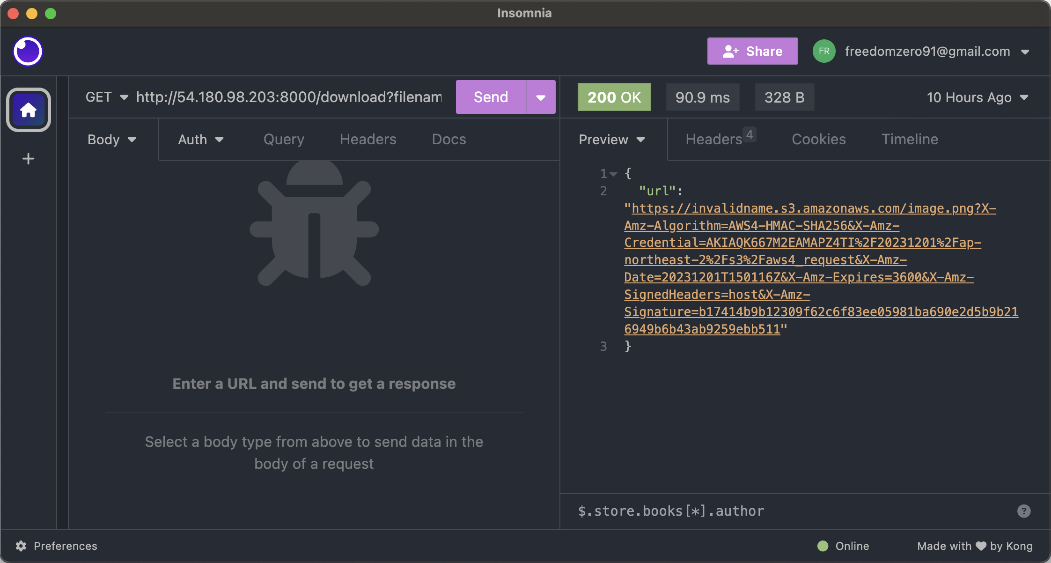
[3] S3 만들기
기본적으로 모든 S3 버킷과 오브젝트(저장된 파일)는 비공개이고, 접근 권한이 있는 인증된 사용자만 접근할 수 있습니다. 물론, S3은 특정 상황의 경우에 인터넷을 통해 버킷과 오브젝트를 다양한 수준으로 공개할 수 있는 옵션도 제공합니다. S3의 접근 제어 메커니즘에는 전체 S3 버킷 또는 개별 오브젝트를 공개적으로 접근할 수 있도록 하는 버킷 정책과 접근 제어 목록(ACL)이 있습니다. 예를 들면, 외부 사용자가 인터넷에서 파일을 다운로드할 수 있게 하거나 정적 웹 사이트를 S3를 통해 호스팅하는 경우에 접근 권한을 부여할 수 있습니다.
그러면 S3 버킷을 만들고 EC2에 연결해 보겠습니다. S3 콘솔로 이동한 후 [버킷 만들기] 버튼을 클릭합니다.
버킷 이름은 계정 이름과 같이 AWS 내에서 중복되지 않은 유일한 이름이어야 합니다. 본인 계정 내에서의 중복이 아닌 AWS에 존재하는 모든 버킷의 이름과 달라야 합니다.
그리고 S3 버킷과 버킷 내의 오브젝트를 외부에서 접근하는 '퍼블릭 액세스', 즉 인터넷을 통해 접근할 수 있는지를 설정합니다. 기본적으로 보안을 위해 모든 퍼블릭 액세스가 차단되지만 버킷의 오브젝트를 외부에서도 다운로드할 수 있도록 하기 위해서 미리 서명된 URL(Presigned URL)을 사용합니다. 미리 서명된 URL을 사용하면 별도의 인증 과정 없이도 특정 오브젝트에 제한된 시간 동안 접근할 수 있습니다. URL을 생성할 때 오브젝트를 읽기 전용으로만 접근하거나 읽기, 수정, 삭제 등의 전체 권한을 부여할 수도 있습니다. 따라서 AWS 외부에서 오브젝트에 접근할 경우 해당 방법이 가장 안전한 방법입니다.
퍼블릭 액세스를 허용하는 것은 매우 특별한 설정으로 버킷 내의 오브젝트에 중요하거나 민감한 정보가 있는 경우는 절대 퍼블릭 액세스를 허용해서는 안됩니다. 만일, 예외적으로 버킷과 모든 오브젝트를 퍼블릭으로 설정하려면 다음과 같이 체크 박스를 모두 해제하고, 하단의 경고 메시지에 체크 표시를 설정합니다.
나머지 설정은 기본으로 두고 버킷을 생성합니다. S3 대시보드에 다음과 같이 새로운 버킷이 생성된 것을 알 수 있습니다. 여기에서 '액세스'가 '버킷 및 객체가 퍼블릭이 아님'임을 꼭 확인해야 합니다.
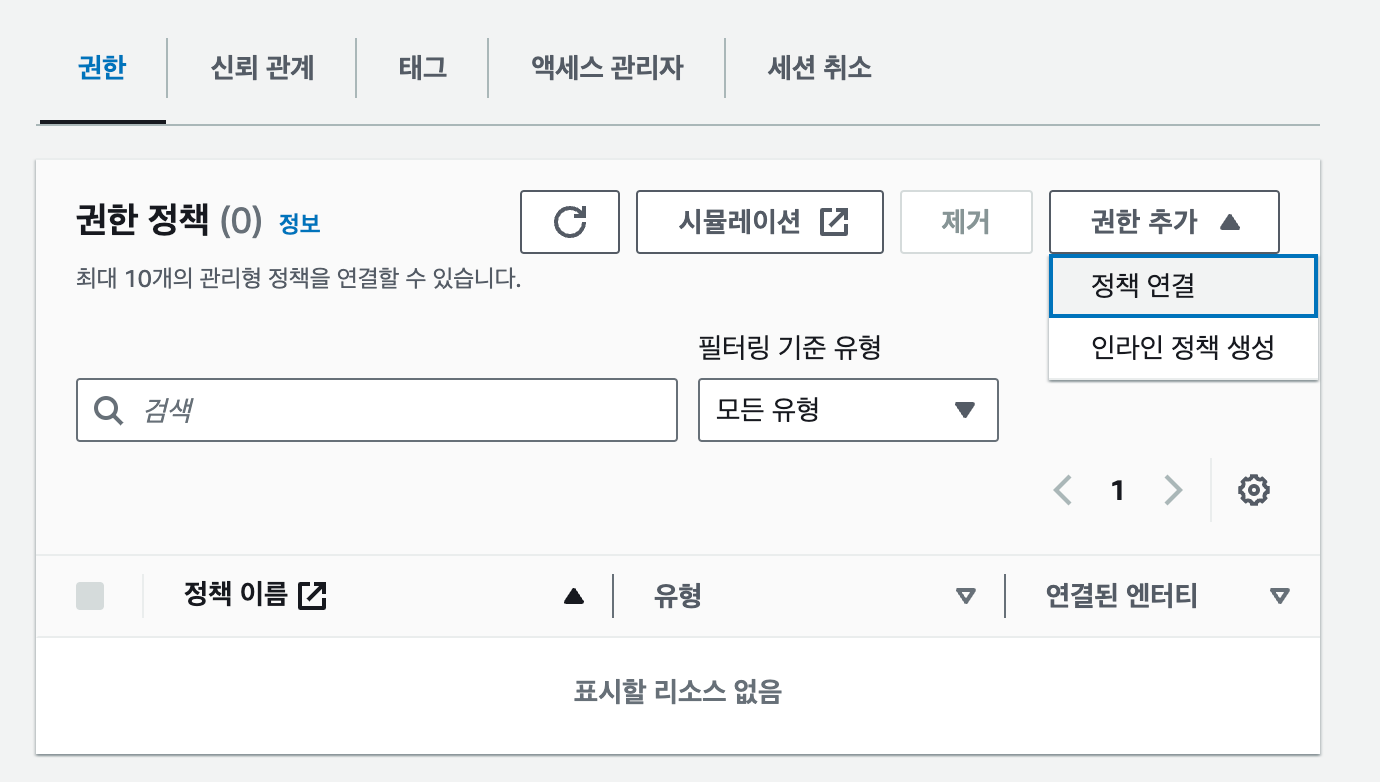
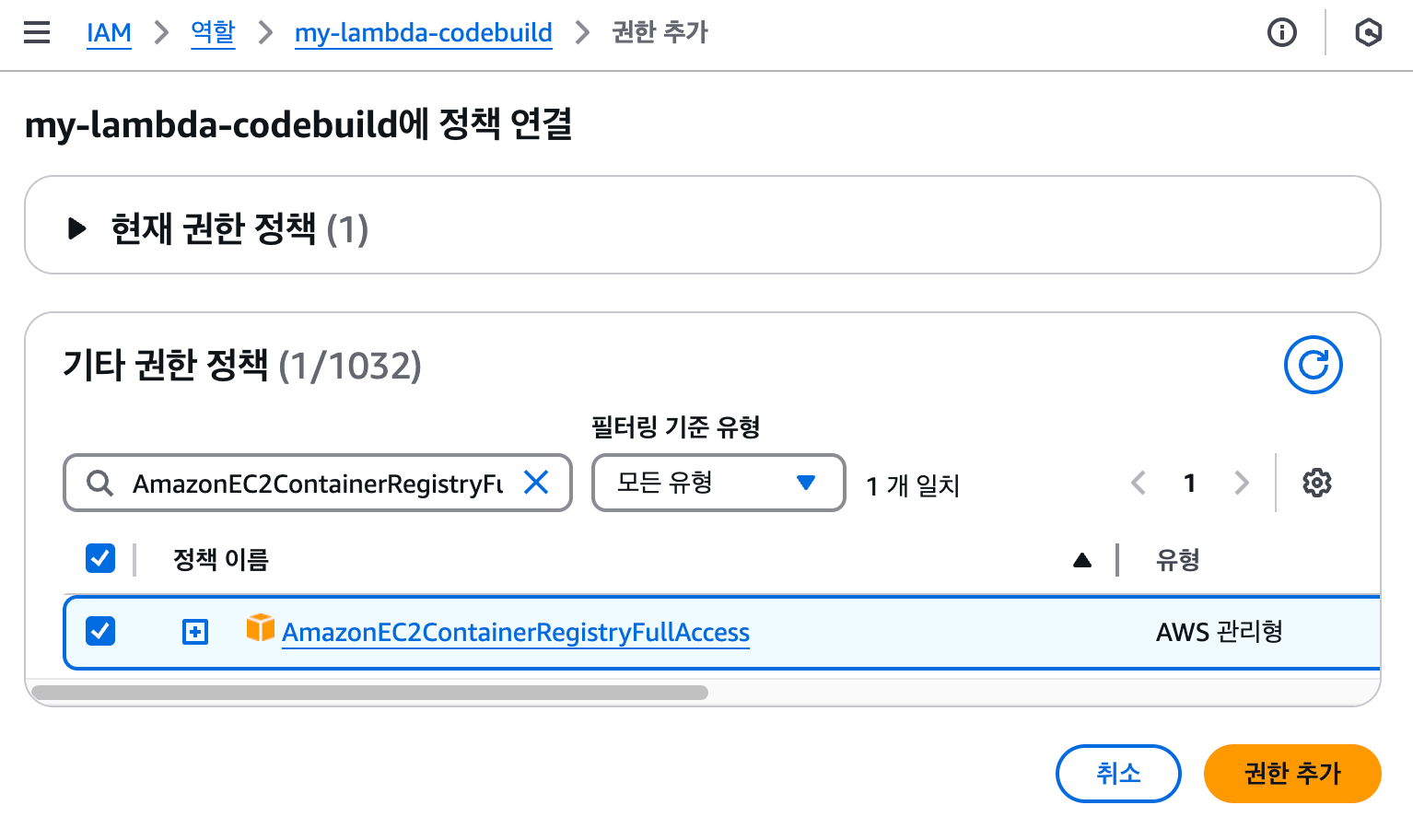
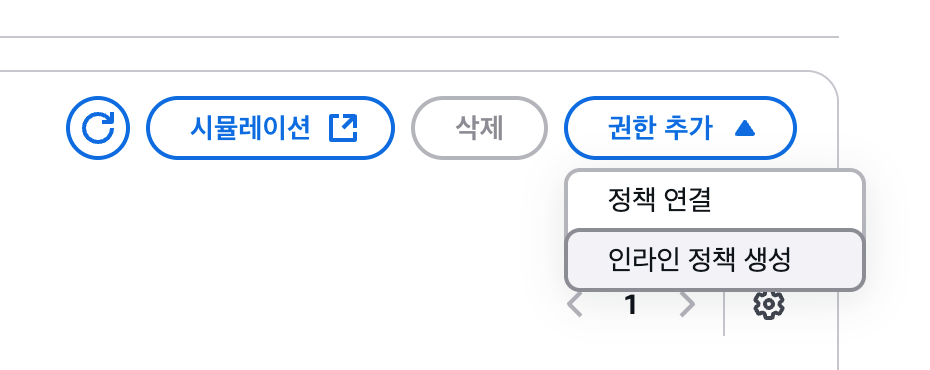
EC2와 Lambda가 연동하는 단계로 넘어가기 전에 S3 버킷과 오브젝트에 파일을 업로드할 수 있도록 권한을 추가해야 합니다. EC2의 경우는 기존에 만들었던 ec2-ecr-role에 권한을 추가하고, Lambda는 새로운 역할을 생성합니다. IAM 대시보드에서 ec2-ecr-role의 '권한 - 권한 정책' 패널로 이동합니다. 현재는 다음과 같이 2개의 정책만 있습니다. 우측의 [권한 추가] 버튼을 클릭하고, [인라인 정책 생성]을 선택합니다.
[TIP] 정책 생성정책 연결에서는 미리 만들어져 있는 정책을 편리하게 사용할 수 있습니다. 예를 들어, 'AmazonS3FullAccess' 정책을 역할에 부여하면 해당 역할을 부여받은 서비스는 S3의 모든 버킷과 객체에 대해 읽고 쓰고 삭제하는 등의 모든 작업을 할 수 있는 권한을 받게 됩니다. 하지만 너무 많은 권한을 부여하는 것은 의도치 않은 결과를 발생시킬 떄가 많습니다. 가급적이면 정책 연결을 사용하지 않고, 인라인 정책을 직접 생성해서 필요한 버킷 또는 객체에 대해 특정 작업만 할 수 있도록 정책을 생성하는 것이 좋습니다.
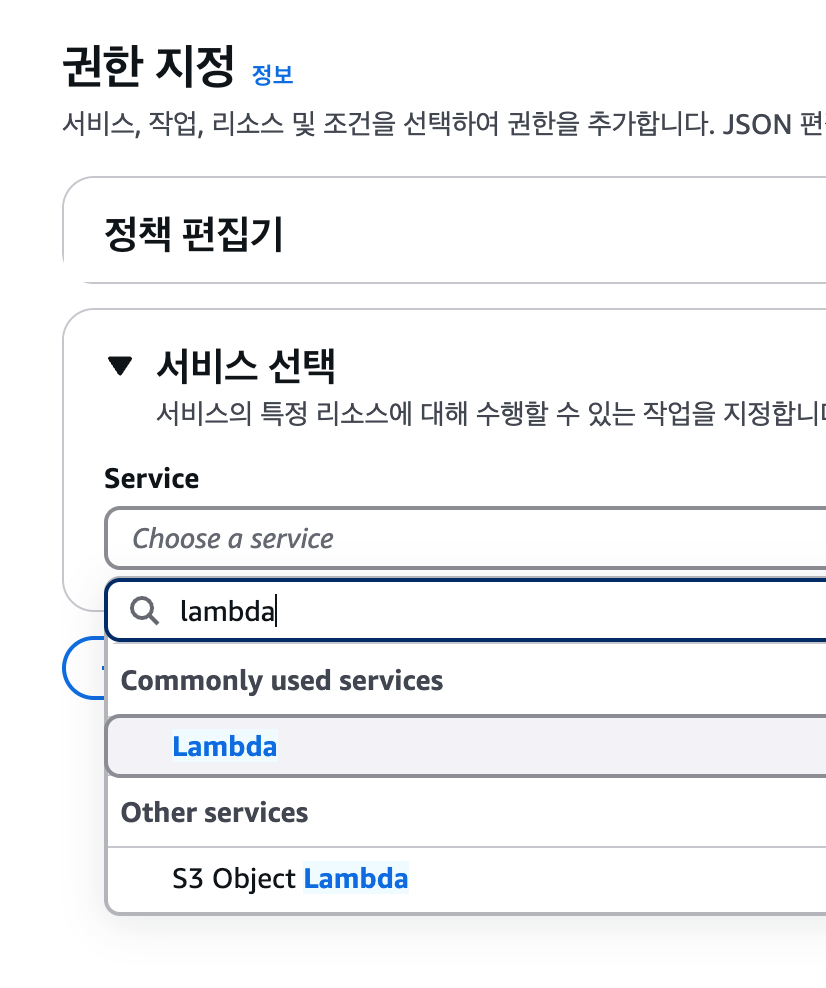
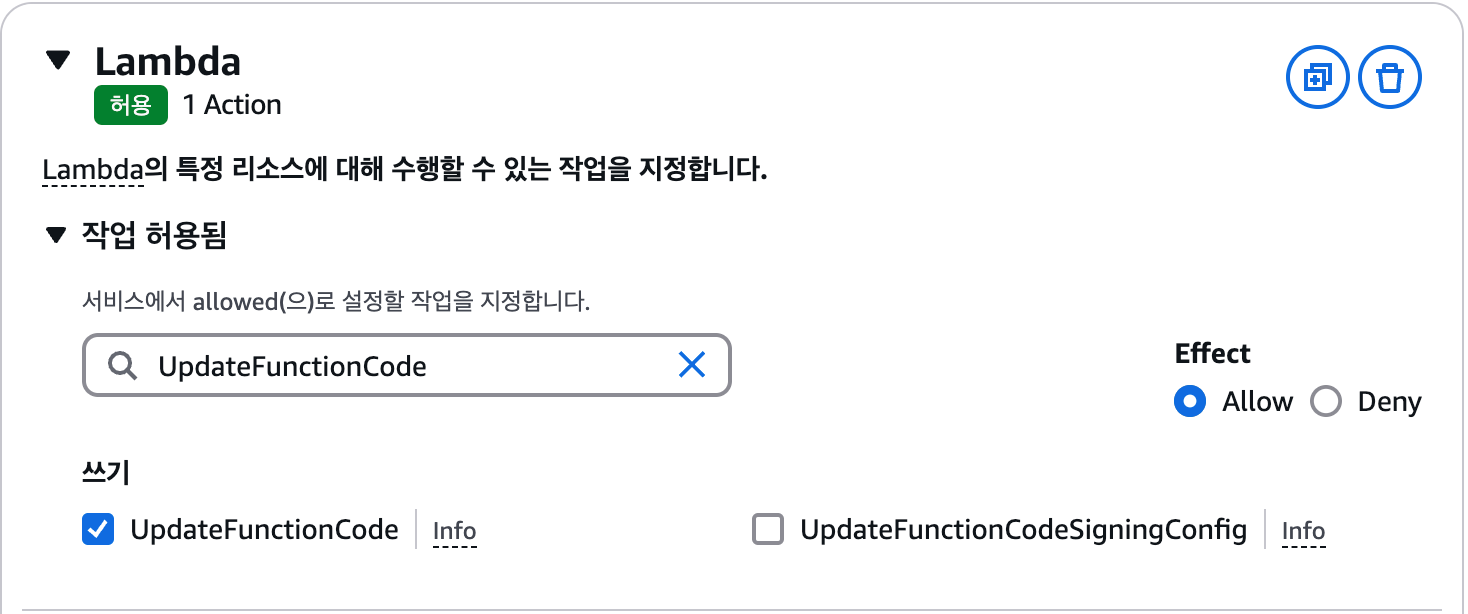
인라인 정책은 시각적 모드와 JSON 모드를 선택해 생성할 수 있습니다. AWS 정책에 익숙하지 않은 경우는 시각적 모드를 통해 원하는 정책을 직접 설정하는 것이 편리합니다. 먼저 시각적 모드로 정책을 만들어본 다음 JSON 모드를 살펴보겠습니다. 기본적으로는 시각적 모드가 선택되어 있기 때문에 바로 시작할 수 있습니다. 정책을 추가할 서비스 목록에서 S3를 선택한 다음 오브젝트를 업로드하고 다운로드할 수 있도록 작업을 추가합니다. 작업 필터링 입력란에 "PutObject", "GetObject"을 입력하고 각각 선택합니다. 총 2개의 작업이 선택되어 다음과 같은 화면이 되어야 합니다.
그 다음 작업의 대상이 될 버킷을 지정해야 합니다. 리소스 하단에서 'ARN 추가'를 클릭합니다.
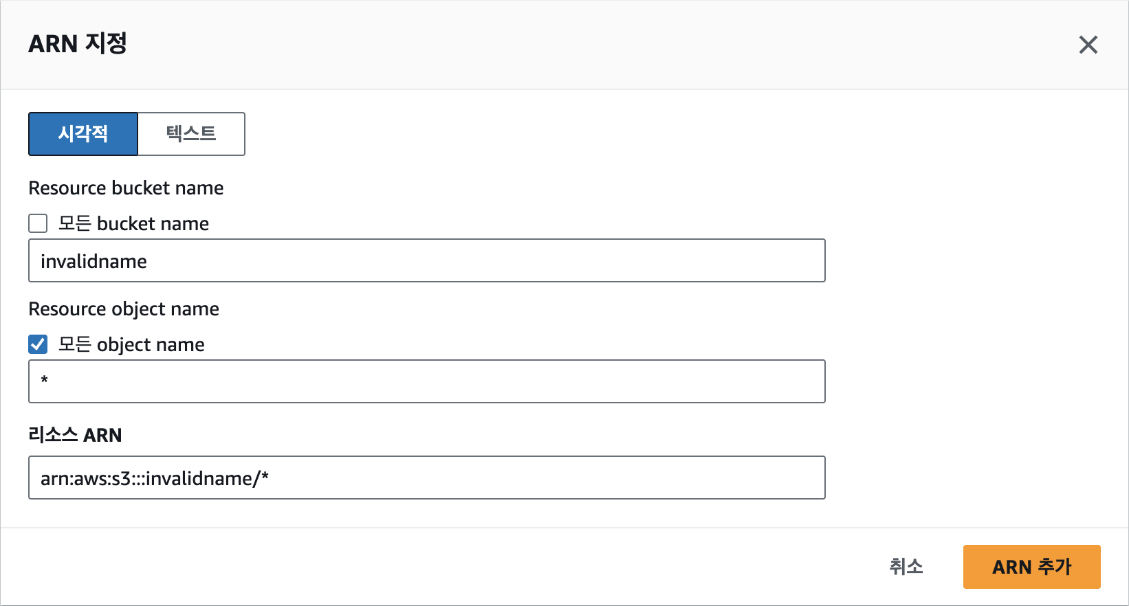
여기에서는 이전에 생성한 버킷 이름을 입력하고, 오브젝트는 전체를 의미하는 "*"를 입력한 다음 [ARN 추가] 버튼을 클릭합니다. '모든 bucket name'을 선택할 경우는 모든 버킷이 작업 대상이 되기 때문에 주의해야 합니다.
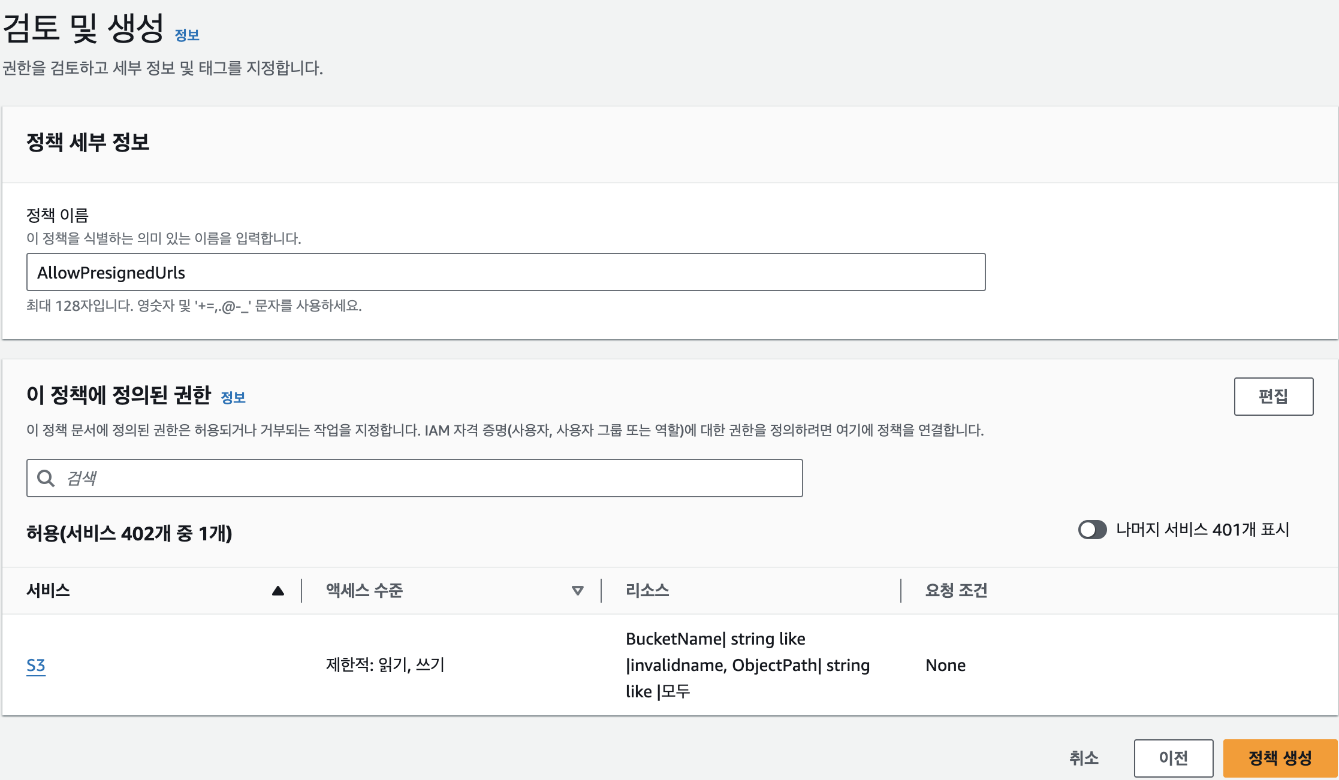
마지막으로 정책 내용을 검토합니다. 정책 이름에 "AllowPresignedUrls"을 입력하고, [정책 생성] 버튼을 클릭하면 정책이 만들어집니다.
만일, 시각적 모드가 아닌 JSON 모드를 사용해 정책을 만드는 경우는 다음과 같이 입력하면 됩니다. 시각적 모드에서 설정한 것처럼 PutObject와 GetObject 작업을 invalidname 버킷의 모든 오브젝트에 허용한다는 의미로 해당 코드는 생성된 정책에서 '정책 편집'을 클릭해 확인할 수도 있습니다.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowPresignedUrls", "Effect": "Allow", "Action": ["s3:PutObject", "s3:GetObject"], "Resource": "arn:aws:s3:::invalidname/*" } ] }[4] EC2와 연동하기
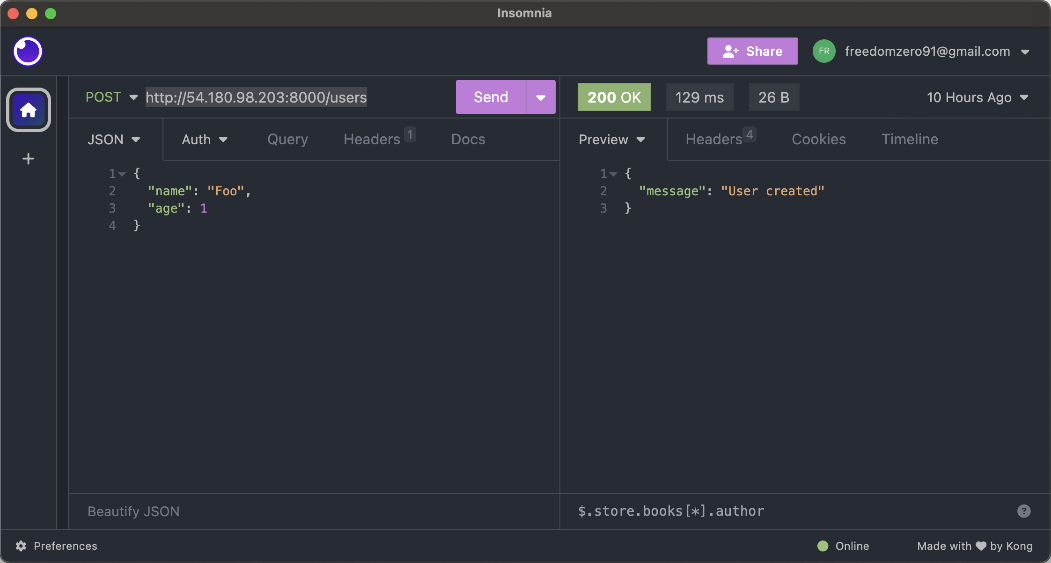
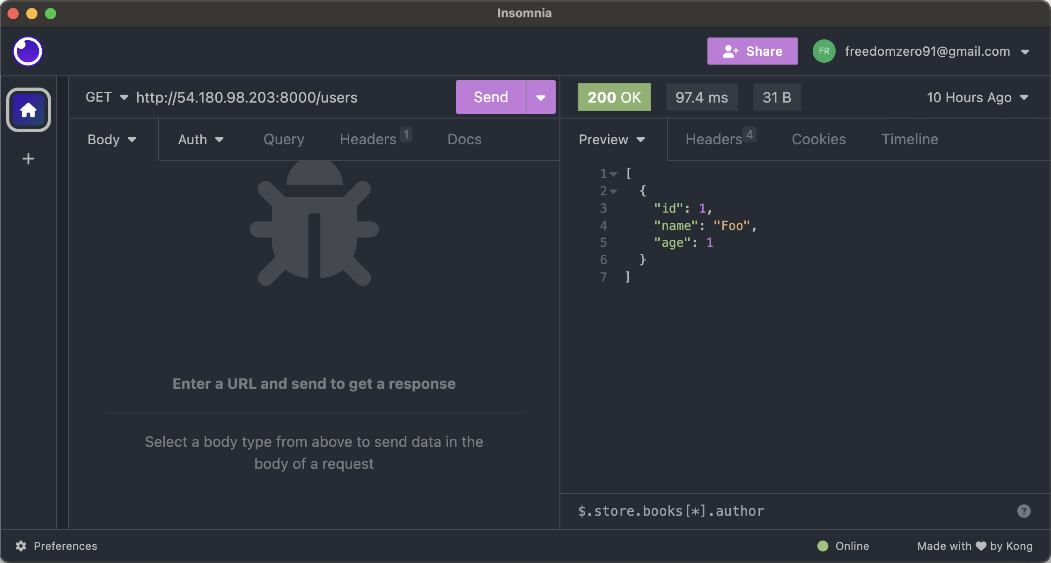
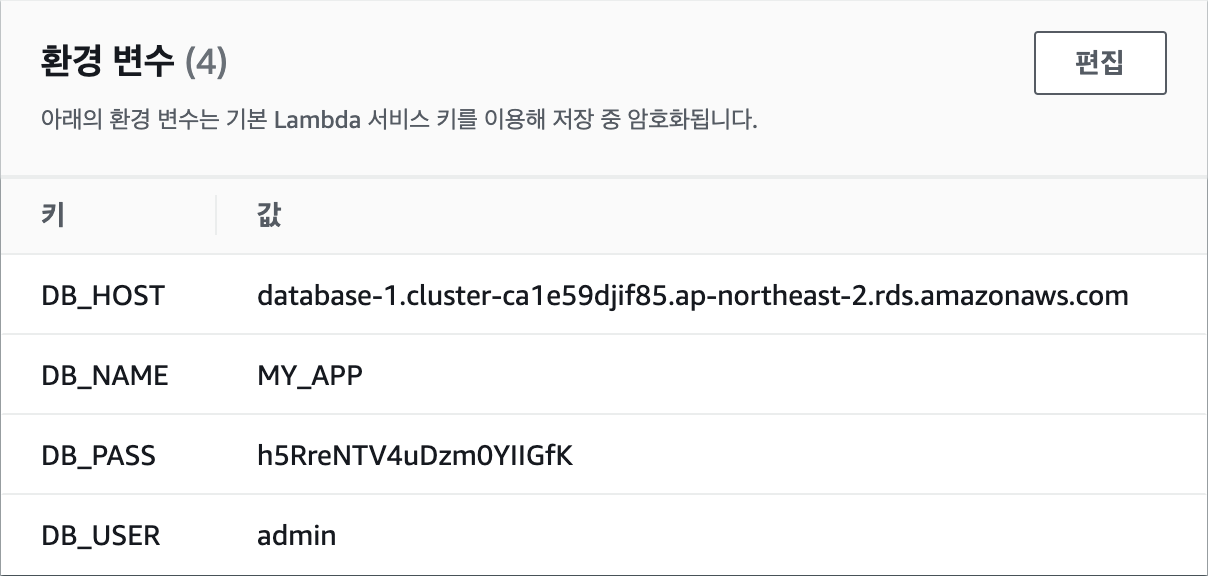
이제 EC2 인스턴스에서 FastAPI 서버를 실행해 RDS와 S3에 접근이 가능한지 확인해 보겠습니다. MySQL에서는 테이블에 데이터를 추가하고 읽을 수 있는지를 확인해 보고, S3에서는 파일을 업로드하고 미리 서명된 URL을 생성할 수 있는지를 확인해 보겠습니다. 파이썬에서 AWS 서비스를 사용하기 위해서는
boto3``이라는 라이브러리를 사용합니다. EC2 인스턴스로 접속한 다음, 터미널에서 다음과 같이boto3``을설치합니다.pip install boto3그리고 이전에 만들어 두었던
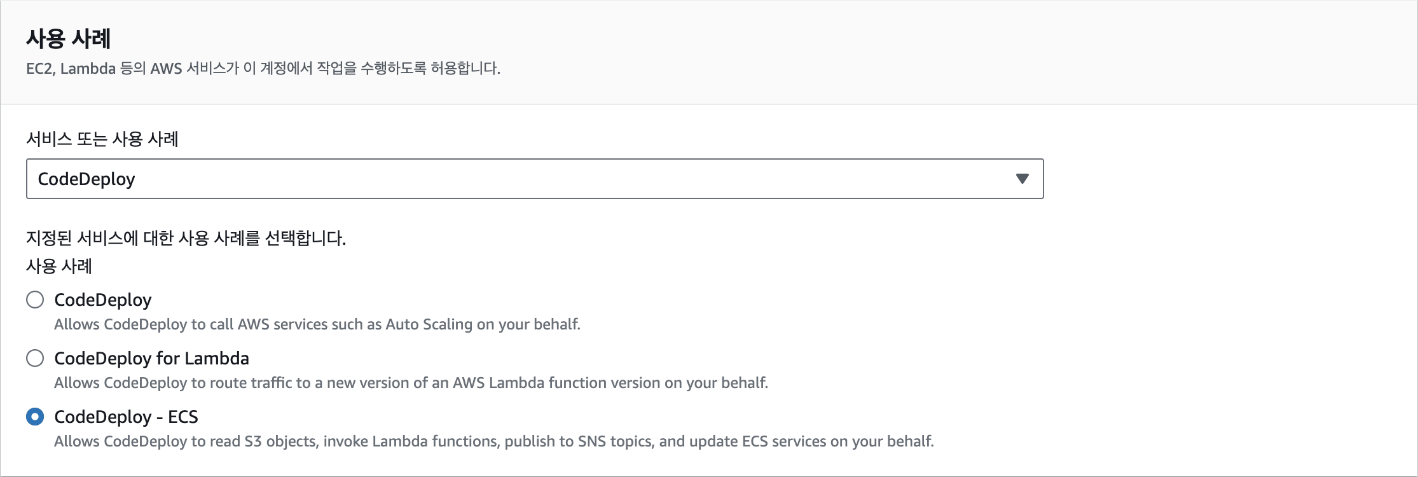
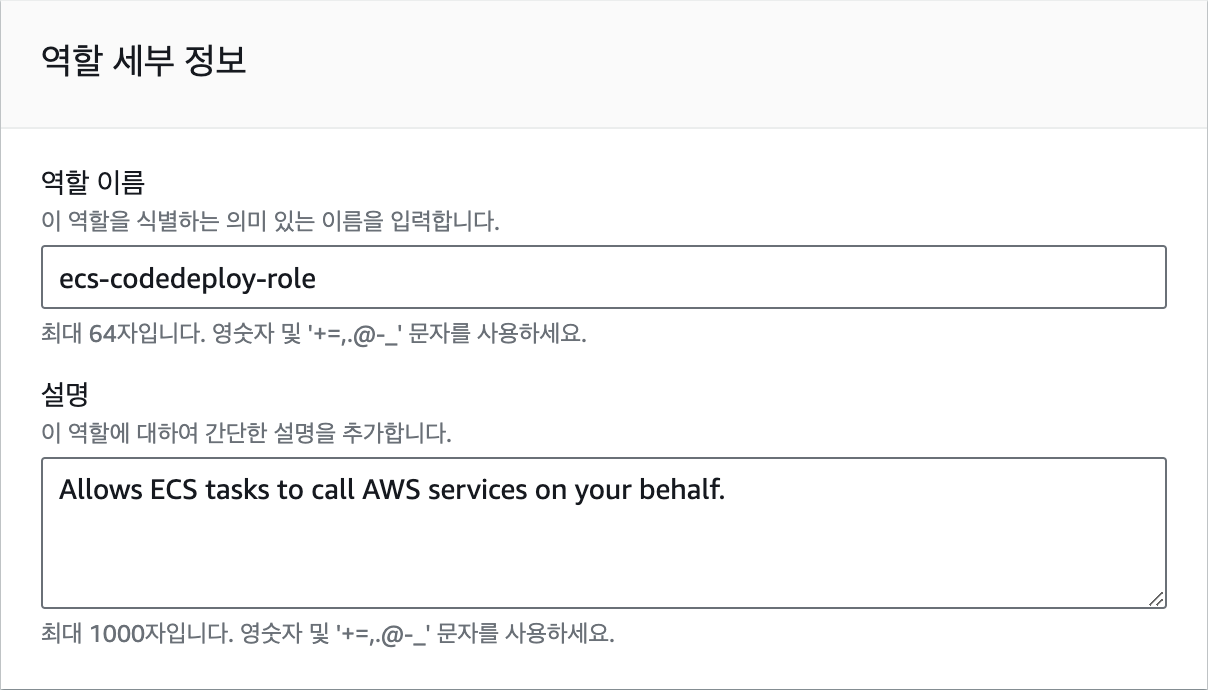
main.py파일의 내용을 수정하겠습니다. 이때, 코드에서 다음의 값들은 자신의 환경에 맞게 수정해야 합니다.
DB_HOST: 데이터베이스 엔드포인트DB_USER: 데이터베이스 사용자 이름DB_PASS: 데이터베이스 사용자 암호DB_NAME: 데이터베이스 이름(앞에서CREATE DATABASE MY_APP;으로 생성한 이름)BUCKET_NAME: S3 버킷 이름
main.py에 입력할 코드는 다음과 같습니다.from tempfile import SpooledTemporaryFile import pymysql import boto3 from fastapi import FastAPI, Depends, UploadFile, Form, File from pydantic import BaseModel app = FastAPI() DB_HOST = "database-1.cluster-ca1e59djif85.ap-northeast-2.rds.amazonaws.com" DB_USER = "admin" DB_PASS = "h5RreNTV4uDzm0YIIGfK" DB_NAME = "MY_APP" BUCKET_NAME = "invalidname" class User(BaseModel): id: int = None name: str age: int def get_db_client(): conn = pymysql.connect(host=DB_HOST, user=DB_USER, passwd=DB_PASS, db=DB_NAME) return conn @app.get("/users") async def get_users(client=Depends(get_db_client)) -> list[User]: cur = client.cursor() cur.execute("SELECT * FROM Users;") rows = cur.fetchall() return [User(id=row[0], name=row[1], age=row[2]) for row in rows] @app.post("/users") async def create_user(user: User, client=Depends(get_db_client)): cur = client.cursor() sql = "INSERT INTO Users (name, age) VALUES (%s, %s);" cur.execute(sql, (user.name, user.age)) client.commit() return {"message": "User created"} @app.post("/upload") async def upload_file(file: UploadFile = File(...), filename: str = Form(...)): temp_file = SpooledTemporaryFile() content = await file.read() temp_file.write(content) s3 = boto3.client("s3") s3.upload_fileobj(temp_file, BUCKET_NAME, filename) temp_file.close() return {"message": "File uploaded!"} @app.get("/download") async def download_file(filename: str): s3 = boto3.client("s3") try: presigned_url = s3.generate_presigned_url( "get_object", Params={"Bucket": BUCKET_NAME, "Key": filename}, ExpiresIn=3600, ) except Exception as e: print(e) return None return {"url": presigned_url}이제 서버를 실행하기 위해 다음의 명령어를 실행합니다. 하나의 컴퓨터에서는 하나의 포트와 하나의 프로그램만 사용이 가능합니다. 따라서 이전에 도커로 실행 중인 서버가 있다면 8000번 포트를 사용중인 프로그램이 있다는 의미이기 때문에 해당 컨테이너를 먼저 종료해야 파이썬 서버를 실행할 수 있습니다.
docker ps로 해당 컨테이너의 ID를 찾은 다음docker stop <ID>를 입력하면 됩니다.python3 -m uvicorn main:app --host 0.0.0.0서버에 접속해 요청을 보내기 위해서는 Insomnia에서 총 4개의 Request를 생성합니다. 먼저 데이터베이스에 값을 추가하는 엔드포인트를 만들어 보겠습니다. 메소드는 POST, 주소는
http://<서버 주소>:8000/users와 같이 입력합니다. 그리고 Body 탭에서 JSON을 선택하고 다음과 같이 입력합니다.{ "name": "Foo", "age": 1 }요청이 정상적으로 수행되면 다음과 같이 "User created"라는 응답을 받을 수 있습니다.
방금 생성된 값을 읽어오는 엔드포인트를 테스트해 보겠습니다. 메소드는 GET, 주소는
http://<서버 주소>:8000/users와 같이 입력합니다. 그러면 방금 생성한 값이 응답으로 돌아옵니다.
이번에는 S3에 이미지 파일을 업로드해 보겠습니다. 메소드는 POST, 주소는
http://<서버 주소>:8000/upload와 같이 입력합니다. 그리고 Body 탭에서 'Multipart Form'을 선택합니다. 첫 번째 항목 키는filename, 값은 image.png이고, 두 번째 항목 키는file입니다. 값의 경우는 우측의 목록 단추를 눌러 업로드할 'File'을 선택합니다. 파일을 선택하고 요청을 보내면 "File uploaded!" 응답을 받게 됩니다.
방금 업로드한 파일을 다운로드 받을 수 있는 사전 서명된 URL을 받아보겠습니다. 메소드는 GET, 주소는
http://<서버 주소>:8000/download?filename=image.png와 같이 입력합니다. 응답으로 URL이 오게 되는데 해당 주소로 접속해 보면 아까 업로드한 파일을 인터넷에서 다운로드 받을 수 있습니다.
[5] Lambda와 연동하기
Lambda를 사용하기 위해서는 방금 살펴본 EC2 코드를 두 개의 Lambda 로 분할해서 하나의 함수가 하나의 기능만 갖도록 해야 합니다. 그러기 위해서 MySQL을 사용하는 도커 이미지와 S3을 사용하는 도커 이미지를 각각 빌드하겠습니다. 첫 번째로 MySQL을 사용하는 도커 이미지를 빌드하기 위해 Lambda 코드를 작성했던 폴더를 VSCode로 연 다음
app_rds.py파일을 다음과 같이 생성합니다.import json import os import pymysql from pymysql.err import OperationalError DB_HOST = os.environ["DB_HOST"] DB_USER = os.environ["DB_USER"] DB_PASS = os.environ["DB_PASS"] DB_NAME = os.environ["DB_NAME"] def lambda_handler(event, context): try: conn = pymysql.connect(host=DB_HOST, user=DB_USER, passwd=DB_PASS, db=DB_NAME) except OperationalError: return {"error": "Could not connect to MySQL database"} http_method = event["httpMethod"] if http_method == "GET": return get_users(conn) elif http_method == "POST": user_data = json.loads(event["body"]) return create_user(user_data, conn) def get_users(conn): cur = conn.cursor() cur.execute("SELECT * FROM Users;") rows = cur.fetchall() return {"statusCode": 200, "body": json.dumps({"users": rows})} def create_user(user, conn): cur = conn.cursor() sql = "INSERT INTO Users (name, age) VALUES (%s, %s);" cur.execute(sql, (user["name"], user["age"])) conn.commit() return {"statusCode": 200, "body": "User created successfully!"}그리고 MySQL을 사용하는 도커 이미지를 빌드하기 위해
Dockerfile_rds를 다음과 같이 생성합니다.FROM public.ecr.aws/lambda/python:3.11 RUN pip3 install pymysql COPY app_rds.py ${LAMBDA_TASK_ROOT}/lambda_function.py CMD [ "lambda_function.lambda_handler" ]해당 도커파일로부터 도커 이미지를 빌드하고 ECR의 my_lambda 레포지토리에 푸시합니다. 이때, 이미지 태그를
rds로 설정합니다.docker build -f Dockerfile_rds -t 000000000000.dkr.ecr.ap-northeast-2.amazonaws.com/my_lambda:rds . docker push 000000000000.dkr.ecr.ap-northeast-2.amazonaws.com/my_lambda:rds만일, 다음과 같이 에러가 발생하는 경우는 AWS CLI를 사용해 다시 로그인해야 합니다.
"denied: Your authorization token has expired. Reauthenticate and try again."3장에서
aws ecr get-login-password ...명령어를 찾아보세요.이제 푸시된 이미지를 가지고 새로운 Lambda 함수(rds)를 컨테이너 이미지로 생성합니다. 이때, 실행 역할은 기존 역할을 선택하면 되는데, 예전에 만들었던 my_lambda-role로 자동으로 설정되는 것을 볼 수 있습니다.
이때, 실행 역할에서 '기존 역할 사용'을 선택하고, 기존 역할에서 예전에 만들었던 my_lambda-role를 설정합니다.
그 다음 Lambda가 MySQL에 접근하고 사용할 수 있도록 역할에 권한을 부여해야 합니다. IAM 대시보드에서 역할 my_lambda-role에 다음의 두 정책을 추가합니다.
AmazonRDSDataFullAccess: MySQL을 사용할 수 있는 권한AWSLambdaVPCAccessExecutionRole: MySQL이 존재하고 VPC에 접근할 수 있는 권한다시 Lambda로 돌아와서 [구성]-[VPC]-[VPC 편집]에서 VPC와 보안 그룹을 설정합니다. VPC와 보안 그룹은 EC2와 동일한 것을 선택하고, 서브넷은 현재 리전에서 사용 가능한 서브넷 중 RDS 이름이 붙어있지 않은 두 개를 선택합니다.
이전과 다르게 소스 코드에는 데이터베이스 연결에 필요한 정보를 입력하지 않았습니다. 연결에 필요한 정보를 환경 변수로부터 읽어오도록 되어 있기 때문에 추후 데이터베이스 연결 정보가 바뀌는 경우 소스 코드는 그대로 두고 환경 변수만 바꿔주면 됩니다. 특히, 비밀번호와 같은 민감한 정보는 소스 코드에 포함시키기보다 환경 변수로 두는 것이 좋은 방법입니다. 환경 변수는 [구성]-[환경 변수]에서 추가할 수 있습니다. 환경 변수는 다음과 같이 4개를 추가합니다.
이때, 하단의 암호화 구성에서 환경 변수를 암호화해 저장할 수 있습니다. AWS KMS(Key Manage Service)에서 AWS가 관리하는 암호화 키인
aws/lambda를 기본값으로 선택하면 됩니다. 이렇게 암호화된 환경 변수는 Lambda 함수가 실행될 때 자동으로 복호화 되어 사용됩니다. KMS 관리 키가 아닌 사용자 지정 키를 사용할 수도 있지만 추가 요금이 발생합니다.
마지막 단계로 API 게이트웨이를 연결합니다. 화면 상단의 다이어그램에서 [트리거 추가] 버튼을 클릭합니다.
트리거 추가에서는 [API Gateway]를 선택한 후 Intent는 'Create a new API', API type은 'REST API'를 각각 선택합니다. HTTP API는 좀더 저렴하고 기본적인 기능만 제공하기 때문에 단순한 애플리케이션에 적합합니다. 반면 REST API는 다양한 편의 기능을 갖추고 있어서 추후 파일을 업로드하고 다운로드 받을 때 유용합니다. Security는 'Open'을 선택해 추가 인증 없이 API 호출이 가능하도록 합니다. 참고로 현업에서는 Bearer token 등을 사용해서 애플리케이션 단위로 인증하거나 OIDC를 사용해 클라우드 전체 단위로 인증을 수행하는 것이 일반적입니다.
[추가] 버튼을 클릭하면 다음과 같이 API Endpoint를 확인할 수 있는데, 나중에 해당 주소로 API 요청을 보내면 Lambda 함수가 실행됩니다.
이제 Lambda 함수를 테스트해 보겠습니다. 소스 코드에서 HTTP 메소드를
event파라미터로부터 읽어오도록 설정했는데, 해당 정보는 API 게이트웨이에서 제공하는 것이기 때문에 Lambda 함수를 테스트하려면 반드시 API Gateway에서 제공되는 엔드포인트를 사용해야 합니다. 예를 들어서 엔드포인트가https://s2uhma6dn3.execute-api.ap-northeast-2.amazonaws.com/default/rds라면 GET 요청을 통해 유저 목록을 받을 수 있고, POST 요청을 통해 새로운 유저를 추가할 수 있습니다.이번에는 S3을 사용하는 Lambda를 만들어 보겠습니다. S3 버킷에 파일을 업로드하고, 미리 서명된 URL의 생성 코드를
app_s3.py파일로 분리합니다.app_s3.py파일은 다음과 같습니다.import json import base64 from io import BytesIO from tempfile import SpooledTemporaryFile from multipart import parse_form_data import boto3 BUCKET_NAME = "invalidname" s3 = boto3.client("s3") def lambda_handler(event, context): http_method = event["httpMethod"] if http_method == "POST": form, files = parse_form_data( { "CONTENT_TYPE": event["headers"]["content-type"], "REQUEST_METHOD": "POST", "wsgi.input": BytesIO(base64.b64decode(event["body"])), } ) return upload_file(files["file"].file.read(), form["filename"]) elif http_method == "GET": filename = event["queryStringParameters"]["filename"] return download_file(filename) def upload_file(data, filename): temp_file = SpooledTemporaryFile() temp_file.write(data) s3.upload_fileobj(temp_file, BUCKET_NAME, filename) temp_file.close() return {"statusCode": 200, "body": "File uploaded!"} def download_file(filename): try: url = s3.generate_presigned_url( "get_object", Params={"Bucket": BUCKET_NAME, "Key": filename}, ExpiresIn=3600, ) except Exception as e: print(e) return {"statusCode": 500, "error": "Failed to generate download URL"} return {"statusCode": 200, "body": json.dumps({"url": url})}이제 다음의 내용으로
Dockerfile_s3파일을 생성합니다.FROM public.ecr.aws/lambda/python:3.11 RUN pip3 install boto3 multipart COPY app_s3.py ${LAMBDA_TASK_ROOT}/lambda_function.py CMD [ "lambda_function.lambda_handler" ]도커 이미지를 빌드하고 ECR의 my_lambda 레포지토리에 푸시합니다. 이때, 이미지 태그를
s3로 설정합니다.docker build -f Dockerfile_s3 -t 000000000000.dkr.ecr.ap-northeast-2.amazonaws.com/my_lambda:s3 . docker push 000000000000.dkr.ecr.ap-northeast-2.amazonaws.com/my_lambda:s3이제 푸시된 이미지를 가지고 새로운 Lambda 함수 s3을 컨테이너 이미지로 생성합니다. 이때, 실행 역할은 예전에 만들었던 my_lambda-role로 설정합니다. 이번에도 IAM 대시보드에서 역할 권한을 수정해야 합니다. 역할 my_lambda-role에 인라인 정책으로 다음을 추가합니다.
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowPresignedUrls", "Effect": "Allow", "Action": ["s3:PutObject", "s3:GetObject"], "Resource": "arn:aws:s3:::invalidname/*" } ] }이제 API Gateway를 생성하고 연결합니다. MySQL을 사용하는 Lambda와 동일하게 트리거에 API Gateway를 설정합니다. API Gateway를 연결했다면 API Gateway 대시보드로 이동한 후 좌측 메뉴 목록에서 [API 설정]을 선택합니다.
페이지 중간에서 '이진 미디어 유형' 패널을 찾아 [미디어 유형 관리]를 클릭합니다.
이진 미디어는 문서나 이미지 같은 일반 파일 데이터를 의미합니다. API가 호출될 때
Content-Type헤더를 통해서 전송되는 데이터 종류를 알 수 있는데, 여기에서 이진 미디어 유형을 정의하면 해당 값이 헤더로 들어오는 경우 API Gateway가 해당 데이터를 자동으로 추출해서 Lambda로 전송합니다.
이제 Insomnia로 Lambda에 이미지 파일을 전송해 S3에 업로드한 후 사전 서명된 URL을 받을 수 있는지 테스트합니다. 테스트 방법은 EC2를 사용해서 S3에 파일을 업로드하는 것과 동일합니다. 다만, 엔드포인트가 공개 IP주소가 아닌
https://s2uhma6dn3.execute-api.ap-northeast-2.amazonaws.com/default/s3인 점에 주의해야 합니다.[6] RDS 삭제하기
Amazon RDS 데이터베이스를 사용하지 않으면 이를 삭제해야 추가 비용이 발생하지 않습니다. 나중에 사용할 수 있도록 데이터를 저장하려면 DB 인스턴스의 최종 스냅샷을 만듭니다. RDS DB 인스턴스가 삭제되면 데이터를 복구할 수 없으므로 데이터가 더 이상 필요하지 않은 경우에만 삭제합니다. DB 인스턴스를 삭제하면 이와 연결된 자동화된 백업, 읽기 복제본 및 DB 매개변수 그룹도 삭제됩니다. 인스턴스를 삭제하는 단계는 다음과 같습니다.
RDS는 실수로 인해 중요한 데이터가 삭제되는 것을 막기 위해 기본적으로 삭제 방지가 활성화되어 있습니다. 따라서 가장 먼저 '삭제 방지 활성화'를 해제합니다.
해당 변경 사항을 적용할 수 있는 시간을 예약할 수도 있습니다. 여기에서는 즉시 적용하기 위해 [클러스터 수정] 버튼을 클릭하면 데이터베이스의 삭제 가능 상태가 됩니다.
리더/라이터 인스턴스를 삭제해야 클러스터를 삭제할 수 있기 때문에 각 인스턴스를 먼저 삭제합니다. 인스턴스를 삭제하는 데는 약간의 시간이 소요됩니다. 하지만 인스턴스가 완전히 삭제되길 기다릴 필요 없이 인스턴스가 삭제 중이더라도 클러스터를 삭제할 수 있습니다. 삭제 과정은 다음과 같습니다.
RDS 콘솔에서 DB 인스턴스를 선택하고, 필요 시 [작업]-[스냅샷 만들기]를 선택합니다.
DB 인스턴스에서 먼저 삭제해야 하는 읽기 복제본이 없는지 확인합니다. 읽기 복제본이 있는 경우는 해당 복제본을 먼저 삭제합니다.
RDS 콘솔에서 삭제할 DB 인스턴스를 선택하고, [작업]-[삭제]를 선택합니다.
최종 스냅샷의 생성 여부를 선택합니다(1단계에서 아직 생성하지 않은 경우). 데이터가 더 이상 필요하지 않은 경우 스냅샷을 생성하지 않도록 선택할 수 있습니다.
DB 인스턴스가 삭제된 후 자동 백업 비용이 청구되지 않도록 백업을 비활성화합니다. [수정]-[백업]으로 이동해 백업 보존 기간을 0일로 설정합니다.
페이지 하단에서 [삭제] 버튼을 클릭합니다.
삭제되는 동안 DB 인스턴스는 '삭제 중' 상태로 표시됩니다. 삭제가 완료되면 DB 인스턴스는 RDS 콘솔에서 사라집니다.
요약
RDS와 S3를 활용해 데이터를 안전하고 효율적으로 저장·관리할 수 있습니다.
RDS를 통해 관리형 관계형 데이터베이스를 쉽게 구축하고, S3 버킷을 이용해 대용량 파일 및 객체 데이터를 저장할 수 있습니다.
IAM 역할과 정책을 활용하면 EC2, Lambda 등 다양한 AWS 서비스가 데이터베이스와 스토리지에 안전하게 접근할 수 있습니다.
퀴즈
문제 1
RDS 인스턴스 생성 시 반드시 설정해야 하는 요소로 올바르지 않은 것은 무엇인가요?
A. DB 엔진 유형(예: MySQL)
B. 마스터 사용자 이름과 암호
C. 퍼블릭 액세스 허용 여부
D. EC2 인스턴스의 SSH 키 페어
정답: D
해설: SSH 키 페어는 EC2 인스턴스 접속에 사용되며, RDS 인스턴스 생성과는 무관합니다.
문제 2
S3 버킷에서 외부 사용자가 특정 파일에 일시적으로 접근할 수 있도록 하는 최적의 방법은 무엇인가요?
A. 버킷 정책에 모든 사용자에게 읽기 권한 부여
B. 미리 서명된 URL(Presigned URL) 생성
C. IAM 사용자 계정을 공유
D. 퍼블릭 액세스 차단 해제
정답: B
해설: 미리 서명된 URL은 시간 제한이 있는 안전한 접근을 제공하며, 버킷 전체 공개보다 보안성이 우수합니다.
문제 3
EC2 인스턴스가 RDS에 접근할 때 필요한 설정으로 옳은 것은 무엇인가요?
A. RDS 보안 그룹 인바운드 규칙에 EC2의 프라이빗 IP 허용
B. RDS와 EC2를 다른 가용 영역에 배치
C. RDS 퍼블릭 엔드포인트를 반드시 사용
D. IAM 역할 없이 루트 계정으로 접속
정답: A
해설: 동일 VPC 내에서 RDS 보안 그룹이 EC2의 트래픽을 허용해야 합니다.
문제 4
다음 중 S3 버킷과 객체에 대한 접근 제어 메커니즘으로 옳지 않은 것은 무엇인가요?
A. 버킷 정책(Bucket Policy)
B. 접근 제어 목록(ACL)
C. 네트워크 ACL(Network ACL)
D. IAM 정책
정답: C
해설: 네트워크 ACL은 서브넷 수준의 트래픽 제어에 사용되며, S3 객체 접근 제어와는 무관합니다.
문제 5
Lambda 함수가 S3 버킷에 접근하기 위해 필요한 권한 부여 방법으로 올바른 것은 무엇인가요?
A. Lambda 실행 역할에 AmazonS3FullAccess 정책 연결
B. S3 버킷을 퍼블릭으로 설정
C. EC2 키 페어를 Lambda에 복사
D. RDS 파라미터 그룹 수정
정답: A
해설: 최소 권한 원칙에 따라 필요한 S3 작업만 허용하는 정책을 역할에 연결하는 것이 권장됩니다.
6장 CI/CD 파이프라인
소프트웨어를 빠르게 개발하는 것도 중요하지만, 개발한 코드의 무결성을 검증하고 프로덕션 환경에 빠르게 배포하는 것도 매우 중요합니다. 현대의 소프트웨어 개발에서는 이러한 과정을 모두 자동화해서 개발자는 코드 개발에만 전념할 수 있는 환경을 만들기 위해 노력하고 있습니다.
6장에서는 소프트웨어 개발과 배포의 자동화를 실현하는 CI/CD(Continuous Integration/Continuous Delivery) 파이프라인을 AWS에서 구현하는 방법을 학습합니다. Git을 활용한 소스 코드 버전 관리, CodePipeline·CodeBuild·CodeDeploy 등 AWS의 주요 CI/CD 서비스의 역할과 연동 구조, ECS·Lambda 등 다양한 배포 환경에서의 자동화된 빌드 및 배포 과정을 단계별로 실습합니다. Blue/Green 배포, 롤백, IAM 권한 관리, 환경 변수 설정 등 실무에 필수적인 CI/CD 운영 노하우를 익혀, 개발에서 배포까지의 전체 흐름을 실제로 경험할 수 있습니다.
[1] Git과 CI/CD의 기능
Git의 개념
Git은 소스 코드 관리에 사용되는 분산 버전 관리 시스템입니다. Git을 사용하면 여러 개발자들이 동시에 코드를 수정할 수 있고, 각각의 변경 사항을 반영한 다른 버전의 코드를 유지할 수 있습니다. 따라서 대부분의 현대적인 소프트웨어 개발에서는 Git을 사용합니다. 이렇게 Git으로 관리되는 프로젝트 폴더 또는 코드베이스를 깃 레포지토리(줄여서 깃 레포) 또는 깃 저장소라고 부릅니다.
Git은 다른 사람들과의 협업을 위해 사용하는 프로그램이기 때문에 로컬 환경에서만 깃을 사용하는 것은 큰 의미가 없을 수 있습니다. 따라서 여러 사람이 함께 코드 변경 사항을 업로드하고 다운로드 받을 수 있는 원격 서버가 필요합니다. 요즘에는 이러한 원격 서버를 서비스 형태로 제공되는 경우가 많습니다. 대표적인 깃 저장소 서비스는 다음과 같습니다.
GitHub는 가장 크고 가장 인기 있는 Git 레포지토리 호스팅 서비스로, 무료 계정으로 사용할 수 있는 공개 레포지토리와 팀을 위한 고급 협업 기능을 제공합니다.
GitLab은 회사 내부 프로젝트에 적합한 무료 티어에서 무제한 비공개 레포지토리와 CI/CD 파이프라인을 제공하는 오픈 코어 Git 레포지토리 관리자입니다.
Atlassian의 Bitbucket은 최대 5명의 사용자로 구성된 소규모 팀에게 무제한 비공개 Git 레포지토리를 무료로 제공하며, Jira와 같은 다른 Atlassian 서비스와 긴밀하게 통합됩니다.
AWS CodeCommit은 확장성이 뛰어나고 안전한 Git 레포지토리 호스팅 서비스로, Amazon Web Services에서 완전히 관리하며 다른 AWS 제품과 원활하게 통합됩니다.
Gerrit은 코드 리뷰 워크플로우를 위해 특별히 구축된 오픈 소스 Git 레포지토리 관리 솔루션으로, 세분화된 액세스 제어, 코드 리뷰 도구 및 Jenkins와의 통합을 제공합니다.
이 책에서는 Git을 사용해 코드를 저장할 곳으로 가장 유명하고 많이 사용되는 서비스인 GitHub를 이용합니다.
TIP: 왜 GitHub인가?
방대한 에코시스템과 오픈 소스 커뮤니티 : 최대 규모의 개발자 커뮤니티는 통합, 학습 리소스, 기여자 및 협업 플랫폼에 대한 전반적인 추진력을 높여줍니다.
협업에 적합한 기능 : GitHub는 코드 리뷰, 작업 추적, @멘션, 위키 및 기타 기능을 통해 팀 협업을 지원하여 그룹이 효율적으로 코드를 함께 작업할 수 있도록 돕습니다.
강력한 확장 및 통합 : GitHub는 모든 것을 혼자서 처리하려고 하지 않고 앱, 작업 및 강력한 API를 통해 개발자가 사용하는 다른 도구와의 사용자 지정 및 연결을 강화합니다. 이러한 유연성이 핵심입니다.
CI(Continuous Integration)의 개념
지속적 통합(CI)은 개발자가 코드의 변경 사항을 저장소에 푸시할 때마다 자동으로 테스트를 실행하고 빌드를 수행하는 프로세스입니다. CI의 목표는 코드 변경 사항이 생길 때마다 빌드와 테스트를 자동으로 실행해서 그에 대한 피드백을 개발자에게 제공합니다. 만일, 빌드와 테스트에 문제가 없으면 해당 변경 사항은 저장소의 메인 브랜치에 머지되게 됩니다.
프로젝트에 CI가 설정되어 있으면 새로운 코드에 대한 문제점을 빠르게 발견할 수 있습니다. 특히 포맷이나 린팅 같은 스타일 문제도 검사하기 때문에 코드 품질을 높게 유지할 수 있다는 장점이 있습니다.
CD(Continuous Delivery/Deployment)의 개념
지속적 배포(CD)는 CI에서 한 단계 더 나아가 변경 사항을 프로덕션 환경 또는 개발 환경에 자동으로 배포하는 것입니다. CI/CD의 목표는 코드 변경 사항을 신속하게 통합 및 배포해 전체 릴리즈 시간을 단축하고, 보다 빠른 피드백을 제공하는 것입니다.
NOTE_주요 CI/CD 도구
Jenkins: 오픈 소스 CI/CD 서버로, 다양한 플러그인을 통해 확장 가능합니다.
GitHub Actions: GitHub에서 제공하는 CI/CD 솔루션으로, GitHub 레포지토리와 긴밀하게 통합되어 있습니다.
GitLab CI/CD: GitLab에서 제공하는 CI/CD 솔루션으로, GitLab과의 통합이 뛰어납니다.
AWS CodePipeline: AWS에서 제공하는 CI/CD 서비스로, AWS 생태계와 긴밀하게 통합되어 있습니다.
Azure DevOps: Microsoft에서 제공하는 CI/CD 서비스로, Azure 클라우드와 긴밀하게 통합되어 있습니다.
[2] AWS CI/CD 파이프라인
이번 절에서는 AWS에서 제공하는 CI/CD 서비스들에 대해서 알아보겠습니다.
CodePipeline
CodePipeline은 AWS에서 제공하는 CI/CD를 위한 서비스로 여러 개의 단계Stage로 구성되어 있습니다. 또한, AWS에서 제공하는 CI/CD 관련 도구들과 외부 서비스로 하나의 전체 파이프라인을 구성합니다.
- 소스(Source) 단계 : Github, Gitlab과 같은 AWS 외부의 소스 저장소를 사용할 수 있지만 AWS 자체 서비스인 CodeCommit을 사용할 수도 있습니다. 해당 단계에서는 원하는 브랜치 또는 커밋의 소스 코드를 가져옵니다.
- 빌드(Build) 및 테스트(Test) 단계 : 소스 단계에서 가져온 소스 코드를 Codebuild 서비스를 사용해 빌드하고 테스트합니다. 이때, 빌드는 바이너리 파일을 만드는 것뿐만 아니라 Docker 이미지를 만드는 것도 가능합니다.
- 배포(Deploy) 단계 : 빌드 단계에서 만들어진 바이너리 파일이나 Docker 이미지를 배포합니다. 배포할 수 있는 대상은 다양한데 S3, Lambda, Elastic Beanstalk, ECS, EKS 등 다양한 AWS 서비스를 사용할 수 있습니다.
Codebuild
Codebuild는 AWS에서 제공하는 빌드와 테스트를 위한 서비스입니다. 자바, 파이썬 등 프로그래밍 언어를 설치해 사용할 수도 있지만 일반적으로는 도커 컨테이너를 사용해 테스트부터 빌드를 모두 진행합니다. 빌드 환경을 도커 로 구성할 때는 도커 이미지를 미리 준비해 두어야 합니다.
CodeDeploy
CodeDeploy는 빌드 결과물을 다양한 환경에 자동으로 배포하고, 배포 전략을 통해 안전하고 효율적인 배포를 지원하는 AWS 서비스입니다. CodeBuild에서 빌드된 결과물을 CodeDeploy에 연결하여 자동으로 배포할 수 있으며, Blue/Green 배포, Canary 배포 등 다양한 배포 전략을 통해 새로운 버전의 애플리케이션을 점진적으로 배포하고 문제 발생 시 빠르게 롤백할 수 있습니다. 또한, EC2 인스턴스, ECS, Lambda 등 다양한 환경에 배포를 지원하며, 배포 상태를 실시간으로 모니터링하여 문제 발생 시 빠르게 대응할 수 있습니다.
[3] ECS CI/CD 파이프라인
CI/CD 파이프라인에서 도커는 가장 필수적인 요소입니다. 어플리케이션을 업데이트할 때에는 소스 코드만 업데이트 되는 경우도 있지만 소스 코드가 실행되는 환경이 변경되는 경우도 있습니다. 예를 들어, 운영 체제의 라이브러리를 새롭게 설치하거나 환경 변수를 변경하는 등의 작업이 이에 해당합니다. EC2 인스턴스에 새로운 패키지를 설치하거나 운영체제를 변경해야 한다면 아예 새로운 인스턴스를 생성해야 하는 상황도 발생합니다. 어플리케이션을 개발하거나 운영할 때 도커를 사용하는 것처럼CI/CD에서 사용하는 서비스들에서도 도커로 환경을 구성하는 것이 일반적입니다.
이번 절에서 살펴볼 EC2의CI/CD 파이프라인은 다음과 같은 순서로 서비스를 생성하고 설정합니다.
도커 이미지를 사용하면 서버에 직접 소스 코드를 배포하는 번거로움 없이, 새로운 이미지를 빌드하여 간편하게 배포할 수 있습니다. 이는 서버 관리 부담을 줄이고 배포 속도를 향상시키는 데 큰 도움이 됩니다.
AWS ECS는 이러한 도커 이미지를 효율적으로 관리하고 배포하기 위한 고성능 컨테이너 관리 서비스입니다. ECS를 이용하면 EC2 인스턴스를 직접 관리하지 않고도 도커 컨테이너를 실행할 수 있어 운영 편의성을 높일 수 있습니다. ECS는 크게 EC2 모드와 Fargate 모드 두 가지로 나뉘는데, EC2 모드는 사용자가 직접 EC2 인스턴스를 관리해야 하지만 Fargate 모드는 AWS가 EC2 인스턴스를 자동으로 관리해 주므로 더욱 간편하게 사용할 수 있습니다. 특히, Fargate 모드는 사용한 만큼만 비용을 지불하는 서버리스 모델이기 때문에 소규모 서비스나 변동성이 큰 서비스에 적합합니다.
Github 설정
여기에서 사용하는 깃허브 저장소에는 루트 주소
/로 GET 요청을 보내면 "Hello World"를 리턴하는 FastAPI 코드와 해당 코드를 실행할 수 있도록 준비된 도커 파일이 있습니다.https://github.com/Indosaram/fastapi_sample
해당 저장소를 내 깃허브 계정으로 포크(Fork)해서 사용하겠습니다. 포크란 저장소의 현재 상태를 내 계정의 깃허브 저장소로 복사해 오는 것을 의미합니다. 깃허브에 회원가입 또는 로그인이 되어있지 않다면 회원가입 또는 로그인이 필요합니다. 저장소를 포크하려면 깃허브 저장소 우측 상단에서 다음과 같이 [Fork] 버튼을 클릭합니다.
그러면 포크해온 저장소 이름을 변경할 수 있습니다. 원하는 이름을 입력하거나 기존의 이름을 사용해도 됩니다. 이름을 결정했다면 화면 우측 하단의 [Create fork] 버튼을 클릭합니다.
이제 GitHub 쪽에서의 설정은 끝났습니다. 이 레포지토리를 AWS와 연결하기 위해서 다시 AWS 콘솔로 돌아가 작업을 계속하겠습니다.
Codebuild 생성
콘솔에서 Codebuild를 검색해 해당 서비스 페이지로 이동합니다. 그리고 프로젝트 생성 버튼을 클릭합니다.
프로젝트 구성에서 프로젝트 이름에 "my_app_build"를 입력합니다.
그 다음 소스1 - 기본에서 GitHub를 선택합니다. 처음 1회는 CodeBuild 서비스가 GitHub 계정에 접근할 수 있도록 권한을 부여해 주는 과정이 필요합니다. 새로 열린 웹 브라우저 페이지에서 다음과 같이 [Authorize aws-codebuild] 버튼을 클릭합니다.
AWS로 돌아와서 [확인] 버튼을 클릭하면 연결 처리가 완료됩니다.
레포지토리에서 '내 GitHub 계정의 레포지토리'를 선택하고, GitHub 레포지토리에서 추가하려는 레포지토리 주소를 직접 입력하거나 목록에서 선택합니다. 이전에 포크해왔던 레포지토리를 선택하면 됩니다.
커밋 웹훅(webhook)은 저장소에 새로운 커밋이 생성되었을 때 호출되어 Codebuild를 트리거할 수 있는 웹 주소입니다. 프로그램이나 브라우저로 해당 주소로 접속하면 미리 설정된 작업이 작동되는 방식을 웹훅이라고 합니다. 예전에는 웹훅을 생성해서 Codebuild를 트리거하는 것이 일반적이었지만, 주소만 있으면 누구나 빌드를 실행할 수 있다는 문제가 있습니다. 이와 같은 보안상의 이유로 현재는 안전한 OAuth 방식이 권장되고 있습니다. 우리는 이미 위에서 GitHub와 CodeBuild를 OAuth 방식으로 연결했기 때문에 별도로 웹훅을 설정할 필요는 없습니다.
AWS CodeBuild의 환경 이미지는 빌드를 실행하는데 필요한 런타임 환경과 도구를 제공하는 사전에 구성된 도커 이미지를 말합니다. 여기에는 프로그래밍 언어와 함께 AWS CLI 같은 빌드를 실행하는데 필요한 여러 가지 프로그램이 설치되어 있습니다. 환경에서는 'Ubuntu'를 운영 체제로 선택하고, 런타임은 'Standard'를 선택합니다. 이미지는 가장 최신 버전인 '7.0'을 선택하고, 이미지 버전은 '항상 최신 이미지'를 사용합니다. 지금은 CodeBuild에서 도커 이미지를 빌드하고, ECR에 푸시해야 하기 때문에 '권한이 있음'의 플래그를 체크(선택)합니다. 서비스 역할은 '새 서비스 역할'을 선택하고, 역할 이름에 "my-app-codebuild"를 입력합니다.
BuildSpec은 빌드를 수행할 때 필요한 정보를 담고 있는 파일입니다. Codebuild는 기본적으로 저장소의 루트 경로에 위치한
buildspec.yml파일을 찾아서 빌드를 수행합니다. 이전에 포크해 두었던 저장소를 살펴보면 해당 파일이 이미 존재하는 것을 알 수 있습니다. 이 파일의 내용에 대해서는 뒤에서 자세히 설명하겠습니다. 지금은Codebuild 작업이buildspec.yml파일에 정의된다는 것만 알아도 충분합니다. 저장소에 파일을 만들지 않고 Codebuild 콘솔에서 직접 파일을 입력하는 것도 가능하지만 추후 유지보수가 어렵기 때문에 권장되는 방법은 아닙니다.
그 다음으로 '추가 구성'에서 환경 변수 2개를 설정합니다.
REPOSITORY_URI는 도커 이미지를 푸시할 ECR 저장소의 이름으로 현재 저장소 주소는000000000000.dkr.ecr.ap-northeast-2.amazonaws.com/my_app입니다.AWS_ACCOUNT_ID는 AWS의 계정 아이디로000000000000와 같이 저장소 주소 맨 앞의 숫자 12자리를 의미합니다. 나머지 설정은 그대로 두고 [빌드 프로젝트 생성] 버튼을 클릭하면 빌드 프로젝트가 생성됩니다.
CodeBuild가 정상적으로 생성되었는지 확인하기 전 CodeBuild 프로젝트에 적절한 권한을 부여해야 합니다. IAM 대시보드에서 '역할'을 클릭하고, 'my-app-codebuild'를 선택합니다.
그 다음 '권한 정책' 패널에서 '권한 추가' - '정책 연결'을 클릭합니다.
여기에는 다음과 같은 권한을 추가합니다. 해당 권한은 AWS의 컨테이너 이미지 저장소인 Amazon ECR에 대한 모든 권한을 부여하는 관리형 정책입니다. 이 권한을 가진 IAM 사용자나 역할은 ECR에서 이미지를 읽고 쓰고, 저장소를 관리하고, 이미지 스캔 설정을 변경하는 등 모든 작업을 수행할 수 있습니다. 즉, ECR에 대한 완전한 접근 권한을 갖게 됩니다.
AmazonEC2ContainerRegistryFullAccess
이제 다시 Codebuild 콘솔로 돌아가서 우리가 만든 프로젝트 my-app-build의 이름을 클릭해 프로젝트 내부로 이동합니다.
image-135.png
다음 우측 상단에서 '빌드 시작'을 클릭해 테스트를 진행할 수 있습니다.
위 그림의 이름에는 my-app-build로 되어 있는데.. 확인을 부탁드립니다. 그림을 추가했습니다
약 5분 정도 기다리면 다음과 같이 빌드가 정상적으로 수행된 것을 확인할 수 있습니다.
빌드가 성공하기는 했는데, 구체적으로 Codebuild에서 어떤 작업을 수행한 걸까요? 빌드 작업 내용은 모두 저장소에 위치한
buildspec.yml에 정의되어 있습니다. 해당 파일의 코드 내용은 다음과 같습니다.version: 0.2 # 빌드 스펙 버전 phases: # 빌드 단계 install: # 설치 단계 runtime-versions: # 런타임 버전으로 여기서는 파이썬 버전을 의미함 python: 3.11 commands: # 런타임 설치 명령어 - pip install -r requirements.txt pre_build: # 빌드 전 단계로 여기서는 테스트를 수행함 commands: - pytest test_main.py # pytest를 사용해 test_main.py 파일을 실행함 build: # 빌드 단계로 여기서는 도커 이미지를 빌드함 commands: # ECR에 로그인하고 도커 이미지를 빌드하고 푸시함 - > aws ecr get-login-password --region $AWS_DEFAULT_REGION | docker login --username AWS --password-stdin $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com - docker build -t $REPOSITORY_URI:latest . - docker push $REPOSITORY_URI:latest artifacts: # 빌드 결과물로 여기서는 도커 이미지를 사용하기 때문에 생략 files: - "**/*" discard-paths: no이처럼 빌드 작업을 파일 형태로 관리하게 되면, 빌드 프로세스를 명확하게 정의하고 재현 가능하게 만들 수 있습니다. buildspec.yml 파일은 빌드 환경 설정, 빌드 단계, 테스트, 배포 등 빌드의 모든 과정을 YAML 형식으로 상세하게 기술하여, 팀 내 개발자들이 빌드 과정을 쉽게 이해하고 공유할 수 있도록 돕습니다. 또한, 버전 관리 시스템에 함께 관리하여 빌드 변경 이력을 추적하고, 필요에 따라 이전 버전의 빌드를 복원하는 것도 가능합니다. 이를 통해 빌드 프로세스의 투명성을 높이고, 빌드 실패 시 문제를 빠르게 진단하고 해결할 수 있습니다.
NOTE: YAML형식이란?
YAML(YAML Ain't Markup Language)은 데이터를 저장하거나 설정 파일을 작성할 때 사용하는 간단한 포맷입니다. 사람이 읽고 쓰기 쉽게 설계되었으며, 들여쓰기를 사용해 계층 구조를 나타내는 것이 특징입니다. 키-값 쌍으로 데이터를 표현하며, JSON과 유사하지만 더 가독성이 좋고 간결합니다. 예를 들어, JSON에서 중괄호와 콜론을 사용해 데이터를 표현하는 대신, YAML은 공백과 콜론 뒤에 값을 배치해 좀 더 직관적인 구조를 제공합니다. 이를 통해 복잡한 설정 파일이나 데이터 구조를 쉽게 관리할 수 있습니다.
ECS 클러스터와 로드 밸런서 생성
<인터넷에서 가져온 그림이라 재작성 필요>
그린-블루 배포는 소프트웨어 개발 시 업데이트를 배포할 때 자주 사용되는 전략입니다. 블루 환경에서는 애플리케이션의 현재 버전을 실행하고, 그린 환경에서는 새 버전을 실행하는 두 개의 동일한 환경이 포함됩니다. 배포하는 동안 사용자 트래픽은 블루 환경에서 그린 환경으로 점진적으로 이동합니다. 이러한 접근 방식은 애플리케이션의 가용성을 높이고, 새 버전에 문제가 발생할 경우 쉽게 롤백할 수 있도록 해 배포의 위험을 줄입니다. 그린 환경에서의 새 버전이 철저한 테스트를 거쳐 안정적인 것으로 확인되면 모든 애플리케이션 트래픽이 그린 환경으로 이동합니다. 그런 다음 블루 환경은 잠재적인 롤백을 위해 대기 상태로 유지하거나 프로덕션에서 제거해 다음 업데이트를 위한 템플릿이 되도록 준비할 수 있습니다. 이번에는 ECS 클러스터를 생성하는 방법과 ECS 클러스터에 CodeBuild로부터 생성된 새로운 도커 이미지를 그린-블루 배포 방식을 사용해 배포하는 방법을 알아보겠습니다.
먼저 ECS 클러스터를 생성합니다. Elastic Container Service 대시보드로 이동한 다음 [클러스터 생성] 버튼을 클릭합니다.
콘솔에서 클러스터 이름에 "my-app-cluster"를 입력하면 네임스페이스는 자동으로 같은 이름으로 설정됩니다. 클러스터 이름은 클러스터를 고유하게 식별하는 문자열이며, 네임스페이스는 클러스터 내에서 서비스 간의 논리적인 구분을 위한 공간입니다. 기본적으로 클러스터 이름과 네임스페이스는 동일하게 설정되지만, 필요에 따라 다르게 설정할 수 있습니다. 네임스페이스를 사용하면 하나의 클러스터 내에 다양한 프로젝트를 구분하여 관리할 수 있다는 장점이 있습니다.
ECS는 실행할 수 있는 백엔드로 Fargate 또는 EC2 인스턴스를 선택할 수 있습니다. 여기에서는 'AWS Fargate'를 선택합니다.
클러스터 생성에는 3~5분 정도가 소요됩니다. 클러스터가 생성되는 동안 화면 좌측 메뉴에서 [태스크 정의]를 선택해 태스크 정의 페이지로 이동한 다음 [새 태스크 정의 생성] 버튼을 클릭합니다. 태스크는 실행 중인 컨테이너의 집합체입니다. 쉽게 말해, 하나의 애플리케이션을 구성하는 여러 컨테이너를 하나의 단위로 묶어서 관리하는 것을 태스크라고 생각하면 됩니다. 예를 들어, 웹 애플리케이션을 구성하는 웹 서버 컨테이너, 데이터베이스 컨테이너 등을 하나의 태스크로 묶어서 실행할 수 있습니다. 태스크는 특정 작업을 수행하기 위해 필요한 모든 컨테이너를 포함하며, 이러한 컨테이너들은 서로 통신하고 협력하여 애플리케이션을 구동합니다.
태스크 정의 패밀리는 추후 ECS에서 사용할 작업의 이름입니다. 여기에서는 "my-app-task"로 입력합니다.
인프라 요구 사항은 태스크가 실행될 도커 컨테이너의 리소스를 의미합니다. Fargate를 시작 유형으로 운영 체제와 아키텍처는 Linux/X86_64로 선택합니다. 태스크 크기는 .5 vCPU와 1GB 메모리를 선택합니다. 태스크 크기가 커지면 비용 역시 늘어나기 때문에 태스크에 알맞은 크기를 설정하는 것이 중요합니다. 태스크 역할은 비워두면 되는데, 추후 다른 태스크를 만들 때 해당 태스크가 S3이나 RDS와 같은 다른 AWS 서비스에 접근해 작업하는 경우 적절한 역할 권한을 생성하고, 여기에서 역할을 부여해 줍니다. 태스크 실행 역할은 ECS가 직접 새로운 역할을 생성하도록 합니다. Amazon ECS에서 태스크 역할과 태스크 실행 역할은 모두 중요하지만 서로 다른 용도로 사용됩니다.
태스크 역할 : ECS 작업 컨테이너에서 실행되는 애플리케이션 코드에
사용됩니다. 이를 통해 태스크의 컨테이너가 컨테이너 내부에서 AWS 자격 증명을 사용하지 않고도 AWS API를 호출하기 위한 IAM 역할을 맡을 수 있습니다. 즉, 컨테이너 내부의 애플리케이션이 Amazon SNS에 알림을 보내거나 S3 버킷에 액세스하는 등 다른 AWS 서비스에 액세스할 수 있습니다. 작업 역할은 'ecs-tasks.amazonaws.com' 서비스와의 신뢰 관계를 포함합니다.
태스크 실행 역할 : ECS 서비스의 ECR에서 이미지를 가져오고
컨테이너 로그를 CloudWatch로 보내는 등의 작업을 수행합니다. 사용자를 대신해 AWS API 호출을 수행할 수 있는 권한을 Amazon ECS 컨테이너 및 Fargate 에이전트에 부여합니다. ECS 에이전트는 ECS 클러스터의 작업과 모든 오버헤드를 관리합니다. 실행 역할은 ECS 작업의 작업 정의에서 찾을 수 있습니다.
결론적으로 태스크 역할은 컨테이너가 AWS API를 호출할 수 있도록 허용하는 반면, 태스크 실행 역할은 태스크가 다른 AWS 서비스에 액세스할 수 있도록 허용합니다.
다음으로는 컨테이너를 생성하기 위해 컨테이너 이미지를 설정합니다. 이름은 "my-app"으로 이미지 URI는 ECR 저장소에 저장된 이미지의 URI를 선택합니다. CodeBuild에서 도커 이미지를 빌드하고, 푸시하도록 되어 있는 URI를 사용하면 됩니다. 그리고 컨테이너 포트에는 현재 FastAPI 앱이 사용중인 8000번 포트를 입력합니다.
나머지 설정은 기본값으로 두고 [생성] 버튼을 클릭하면 태스크가 생성됩니다. 태스크가 만들어진 다음에는 태스크 세부 페이지에서 [JSON] 탭으로 이동해 작업 정의 파일을 다운로드 받습니다. 다운로드 받은 파일 이름을
taskdef.json으로 바꾸고 레포지토리에 있는taskdef.json파일에 덮어씁니다. 만일, json 파일에 'tags' 필드가 있다면 해당 라인을 삭제합니다. 그 다음 새로운 커밋을 만들고 푸시해 두면 됩니다.
이제 해당 태스크를 기반으로 방금 만들었던 클러스터에 서비스를 생성해 보겠습니다. 방금 생성한 태스크를 선택한 다음, 우측 상단에서 [배포]-[서비스 생성]을 선택합니다.
배포 구성에서 태스크 정의는 방금 생성한 태스크 [my-app-task]를 선택합니다.
서비스 이름에 "my-app-service"를 입력합니다.
빨간 글자에 해당하는 그림이 있었으면 좋겠습니다.
원하는 태스크는 1로 설정합니다.
배포 옵션을 클릭해서 열어보면 배포 유형을 선택할 수 있습니다. 배포 유형을 '블루/그린 배포'로 선택합니다. 그런데 하단에 "CodeDeploy의 서비스 역할"을 입력하도록 되어 있습니다. 아직 CodeDeploy와 ECS를 연결하는 서비스 역할이 존재하지 않기 때문에 IAM에서 새로운 역할을 생성하겠습니다.
IAM 콘솔의 "역할" 메뉴에서 "역할 생성" 버튼을 눌러 새로운 역할을 생성하고, 다음과 같이 사용 사례를 'CodeDeploy -- ECS'로 선택합니다.
권한은 'AWSCodeDeployRoleForECS'가 자동으로 선택됩니다. AWSCodeDeployRoleForECS는 AWS CodeDeploy 서비스가 사용자를 대신하여 ECS 블루/그린 배포를 수행하는 데 필요한 광범위한 권한을 제공하는 AWS 관리형 정책입니다. 이 정책은 CodeDeploy에게 S3 객체 읽기, Lambda 함수 호출, SNS 주제 게시, ECS 서비스 업데이트와 같은 지원 서비스에 대한 전체 액세스 권한을 부여하며, ECS 서비스 설명, 작업 세트 생성 및 관리, Elastic Load Balancing 리소스 조작, CloudWatch 경보 설명 등 ECS 블루/그린 배포에 필요한 다양한 작업을 수행할 수 있도록 합니다.
그리고 역할 세부 정보에서 역할 이름에 "ecs-codedeploy-role"를 입력합니다.
다시 서비스 생성으로 돌아와서 서비스 역할에 방금 생성된 역할의 ARN을 복사해서 붙여넣기 합니다.
네트워킹은 기존 EC2 인스턴스에서 설정한 것과 동일한 VPC, 서브넷, 보안 그룹을 선택하면 됩니다.
로드 밸런싱에서 그린과 블루 각각에 트래픽을 나눠서 전달해줄 Application Load Balancer를 추가합니다. 로드 밸런서 이름은 my-app-load-balancer입니다.
NOTE: ECS 로드 밸런서의 종류
유형 프로토콜 주요 기능 주요 사용 시나리오 ALB HTTP, HTTPS 컨텐츠 기반 라우팅, 쿠키 기반 웹 애플리케이션, HTTP 기반 서비스 스티킹, SSL 터미네이션 NLB TCP, UDP 낮은 지연 시간, 높은 처리량 고성능 네트워킹 서비스, TCP 기반 서비스 GLB HTTP, HTTPS API Gateway와 통합, 서버리스 서버리스 아키텍처, API Gateway와 연동된 서비스 애플리케이션 리스너에서 로드 밸런서가 연결할 포트 번호로 8000번을 설정합니다. 프로토콜은 HTTP로 유지합니다.
대상 그룹은 각각 배포가 실행될 그룹을 의미합니다. 그룹은 각자의 배포 버전을 가지고 있어서, 모든 대상 그룹이 같은 버전을 사용할 수도, 서로 다른 버전을 사용할 수도 있습니다. 그린-블루 배포 방식에서는 두 개의 그룹이 처음에 만들어지고 평상시에는 두 개의 그룹이 모두 같은 버전의 그린 배포를 실행하고 있습니다. 나중에 새로운 버전이 생기면 두 그룹 중 하나를 블루 배포로 변경해 새로운 버전을 배포합니다. 여기에서는 각 대상 그룹 이름에 "my-app-group-1"과 "my-app-group-2"를 입력합니다.
모든 설정이 마무리되면 [생성] 버튼을 클릭합니다. 그 결과 서비스가 생성되고 즉시 배포가 실행됩니다. 서비스 배포에는 약 15분 정도 소요됩니다. 서비스 생성 시 배포 방법을 반드시 'Blue green deployment'로 선택해야 합니다. 여기에서 롤링 업데이트 방식을 선택하는 경우 추후 CodeDeploy에서 다음과 같은 오류가 발생할 수 있으니 주의합니다.
EC2 대시보드로 이동해 로드 밸런서 가중치를 변경해야 합니다. EC2 대시보드 좌측 메뉴의 "로드 밸런싱" - "로드 밸런서"를 클릭합니다.
그 다음, 생성한 로드 밸런서 목록에서 방금 생성한 리스너를 클릭해 상세 페이지로 이동합니다. 그리고 하단의 [리스너 관리]-[리스너 편집]을 선택합니다.
대상 그룹의 가중치는 그룹 1이 '100%', 그룹 2는 '0%'가 되도록 수정합니다. 이렇게 하면 초기 배포 시 모든 컨테이너가 그룹1에 속하게 되고 따라서 모두 같은 버전을 사용할 수 있게 됩니다. 정리하자면 특정 시점에 하나의 버전만 서비스에 노출시키기 위한 전략입니다.
CodeDeploy 생성
로드 밸런서 서비스가 생성 완료되면 CodeDeploy로 이동해 새로운 배포 애플리케이션을 생성합니다.
애플리케이션 구성에서 다음과 같이 이름과 컴퓨팅 플랫폼을 설정하고, [애플리케이션 생성] 버튼을 클릭합니다.
배포 그룹은 서비스가 배포될 대상으로 배포 그룹 이름에 "my-app-deploy-group"을 입력하고, 서비스 역할은 이전에 생성한 ecs-codedeploy-role의 ARN을 입력합니다.
환경 구성은 이전에 생성했던 ECS 클러스터와 서비스 이름을 선택합니다.
로드 밸런서의 구성은 다음과 같이 설정합니다.
배포 설정에서는 기존 태스크를 종료하기 전에 대기할 시간을 지정할 수 있습니다. 태스크에서 어떤 작업을 하는 중이거나 태스크를 종료하기 전 정리해야 하는 작업들이 있는 경우 유용한 설정입니다. 대기 시간의 기본값은 1시간인데 빠른 배포를 위해 5분으로 설정하겠습니다. 이제 새로운 버전이 나오게 되면 이전 버전의 그룹은5분 후에 삭제될 것입니다.
이제 배포 그룹이 생성되었습니다. GitHub에서 새로운 커밋이 업로드되면 이에 해당하는 도커 이미지가 빌드될 것이고, 그린/블루 배포를 통해 ECS 클러스터의 인스턴스가 자동으로 업데이트될 것입니다.
CodePipeline 생성
CodePipeline으로 Github - CodeBuild - CodeDeploy를 하나로 연결해 보겠습니다. CodePipeline 페이지에서 '파이프라인 생성' 버튼을 클릭합니다.
Step 1에서는 파이프라인에 대한 정보를 작성합니다. 먼저 파이프라인 이름을 "my-app-codepipeline"으로 입력합니다. 그러면 하단의 서비스 역할 이름도 자동으로 선택되게 됩니다. 이제 '다음' 버튼을 클릭해 Step2로 넘어갑니다.
빨간색 내용에 맞는 그림이 있었으면 좋겠습니다.
Step 2에서는 소스 코드를 어디에서 불러올지를 설정합니다. 소스 공급자 목록 중에서 GitHub(버전 2)를 선택하면 아래에 새 패널들이 나타납니다.
연결에서는 우측의 [GitHub에 연결] 버튼을 클릭합니다.
새롭게 열리는 연결 생성 페이지에서 연결 이름을 my-app-github 로 입력합니다. 그리고 우측 하단의 GitHub에 연결 버튼을 클릭합니다.
새로운 창이 하나 열리고, AWS에서 GitHub에 접근할 권한을 부여할 것인지를 물어봅니다. Authorize AWS Connector for GitHub 버튼을 클릭해 권한을 부여합니다.
그러면 다시 AWS 콘솔 페이지로 돌아오게 됩니다. 우측 하단의 연결 버튼을 누르면 GitHub 연결 과정이 끝나게 됩니다. CodePipeline 페이지에서 "연결 준비 완료" 메시지를 통해 정상적으로 연결이 되었음을 알 수 있습니다.
그 다음 레포지토리 이름을 선택하고, 하단에서 브랜치 이름을 'main'으로 선택하면 저장소의 main 브랜치에 새로운 커밋이 푸시되는 경우 파이프라인이 자동으로 동작합니다.
상세한 트리거 설정 내용은 트리거 패널에서 볼 수 있습니다. 트리거 유형과 이벤트 유형을 통해 파이프라인이 실행될 조건을 정의합니다. 필터 유형과 브랜치/태그를 사용하여 특정 브랜치나 태그에 대한 변경 사항이 발생했을 때만 파이프라인이 실행되도록 설정할 수 있습니다. 파일 경로를 지정하면 특정 파일이나 디렉토리에 변경이 있을 때만 파이프라인이 실행됩니다.
예를 들어, main 브랜치의 src/components 디렉토리에 변경 사항이 발생했을 때만 파이프라인이 실행되도록 설정하려면 다음과 같이 설정할 수 있습니다.
트리거 유형: 필터 지정
이벤트 유형: 푸시
필터 유형: 브랜치
브랜치: main
파일 경로: src/components
이렇게 설정하면, main 브랜치의 components 디렉토리에 코드를 변경하고 push하면 자동으로 파이프라인이 실행되어 빌드와 배포가 진행됩니다.
다음 단계로 넘어가기 위해 [다음] 버튼을 클릭합니다.
빌드 -- 선택 사항에서 파이프라인이 트리거되었을 때 수행할 작업을 선택해야 합니다. 빌드 공급자 밑의 드롭 메뉴를 클릭한 다음 미리 만들어둔 AWS CodeBuild 를 선택합니다.
다음으로 넘어가기 전에 프로젝트 이름을 클릭해 CodeBuild 프로젝트를 선택해야 합니다.
이제 다음 단계로 넘어가기 위해 [다음] 버튼을 클릭합니다.
Step4는 배포 스테이지 추가입니다. 배포 단계에서 중요한 점은 CodeDeploy가 아닌 Amazon ECS(Blue/Green)을 선택해야 한다는 점입니다. ECS에서 설정해놓은 그린-블루 배포를 CodeDeploy가 실제로 수행한다고 생각하면 됩니다.
그 다음은 ECS 작업 정의와 CodeDeploy AppSpec 파일을 기본으로 선택할 수 있는 SourceArtifact를 각각 선택합니다. 이는 소스 코드 루트 경로에 존재하는 해당 파일을 참조한다는 의미입니다.
지금까지의 과정을 검토하고 [생성] 버튼을 클릭하면 파이프라인이 생성됩니다. 파이프라인 목록에서 방금 생성한 my-app-codepipeline을 클릭하면 각 스텝의 수행 과정을 볼 수 있습니다. 각 스텝은 정상적으로 수행되면 파란색에서 초록색으로 바뀌게 됩니다.
실전 테스트
새로운 커밋을 만들고 푸시했을 때 CodePipeline이 자동으로 빌드되면서 테스트 및 배포까지 수행하는지 테스트해 보겠습니다. 먼저 기존 ECS 서버에 동작 중인 FastAPI 서버에 요청을 보내 보겠습니다. ECS에 요청을 보낼 주소를 찾으려면 서비스에서 my-app-service를 선택한 후 [Configuration and networking] 탭으로 이동합니다.
화면 하단의 'DNS 이름'에서 로드 밸런서로 연결되는 주소를 확인할 수 있습니다.
해당 주소 뒤에 포트 번호(8000)를 붙여서 GET 요청을 보내거나 '주소 열기'를 클릭해 8000번 포트를 "http://my-app-loadbalancer-2087195924.ap-northeast-2.elb.amazonaws.com:8000/"와 같이 추가하면 다음과 같은 응답을 받을 수 있습니다.
{ "Hello": "World" }이제 GitHub 저장소로 접속한 후
main.py파일을 선택합니다.
그러면 main.py파일의 소스 코드를 확인할 수 있습니다. 화면 우측 상단에서 연필 모양 아이콘을 클릭하면 소스 코드를 수정할 수 있습니다.
코드 내용은 다음과 같이 함수의 리턴 값이
{"Hello": "AWS"}가 되도록 수정합니다.from fastapi import FastAPI app = FastAPI() @app.get("/") def read_root(): return {"Hello": "AWS"}그리고 우측 상단의 'Commit changes...' 버튼을 클릭합니다. 그러면 새로운 커밋을 만들 수 있도록 커밋 메시지와 설명을 적는 창이 나타납니다. 지금 만든 커밋은 특별한 목적 없이 만든 커밋이기 때문에 메시지와 설명을 추가하지 않고 바로 Commit changes 버튼을 눌러 커밋을 생성하겠습니다.
이제 CodePipeline이 자동으로 실행되고 파이프라인이 성공적으로 종료되면 새로운 버전의 배포가 완료된 것입니다. 이전과 같은 FastAPI의 주소로 접속했을 때 응답으로
{"Hello": "AWS"}가 리턴되는 것을 확인할 수 있습니다.[4] Lambda CI/CD 파이프라인
Lambda의 CI/CD는 ECS와 약간 차이점이 있습니다. CodeDeploy를 사용하지 않고 CodeBuild에서 바로 Lambda를 업데이트한다는 점입니다. 원칙적으로는 CodeDeploy를 통해 함수를 업데이트하는 것이 올바르지만, 명령어 한 줄을 추가해서 업데이트가 가능하기 때문에 여기서는 간단한 방법을 소개하도록 하겠습니다.
여기에서는 다음의 깃허브 저장소를 내 깃허브 계정으로 포크(Fork)해서 사용하겠습니다.
https://github.com/Indosaram/lambda_sample
해당 저장소의 코드는 Lambda 함수를 정의한 app.py와 이미지를 빌드할 Dockerfile , 그리고 Codebuild를 위한 buildspec.yml 파일로 구성되어 있습니다. ECS와 마찬가지로 Lambda에서도 도커 이미지를 활용한 효율적인 빌드와 배포를 구성해 보겠습니다.
Codebuild 생성
콘솔에서 Codebuild를 검색해 해당 서비스 페이지로 이동합니다. 그리고 프로젝트 생성 버튼을 클릭합니다.
프로젝트 구성에서 프로젝트 이름에 "my_lambda_build"를 입력합니다.
코드를 불러올 소스 섹션에서는 방금 포크해온 Github 저장소를 선택합니다.
ECS에서 설정했던 것과 마찬가지로, 환경에서는 'Ubuntu'를 운영 체제로 선택하고, 런타임은 'Standard'를 선택합니다. 이미지는 가장 최신 버전인 '7.0'을 선택하고, 이미지 버전은 '항상 최신 이미지'를 사용합니다. 서비스 역할은 '새 서비스 역할'을 선택하고, 역할 이름에 "my-lambda-codebuild"를 입력합니다.
다음 섹션으로 넘어가기 전에, 하단의 '추가 구성'에서 환경 변수 2개를 설정합니다.
REPOSITORY_URI는 도커 이미지를 푸시할 ECR 저장소의 이름으로 현재 저장소 주소는000000000000.dkr.ecr.ap-northeast-2.amazonaws.com/my_lambda입니다.AWS_ACCOUNT_ID는 AWS의 계정 아이디로000000000000와 같이 저장소 주소 맨 앞의 숫자 12자리를 의미합니다.
Buildspec의 경우는 저장소의 루트 경로에 위치한 buildspec.yml 파일을 찾아서 빌드를 수행하도록 하겠습니다. 이전에 포크해 두었던 저장소를 살펴보면 해당 파일이 이미 존재하는 것을 알 수 있습니다.
해당 파일은 Lambda 이미지를 빌드할 수 있도록 올바르게 수정된 파일입니다. ECS와는 다르게, 설치 단계인 install과 빌드 이전에 테스트를 수행하는 단계인
pre-build가 없이 곧바로 도커 이미지 빌드로 진입하도록 되어 있습니다. 그리고 빌드를 마치고 곧바로 Lambda 함수를 업데이트하는 명령어가post_build에 정의되어 있습니다. 여기서--function-name은 Lambda 함수의 이름을 의미합니다.version: 0.2 phases: build: commands: - > aws ecr get-login-password --region $AWS_DEFAULT_REGION | docker login --username AWS --password-stdin $AWS_ACCOUNT_ID.dkr.ecr.$AWS_DEFAULT_REGION.amazonaws.com - docker build -t $REPOSITORY_URI:latest . - docker push $REPOSITORY_URI:latest post_build: commands: - aws lambda update-function-code --function-name my_lambda --image-uri $REPOSITORY_URI:latest artifacts: files: - "**/*" discard-paths: no나머지 설정은 그대로 두고 [빌드 프로젝트 생성] 버튼을 클릭하면 빌드 프로젝트가 생성됩니다.
CodeBuild가 정상적으로 생성되었는지 확인하기 전 CodeBuild 프로젝트에 적절한 권한을 부여해야 합니다. IAM 대시보드에서 '역할'을 클릭하고, 'my-lambda-codebuild'를 선택합니다.
그 다음 '권한 정책' 패널에서 '권한 추가' - '정책 연결'을 클릭합니다.
여기에는 다음과 같은 권한을 추가합니다. 해당 권한은 AWS의 컨테이너 이미지 저장소인 Amazon ECR에 대한 모든 권한을 부여하는 관리형 정책입니다. 이 권한을 가진 IAM 사용자나 역할은 ECR에서 이미지를 읽고 쓰고, 저장소를 관리하고, 이미지 스캔 설정을 변경하는 등 모든 작업을 수행할 수 있습니다. 즉, ECR에 대한 완전한 접근 권한을 갖게 됩니다.
AmazonEC2ContainerRegistryFullAccess
그리고 CodeBuild에서 Lambda 함수를 직접 업데이트할 수 있도록 인라인 정책을 하나 더 추가합니다. 페이지 우측의 [권한 추가] - [인라인 정책 생성]을 클릭합니다.
정책 편집기에서 Lambda를 검색하고 목록에서 선택합니다.
허용할 작업을 지정하기 위해 검색창에 UpdateFunctionCode를 입력하고 하단에 나타난 패널에서 "쓰기" 체크박스에 체크합니다.
그러면 아래쪽에서 다음과 같은 경고가 발생하는 것을 볼 수 있습니다. 기본값으로 "특정"이 체크되어 있는데, 이 정책으로는 Lambda 함수만을 변경할 수 있도록 한다는 의미입니다. 만일 "모두"를 체크하면 해당 계정의 모든 기능에 대한 접근 권한을 얻게 됩니다. 어차피 이 정책으로는 Lambda만을 조정할 것이기 때문에 "특정"을 선택해도 충분합니다.
그 다음 우측의 "이 계정의 모든 항목" 체크박스를 클릭하면 모든 Lambda 함수에 대한 쓰기 권한을 부여할 수 있게 됩니다. 그리고 [다음] 버튼을 클릭해 다음 단계로 이동합니다.
NOTE
"이 계정의 모든 항목"을 선택했을 때의 ARN을 자세히 살펴봅시다.
arn:aws:lambda:*:023553074824:function:*이 ARN에는 와일드카드(*)가 2개 포함되어 있는데, 앞에서부터 순서대로 리전과 함수명을 의미합니다. 예를 들어 특정 리전을 조건으로 추가하려면
arn:aws:lambda:ap-northeast-2:023553074824:function:*과 같이 할 수 있습니다. 만일 내 계정의 전체 함수가 아닌 특정 함수에만 권한을 지정하려면
arn:aws:lambda:ap-northeast-2:023553074824:function:my_lambda과 같이 하면 됩니다.
최종적으로 만들어진 권한을 검토합니다. 정책 이름으로는 codebuild-lambda-update를 입력하고, [정책 생성] 버튼을 클릭해 해당 역할에 새로운 정책을 추가합니다.
이제 다시 Codebuild 콘솔로 돌아가서 우리가 만든 프로젝트 my-lambda-build의 이름을 클릭해 프로젝트 내부로 이동합니다.
그 다음 우측 상단에서 '빌드 시작'을 클릭해 테스트를 진행할 수 있습니다.
약 1분 정도 기다리면 다음과 같이 빌드가 정상적으로 수행된 것을 확인할 수 있습니다.
역할 생성
CodeDeploy로 넘어가기 전에, 해당 서비스에서 사용할 새로운 역할을 생성하겠습니다. 콘솔에서 IAM으로 이동해 "역할" 메뉴에서 [역할 생성] 버튼을 눌러 새로운 역할을 생성합니다.
CodePipeline 생성
CodePipeline으로 Github - CodeBuild - CodeDeploy를 하나로 연결해 보겠습니다. CodePipeline 페이지에서 '파이프라인 생성' 버튼을 클릭합니다.
Step 1에서는 파이프라인 유형을 선택하는데, Build custom pipeline유형을 선택하고 '다음' 버튼을 클릭해 Step2로 넘어갑니다.
Step 2에서는 파이프라인 이름을 "my-lambda-codepipeline"으로 입력합니다. 그러면 하단의 서비스 역할 이름도 자동으로 선택되게 됩니다. 이제 '다음' 버튼을 클릭해 Step3로 넘어갑니다.
Step 3에서는 소스 코드를 어디에서 불러올지를 설정합니다. 소스 공급자 목록 중에서 GitHub(버전 2)를 선택하면 아래에 새 패널들이 나타납니다. 여기서는 ECS에서 CodePipeline을 설정할 때 만들었던 Github 연결을 재사용하는데, 만일 Github와의 연결이 설정되어 있지 않다면 6.3절을 참고하시기 바랍니다.
포크한 저장소 이름과 기본 브랜치를 선택합니다.
트리거는 모든 코드 변경 사항에 대해서 실행되도록 기본값으로 두고 [다음] 버튼을 클릭합니다.
"빌드 -- 선택 사항"에서 파이프라인이 트리거되었을 때 수행할 작업을 선택해야 합니다. 빌드 공급자 밑의 드롭다운 메뉴를 클릭한 다음, 미리 만들어둔 AWS CodeBuild 를 선택합니다. 프로젝트 이름은 이전에 생성해둔 my_lambda_build를 선택합니다. 그리고 [다음] 버튼을 클릭합니다.
Add test stage는 별다른 설정 없이 [다음] 버튼을 클릭해 넘어갑니다.
Step 6는 빌드한 도커 이미지를 배포하기 위한 설정을 하는 단계입니다. 하지만 우리는 이미 CodeBuild에서 새로운 도커 이미지를 Lambda에 적용하는 것까지 완료했기 때문에 이 단계는 건너뛸 수 있습니다. [배포 스테이지 건너뛰기]를 클릭합니다.
파이프라인 설정 내역을 검토하고 마지막으로 하단의 [파이프라인 생성] 버튼을 클릭합니다. CodePipeline 콘솔에서 방금 생성한 파이프라인의 실행 상태를 확인할 수 있습니다. 생성 시 자동으로 빌드가 시작되며 다음 그림과 같이 모두 성공하는 것을 알 수 있습니다.
NOTE: Codepipeline 템플릿
AWS CodePipeline에서 제공하는 템플릿은 사용자가 배포, 지속적 통합(CI), 자동화를 쉽게 설정할 수 있도록 미리 정의된 워크플로우입니다. 이 템플릿을 활용하면 복잡한 설정 없이 빠르게 파이프라인을 구축할 수 있습니다.
배포 카테고리에서는 Push to ECR, Deploy to ECS Fargate, Deploy to CloudFormation 템플릿을 제공합니다. Push to ECR은 새로운 컨테이너 이미지를 Amazon Elastic Container Registry(ECR)로 빌드 및 푸시하는 워크플로우이며, Deploy to ECS Fargate는 ECR에 저장된 이미지를 Amazon ECS Fargate 클러스터로 배포하는 템플릿입니다. Deploy to CloudFormation은 AWS CloudFormation 템플릿을 배포하는 자동화 프로세스입니다.
지속적 통합(CI) 카테고리에서는 코드 변경 사항을 자동으로 빌드하고 테스트하는 프로세스를 구축하는 템플릿을 제공합니다. 자동화 카테고리는 배포 및 운영 작업을 자동화하는 다양한 워크플로우를 포함하고 있습니다.
템플릿을 선택하면 해당 카테고리에 맞는 기본적인 설정이 자동으로 적용되므로, 필요에 맞게 커스터마이징하여 사용할 수 있습니다.
실전 테스트
새로운 커밋을 만들고 푸시해 보겠습니다. CodePipeline이 자동으로 빌드되면서 테스트 및 배포까지 수행하는지 테스트해 보겠습니다. 일단 현재 상태의 Lambda는 호출 시 다음과 같은 응답을 받게 됩니다. API 게이트웨이로 연결된 엔드포인트로 요청을 보내 보세요.
{ "text": "Hello from Lambda!" }이제 소스 코드의 app.py를 다음과 같이 수정한 다음, 커밋을 만들고 푸시합니다.
import json def handler(event, context): return { "statusCode": 200, "body": json.dumps({"text": "Updated message from Lambda!"}) }푸시가 완료되고 나면 CodeCommit과 CodeBuild가 자동으로 트리거됩니다. 빌드까지 완료되고 나면 다시 같은 엔드포인트로 요청을 보내 보겠습니다. 그러면 이번에는 업데이트된 메시지가 도착하는 것을 알 수 있습니다.
{ "text": "Updated message from Lambda!" }요약
CI/CD 파이프라인을 사용하면 소스 코드의 빌드, 테스트, 배포 과정을 자동화해 개발과 운영의 효율성을 높일 수 있습니다.
AWS CodePipeline, CodeBuild, CodeDeploy 등 서비스를 연계해 코드 변경부터 서비스 배포까지의 전체 흐름을 자동화할 수 있습니다.
ECS, Lambda 등 다양한 배포 환경에서 Blue/Green 배포, 롤백, IAM 권한 관리 등 실무에 필요한 CI/CD 운영 전략을 실습했습니다.
퀴즈
문제 1
CI(Continuous Integration)의 주요 목적은 무엇인가요?
A. 코드 변경 사항을 저장소에 병합할 때마다 자동으로 테스트와 빌드를 실행해 빠른 피드백을 제공한다.
B. 개발자가 직접 서버에 코드를 배포하는 과정을 단순화한다.
C. 코드 변경 사항을 수동으로 관리한다.
D. 서버의 하드웨어를 자동으로 업그레이드한다.
정답: A
해설: CI는 코드 변경 시 자동으로 빌드와 테스트를 실행하여 문제를 조기에 발견하고 빠른 피드백을 제공하는 것이 목적입니다.
문제 2
AWS CodePipeline의 주요 역할로 올바른 것은 무엇인가요?
A. 코드 저장소 역할만 한다.
B. 소스, 빌드, 배포 등 여러 단계를 연결해 전체 소프트웨어 릴리즈 과정을 자동화한다.
C. 오직 로컬 환경에서만 동작한다.
D. 데이터베이스를 자동으로 백업한다.
정답: B
해설: CodePipeline은 소스 관리, 빌드, 배포 등 여러 단계를 연결해 전체 파이프라인을 자동화합니다.
문제 3
ECS Blue/Green 배포 전략의 주요 장점은 무엇인가요?
A. 항상 최신 버전만 서비스할 수 있다.
B. 새 버전과 기존 버전을 동시에 운영하면서 트래픽을 점진적으로 전환하고, 문제 발생 시 빠르게 롤백할 수 있다.
C. 배포 시 모든 서비스가 중단된다.
D. 오직 수동 배포만 지원한다.
정답: B
해설: Blue/Green 배포는 새 버전의 안정성을 확인한 뒤 트래픽을 점진적으로 전환하고, 문제가 발생하면 즉시 이전 버전으로 롤백할 수 있어 가용성과 안정성이 높습니다.
문제 4
AWS CodeBuild에서 buildspec.yml 파일의 역할은 무엇인가요?
A. 빌드 서버의 운영체제를 관리한다.
B. 빌드, 테스트, 배포 등 빌드 프로세스의 모든 단계를 정의하는 설정 파일이다.
C. S3 버킷을 자동으로 생성한다.
D. IAM 사용자 계정을 생성한다.
정답: B
해설: buildspec.yml은 CodeBuild가 빌드 작업을 수행할 때 필요한 명령과 환경을 정의하는 핵심 설정 파일입니다.
문제 5
Lambda 함수의 CI/CD 자동화에서 CodeBuild가 Lambda 함수를 자동으로 업데이트하기 위해 추가로 필요한 IAM 권한은 무엇인가요?
A. AmazonS3FullAccess
B. Lambda 함수의 UpdateFunctionCode 작업 권한
C. RDS 데이터베이스 관리자 권한
D. EC2 인스턴스 시작 권한
정답: B
해설: CodeBuild가 Lambda 함수를 자동으로 업데이트하려면 UpdateFunctionCode 작업 권한이 필요합니다.
7장 마치며
지금까지 AWS의 주요 컴퓨팅 서비스들인 EC2, Lambda에 데이터베이스 서비스 RDS와 오브젝트 스토리지인 S3을 연결해 백엔드 서버를 배포하는 방법을 학습하고, CodePipeline을 이용해 새로운 도커 이미지를 ECS 클러스터에 자동으로 빌드하고 배포하는 과정을 살펴보았습니다. 부록에서는 주니어 개발자들이 앞으로 AWS를 계속 사용하고 공부할 때 알아두면 좋을 몇 가지 주제들을 다뤄보려고 합니다.
[1] AWS 자격증
AWS에서는 다양한 기능을 제공하고 각 서비스들을 사용하기 위해 해당 서비스에 대한 이해가 필요합니다. 하지만 서비스의 종류가 다양하고 여러 서비스들을 연결해서 사용할 때 여러 가지 구성을 올바르게 설정하는 것은 매우 어려운 일입니다. 그래서 AWS는 자격증을 통해 AWS 서비스에 대한 이해도를 측정하고, AWS 서비스를 사용하는데 필요한 기본적인 지식을 갖춘 사람들을 인증하는 공식 자격증을 운영하고 있습니다.
자격증을 따야 할까요?
결론부터 말하자면 '아니오' 입니다. 실제 현업에서 AWS를 사용하는 많은 직군들의 채용 공고를 살펴보면 퍼블릭 클라우드에서의 작업 경험을 묻거나 특정 서비스의 사용 경험이 있는지를 묻는 경우는 있어도 해당 자격증이 지원 요건에 들어가는 경우는 매우 찾아보기 어렵습니다. 예시로 대기업, 유니콘, 소규모 스타트업 세 곳의 채용 공고를 살펴보겠습니다.
쿠팡에서는 AWS 서비스 자체에 대한 능숙한 경험을 자격 요건으로 하고 있습니다. 하지만 다른 자격 요건을 살펴보면 대규모 분산 시스템을 구축하는 능력이 더욱 중요하다는 것을 알 수 있습니다. 따라서 쿠팡에서는 대규모 분산 시스템을 AWS 위에서 구축할 수만 있다면 특별한 자격증을 요구하지는 않습니다.
당근마켓 역시 '클라우드 환경에 대한 이해'라는 표현으로 해당 자격 요건을 두루뭉술하게 표현하고 있습니다.
소규모 스타트업인 클라썸의 경우에는 AWS 또는 GCP를 사용한 경험을 묻고 있습니다. 주목할 점은 선호 자격 요건에 서버리스에 대한 경험을 묻고 있다는 점입니다.
세 회사는 규모나 업력이 크게 다른 IT 기업들인데도 불구하고 채용 공고에서 AWS 또는 클라우드 관련 경험에 자격증을 명시하고 있지 않습니다. 즉. 현업에서는 자격증 유무보다는 전반적인 클라우드 사용 경험, 그리고 클라우드를 사용해 실제 문제를 해결할 수 있는 능력이 더욱 중요하다는 의미입니다. 자격증이 아닌 실제 경험과 능력을 더 중요하게 보는 경향은 비단 AWS에만 국한되지 않습니다. 많은 비전공 출신 개발자들이 정보처리기사 자격증을 따야 하는지를 묻곤 하는데, 중요한 것은 자격증을 취득했는지가 아니라 정보처리기사에서 다루고 있는 주제들에 대해 익숙하게 내용을 활용할 수 있는지입니다. 마찬가지로 AWS 자격증 역시 해당 과정에서 다루고 있는 내용은 협업에서도 매우 유용한 것들입니다. 자격증만을 위해서 공부하기 보다는 실제 업무에 어떻게 활용할 수 있을지를 고민하면서 공부하는 것을 추천합니다.
자격증의 종류
AWS 자격증은 크게 기본 자격증과 전문 자격증으로 나뉩니다. 기본 자격증은 AWS 서비스를 사용하는데 필요한 기본적인 지식을 갖춘 사람들을 대상으로 하고, 전문 자격증은 특정 분야의 전문가를 대상으로 합니다. AWS 자격증은 공통적으로 Cloud Practitioner로 시작해 각기 전문 분야로 나누어 집니다. 백엔드 개발자라면 Software Development Engineer 또는 Application Architect 중 자신에게 맞는 트랙을 선택하면 됩니다. AWS 자격증을 어떤 순서로 공부해야 하는지를 직군별로 정리해 놓은 AWS 공식 자료가 있으니 참고하시길 바랍니다.
https://d1.awsstatic.com/training-and-certification/docs/AWS_certification_paths.pdf
[2] 모니터링 도구
클라우드 시스템을 사용할 때 중요한 것 중 하나가 바로 모니터링 도구입니다. 모니터링이란 애플리케이션 또는 서버의 상태를 확인하거나 로그를 읽고 문제가 발생했을 때 원인을 분석할 수 있는 등 다양한 기능을 포함합니다. AWS에서도 다양한 사용 사례에 맞는 서비스를 제공하고 있습니다.
Cloudwatch 사용법
CloudWatch는 가장 기본적인 모니터링 서비스로 주로 상태 감시나 로깅을 위해서 사용합니다. 대부분의 서비스에 연결해서 사용할 수 있기 때문에 AWS에서 반드시 알아 두어야 하는 서비스입니다. 특히 문자, 이메일, 슬랙 알림 등 외부 서비스와 연동해서 경고(Alert)를 실시간으로 개발자에게 알릴 수 있는 기능을 내장하고 있어서 편리합니다.
Metric Explorer 리소스 모니터링
Metric Explorer는 CloudWatch의 핵심 기능 중 하나로 AWS 리소스의 성능 데이터를 시각적으로 탐색할 수 있습니다. 이를 통해 특정 시간 동안의 리소스 사용량을 확인하거나 여러 리소스 간의 성능을 비교하는 등의 작업을 수행할 수 있습니다.
서드파티 모니터링 도구
AWS에서 제공하는 서비스 이외에도 애플리케이션의 상태를 캡처해서 제공하는 트레이스나 로그 및 데이터 시각화 관련 도구 등 다양한 서드파티 모니터링 도구가 존재합니다. 업계에서는 다양한 종류의 도구들을 사용하고 있기 때문에 본인이 원하는 회사에서 사용하는 도구를 공부하는 것을 추천합니다. 대표적인 모니터링 도구를 카테고리별로 정리해보면 다음과 같습니다.
- 트레이싱 : Sentry, Jaeger, Opentelemetry
- 로깅 : Loki, Prometheus
- 시각화 도구 : 그라파나
[3] IaaS
이 책에서는 AWS 서비스를 구성할 때 콘솔을 통해 직접 설정하는 방식을 사용했습니다. 해당 방식은 클라우드를 처음 접하거나 공부할 때는 편리하지만 서비스를 지속적으로 운영할 때는 불편한 점이 있습니다. 예를 들어, 서비스를 구성하는데 사용한 설정을 다른 사람과 공유하기가 어렵고, 설정을 변경할 때마다 콘솔을 통해 직접 변경해야 하는 등의 문제가 있습니다. 이런 문제를 해결하기 위해 AWS는 IaaS(Infrastructure as a Service)를 제공합니다. IaaS는 코드를 통해 클라우드 서비스의 구성을 정의할 수 있습니다. AWS에서는 CloudFormation이라는 서비스에서 코드를 작성해 인프라를 구성할 수 있습니다. 이외에도 Terraform이나 Pulumi 같은 서드파티 IaaS도 존재합니다. 현업에서는 주로 Terraform을 사용하는 경우가 많은데, CloudFormation은 AWS 서비스만 정의할 수 있지만 Terraform은 AWS 이외에도 GCP나 Azure 같은 퍼블릭 클라우드를 사용할 때도 Terraform을 사용할 수 있습니다.